ASR | Paper reading | Tìm hiểu cách sử dụng model Whisper Speech-to-text cho các đoạn audio dài
Giới thiệu
Với sự xuất hiện của các bộ dữ liệu web có size lớn, các phương pháp huấn luyện weakly-supervised và unsupervised đã chứng minh hiệu suất ấn tượng trên nhiều tác vụ xử lý giọng nói, bao gồm speech recognition, speaker recognition, speech separation, và keyword spotting 
Whisper có cách tận dụng nguồn dữ liệu phong phú này theo 1 cách khá thông minh. Bằng cách khai thác 680,000 giờ dữ liệu huấn luyện noisy speech, bao gồm 96 ngôn ngữ khác nhau và 125,000 giờ dữ liệu dịch sang tiếng Anh, Whisper chứng minh rằng weakly supervised pretraining của một mô hình encoder-decoder transformer đơn giản có thể cải thiện đáng kể chất lượng đầu ra cho task zero-shot multilingual speech transcription trên các benchmarks hiện có.
Tuy nhiên, hầu hết các academic benchmarks lại chỉ chứa các đoạn nói ngắn, trong khi các ứng dụng thực tế thường yêu cầu biến đổi long-form audio có thể kéo dài hàng giờ hoặc phút, chẳn hạn như meetings, podcasts, và videos. Các mô hình Automatic Speech Recognition (ASR) thường được huấn luyện trên các đoạn âm thanh ngắn (30 giây trong trường hợp của Whisper) và các kiến trúc transformer đơn thuần không cho phép chuyển đổi từ đoạn speech dài sang text do bộ nhớ là hữu hạn
Các nghiên cứu gần đây sử dụng cách tiếp cận heuristic sliding window để xử lý long-form audio. Phương pháp này thường gặp vấn đề do overlapping giữa các câu hoặc các đoạn nói liên tục, dẫn đến việc một số phần của câu nói bị cắt mất hoặc trùng nhau. Điều này xảy ra khi một đoạn âm thanh dài bị chia nhỏ thành các đoạn ngắn hơn để xử lý, và có khả năng các đoạn này không khớp hoàn toàn với ranh giới tự nhiên của các từ hoặc câu.
Whisper đề xuất một phương pháp khác, gọi là buffered transcription, dựa trên accurate timestamp prediction. Cách tiếp cận này sử dụng các mốc thời gian chính xác để xác định khoảng cách dịch chuyển của cửa sổ đầu vào tiếp theo. Mục tiêu là đảm bảo rằng mỗi đoạn âm thanh mới bắt đầu ngay sau đoạn trước đó, tránh được vấn đề overlapping hoặc cắt bỏ không mong muốn.
Tuy nhiên, phương pháp buffered transcription có thể gặp vấn đề severe drifting. Điều này có nghĩa là nếu có bất kỳ lỗi nào trong việc dự đoán mốc thời gian ở một cửa sổ, lỗi này có thể tích tụ và làm lệch mốc thời gian ở các cửa sổ tiếp theo. Như vậy, những sai sót nhỏ ban đầu có thể dẫn đến những sai lệch lớn hơn trong quá trình xử lý toàn bộ đoạn âm thanh dài
Ngoài ra, việc sử dụng các heuristics thủ công để điều chỉnh mốc thời gian và cửa sổ đầu vào không mang lại độ chính xác cao. Các phương pháp này thường dựa vào các quy tắc đơn giản và có thể không linh hoạt đủ để xử lý các biến đổi phức tạp trong âm thanh thực tế.
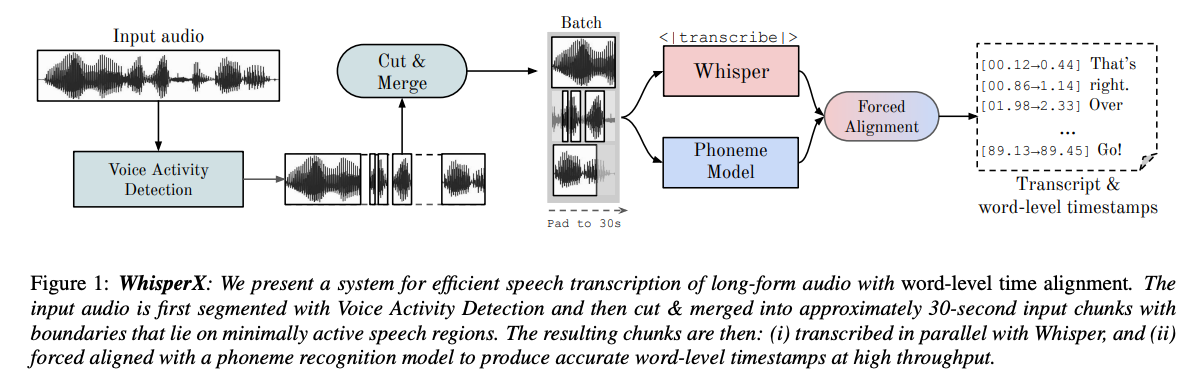
Để giải quyết những thách thức này, nhóm tác giả đề xuất WhisperX, một hệ thống cho efficient speech transcription của long-form audio với accurate word-level timestamps. WhisperX bao gồm 3 giai đoạn bổ sung cho Whisper transcription:
- Pre-segmenting input audio sử dụng một external Voice Activity Detection (VAD) model
- Cut và merge các VAD segments thành các đoạn input khoảng 30 giây với boundaries nằm trên minimally active speech regions để cho phép batched whisper transcription
- Alignment kết quả sử dụng 1 external phoneme model để cung cấp accurate word-level timestamps.
WhisperX
Voice Activity Detection
Voice Activity Detection - VAD là quá trình xác định các vùng trong đoạn âm thanh chứa giọng nói. Trong WhisperX, nhóm tác giả tiến hành phân đoạn trước âm thanh đầu vào bằng VAD. Phương pháp này mang lại 3 lợi ích sau:
- Tiết kiệm tài nguyên: VAD nhẹ hơn nhiều so với ASR và tránh được các bước xử lý không cần thiết của ASR trong các vùng không có giọng nói.
- Hạn chế lỗi câu bị cắt: Âm thanh có thể được chia thành các đoạn nhỏ với ranh giới không nằm trên các vùng có giọng nói, từ đó giảm thiểu lỗi bị cắt câu và cho phép xử lý song song.
- Hạn chế sự phụ thuộc vào timestamp của Whisper: Whisper sử dụng các timestamps để căn chỉnh giọng nói với văn bản, nhưng các timestamp này đôi khi không chính xác và có thể dẫn đến lỗi. Để khắc phục điều này, nhóm tác giả sử dụng mô hình VAD để xác định ranh giới của các đoạn giọng nói một cách chính xác hơn. Các ranh giới này sau đó được dùng để chia nhỏ âm thanh thành các đoạn nhỏ hơn và căn chỉnh các từ trong đoạn đó. Bằng cách này, ta sẽ không cần phải phụ thuộc vào các timestamp không chính xác của Whisper nữa, từ đó giảm thiểu sai sót trong quá trình căn chỉnh giọng nói và văn bản.
VAD thường được định dạng như một nhiệm vụ gán nhãn theo chuỗi, trong đó waveform đầu vào được biểu diễn như một chuỗi các vector audio feature được trích xuất theo từng thời điểm và đầu ra là một chuỗi các nhãn nhị phân , với nếu có giọng nói tại thời điểm và nếu không.
Trong thực tế, mô hình VAD () được triển khai dưới dạng một neural network. Điều này có nghĩa là mô hình sẽ nhận đầu vào là chuỗi các đặc trưng âm thanh () và tạo ra đầu ra là chuỗi các nhãn nhị phân (), trong đó mỗi giá trị nằm trong khoảng từ 0 đến 1, đại diện cho xác suất có giọng nói tại thời điểm .
Sau khi mô hình neural network dự đoán xong, ta sẽ cần thực hiện bước xử lý hậu kỳ (post process) gọi là binarize. Quá trình này bao gồm 2 giai đoạn:
- Làm mịn (smoothing): Sử dụng các onset/offset thresholds)để giảm thiểu các tín hiệu nhiễu và đảm bảo rằng chỉ các đoạn giọng nói liên tục mới được giữ lại.
- Quyết định (decision stage): Xác định minimum duration on/off để đảm bảo rằng chỉ những đoạn giọng nói đủ dài mới được coi là giọng nói thực sự.
Sau post process, các dự đoán nhị phân có thể được biểu diễn dưới dạng một chuỗi các đoạn giọng nói có trong audio ban đầu (), với mỗi đoạn có chỉ số bắt đầu và kết thúc (). Điều này cho phép xác định chính xác các phần của âm thanh có chứa giọng nói và bỏ qua các phần không có giọng nói.
VAD Cut & Merge
Active Speech Segments là các đoạn của âm thanh chứa giọng nói hoạt động. Độ dài của các đoạn này có thể rất đa dạng, không nhất thiết phải cố định. Vấn đề nằm ở chỗ, các mô hình ASR như Whisper có một giới hạn về độ dài đầu vào tối đa mà chúng có thể xử lý hiệu quả trong một lần. Nếu đoạn giọng nói dài hơn giới hạn này, mô hình sẽ không thể chuyển ngữ chính xác chỉ trong một lần xử lý.
Để giải quyết vấn đề này, nhóm tác giả đề xuất phương pháp "min-cut". Mục tiêu của phương pháp này là đặt ra một giới hạn trên về độ dài của các đoạn giọng nói để đảm bảo chúng nằm trong khả năng xử lý của mô hình ASR. Cách thực hiện là cắt các đoạn giọng nói dài tại minimum duration on/off. Điều này đảm bảo rằng các đoạn được chia nhỏ có độ dài hợp lý và không bị quá ngắn, từ đó vẫn giữ được ngữ cảnh cần thiết.
Các đoạn giọng nói được chia nhỏ sẽ nằm trong khoảng từ đến . là độ dài đầu vào tối đa trong quá trình huấn luyện của mô hình, đảm bảo rằng các đoạn giọng nói không vượt quá giới hạn này và vẫn nằm trong khả năng xử lý của mô hình.
def binarize_cut(scores, max_dur, onset_th, offset_th, TIMESTEP):
"""
scores = array of VAD scores extracted at each TIMESTEP (e.g., 0.02 seconds)
max_dur = maximum duration of ASR model
onset_th = threshold for speech onset
offset_th = threshold for speech offset
returns:
segs = array of active speech start and end
"""
segs = []
start = 0
is_active = scores[0] > offset_th
max_len = int(max_dur * TIMESTEP)
for i in range(1, len(scores)):
sc = scores[i]
if is_active:
if i - start >= max_len:
# min-cut modification
pdx = i + max_len // 2
qdx = i + max_len
min_sp = argmin(scores[pdx:qdx])
segs.append((start, pdx + min_sp))
start = pdx + min_sp
elif sc < offset_th:
segs.append((start, i))
is_active = False
else:
if sc > onset_th:
start = i
is_active = True
return segs
Giải thích code:
- Hàm
binarize_cutnhận đầu vào là các điểm số VAD (), độ dài tối đa của mô hình ASR (), ngưỡng kích hoạt giọng nói (), ngưỡng kết thúc giọng nói () và bước thời gian (). - Biến
segslưu trữ các đoạn giọng nói hoạt động với chỉ số bắt đầu và kết thúc. - Biến
is_activetheo dõi trạng thái hoạt động của giọng nói tại mỗi thời điểm. - Nếu đoạn giọng nói hoạt động kéo dài hơn độ dài tối đa, thuật toán sẽ cắt đoạn này tại điểm kích hoạt giọng nói tối thiểu trong khoảng giữa () và cuối () đoạn.
Sau khi cắt ra được các đoạn có giọng nói, chúng ta cũng cần xử lý các đoạn có độ dài quá ngắn. Việc chuyển ngữ các đoạn giọng nói ngắn không đủ ngữ cảnh có thể làm mất tính chính xác của mô hình. Vì vậy, nhóm tác giả đề xuất một thao tác "merge" để ghép các đoạn liền kề với nhau, đảm bảo rằng độ dài tổng hợp của chúng không vượt quá ngưỡng tối đa cho phép.
Whisper Transcription
Các đoạn giọng nói sau khi được chia nhỏ sẽ có độ dài xấp xỉ bằng độ dài đầu vào tối đa của mô hình (), và các ranh giới không nằm trên vùng giọng nói hoạt động. Điều này cho phép các đoạn này được chuyển ngữ hiệu quả song song với Whisper (), đầu ra là văn bản cho mỗi đoạn giọng nói ().
Nhóm tác giả lưu ý rằng quá trình chuyển ngữ song song này phải được thực hiện mà không dựa trên văn bản trước đó. Điều này có nghĩa là khi chuyển ngữ từng đoạn giọng nói, hệ thống không nên sử dụng thông tin từ các đoạn trước đó để tránh tạo ra các lỗi. Nếu phụ thuộc vào văn bản trước đó, sự phụ thuộc vào ngữ cảnh trước có thể phá vỡ sự độc lập giữa các đoạn, làm giảm tính chính xác của việc chuyển ngữ
Khi không dựa vào văn bản trước đó, hệ thống giảm thiểu được hiện tượng ảo giác (hallucination) và lặp lại (repetition) trong kết quả chuyển ngữ. Hiện tượng ảo giác xảy ra khi hệ thống "tưởng tượng" ra các từ không có trong đoạn giọng nói, còn lặp lại là khi hệ thống nhắc lại các từ không cần thiết.
Ngoài ra, nhóm tác giả cũng không sử dụng phương pháp encode timestamp của Whisper. Việc này nhằm đảm bảo độ tin cậy cao hơn trong việc chuyển ngữ, vì các mốc thời gian có thể không chính xác và gây ra lỗi trong quá trình chuyển ngữ.
Forced Phoneme Alignment
Đối với mỗi đoạn giọng nói và bản chuyển ngữ văn bản tương ứng , bao gồm một chuỗi các từ , mục tiêu của nhóm tác giả là ước tính thời gian bắt đầu và kết thúc của mỗi từ. Để đạt được điều này, nhóm tác giả sử dụng một mô hình nhận dạng âm vị (phoneme recognition model), được huấn luyện để phân loại các âm vị, là đơn vị nhỏ nhất của giọng nói, giúp phân biệt các từ khác nhau. Ví dụ, phần tử trong "tap" sẽ được phân biệt rõ ràng với các âm vị khác.
Gọi là tập hợp các lớp âm vị trong mô hình (). Khi nhận một đoạn âm thanh đầu vào, bộ phân loại âm vị sẽ lấy đoạn âm thanh () làm đầu vào và xuất ra một ma trận logits (), trong đó thay đổi tùy thuộc vào temporal resolution của mô hình âm vị. Điều này giúp xác định chính xác thời gian bắt đầu và kết thúc của các từ trong đoạn giọng nói, đảm bảo tính chính xác và chi tiết trong quá trình chuyển ngữ.
Để thực hiện căn chỉnh âm vị cho mỗi đoạn giọng nói và văn bản chuyển ngữ tương ứng , nhóm tác giả thực hiện theo các bước sau:
Đầu tiên, nhóm tác giả trích xuất tập hợp các class âm vị trong văn bản chuyển ngữ mà mô hình âm vị có thể nhận diện, ký hiệu là . Đây là bước xác định những âm vị cụ thể nào sẽ được sử dụng trong quá trình phân loại, giúp tối ưu hóa quá trình phân loại bằng cách chỉ tập trung vào các âm vị có liên quan đến văn bản cụ thể.
Tiếp theo, nhóm tác giả thực hiện phân loại âm vị trên đoạn giọng nói , giới hạn phân loại trong các lớp .
Nhóm tác giả sau đó áp dụng phương pháp Dynamic Time Warping (DTW) trên ma trận logits output để xác định các mốc thời gian tối ưu cho các âm vị trong . DTW là một kỹ thuật mạnh mẽ để căn chỉnh hai chuỗi thời gian với nhau, đảm bảo rằng các âm vị được căn chỉnh chính xác với đoạn giọng nói.
Cuối cùng, nhóm tác giả lấy thời gian bắt đầu và kết thúc cho mỗi từ trong bằng cách lấy thời gian bắt đầu của âm vị đầu tiên và thời gian kết thúc của âm vị cuối cùng trong từ đó. Điều này đảm bảo rằng toàn bộ từ được căn chỉnh chính xác trong đoạn giọng nói.
Đối với các âm vị trong văn bản chuyển ngữ không có trong từ điển của mô hình âm vị, nhóm tác giả gán timestamp từ âm vị gần nhất trong văn bản. Quy trình trên có thể được xử lý theo lô (batch processed) song song, cho phép chuyển ngữ nhanh và căn chỉnh từ-ngữ của âm thanh dài.
Multi-lingual Transcription and Alignment
WhisperX có thể áp dụng cho việc transcribe đa ngôn ngữ. Trước hết, mô hình VAD cần phải có khả năng xử lý nhiều ngôn ngữ khác nhau mà không bị ảnh hưởng bởi sự khác biệt ngôn ngữ. Điều này có nghĩa là mô hình phải đủ linh hoạt để hoạt động hiệu quả trên các ngôn ngữ chưa được huấn luyện cụ thể.
Thứ hai, mô hình căn chỉnh âm vị cần được huấn luyện trên các ngôn ngữ mà người dùng quan tâm để đảm bảo độ chính xác cao. Điều này yêu cầu mô hình nhận dạng âm vị đa ngôn ngữ có khả năng tổng quát hóa tốt, giúp mô hình có thể nhận diện và căn chỉnh âm vị chính xác ngay cả với những ngôn ngữ không xuất hiện trong quá trình huấn luyện. Để thực hiện điều này, cần có 1 cơ chế mapping từ âm vị không phụ thuộc ngôn ngữ sang âm vị của ngôn ngữ đích.
Translation
Whisper cung cấp chế độ "translate" cho phép chuyển ngữ từ nhiều ngôn ngữ sang tiếng Anh. Điều này rất hữu ích khi cần xử lý các ngôn ngữ khác nhau và chuyển chúng thành tiếng Anh để dễ dàng hiểu và sử dụng. Trong chế độ này, quá trình chuyển ngữ dựa trên VAD vẫn có thể được áp dụng, đảm bảo tính nhất quán và chính xác trong quá trình dịch.
Tuy nhiên, một hạn chế của chế độ này là không thể thực hiện căn chỉnh âm vị. Lý do là giữa giọng nói và bản dịch không còn sự tương đồng về âm thanh-ngôn ngữ. Điều này có nghĩa là không thể xác định chính xác timestamp của từng từ trong văn bản dịch, gây khó khăn trong việc căn chỉnh chi tiết giữa âm thanh và văn bản.
Word-level Timestamps without Phoneme Recognition
Nhóm tác giả nghiên cứu khả năng trích xuất timestamp ở mức word level trực tiếp từ Whisper mà không cần sử dụng mô hình âm vị bên ngoài. Mục tiêu của việc này là loại bỏ sự phức tạp liên quan đến việc ánh xạ âm vị và giảm thời gian inference. Trong quá trình nghiên cứu, nhóm tác giả nhận thấy rằng việc không sử dụng mô hình âm vị chỉ làm giảm tốc độ xử lý rất ít, chỉ khoảng dưới 10%.
Cụ thể hơn, các nghiên cứu trước đây đã thực hiện infer timestamp từ cross-attention, một kỹ thuật sử dụng sự chú ý giữa các thành phần khác nhau của mô hình để xác định timestamp. Tuy nhiên, các phương pháp này thường không đạt được độ chính xác cao như phương pháp căn chỉnh âm vị.
Tài liệu tham khảo
[1] WhisperX: Time-Accurate Speech Transcription of Long-Form Audio
All rights reserved
