Cache-Augmented Generation (CAG)
Để xây dựng một hệ thống ứng dụng Large Language Model, chắc hẳn chúng ta sẽ phải áp dụng một vài kỹ thuật để tăng cường khả năng của mô hình, điển hình nhất là sử dụng những kỹ thuật về tăng cường truy xuất RAG (Retrieval Augmented Generation). Vậy trước khi tìm hiểu về CAG, ta hãy xem qua RAG là gì, có điểm mạnh, điểm yếu là gì nhé.
RAG là gì
RAG là một kỹ thuật giúp cải thiện câu trả lời của các mô hình ngôn ngữ lớn, giảm thiểu tình trạng ảo giác (halluciation) bằng cách thêm những thông tin văn bản liên quan đến câu đầu vào từ một kho văn bản lớn bằng các kỹ thuật tìm kiếm.
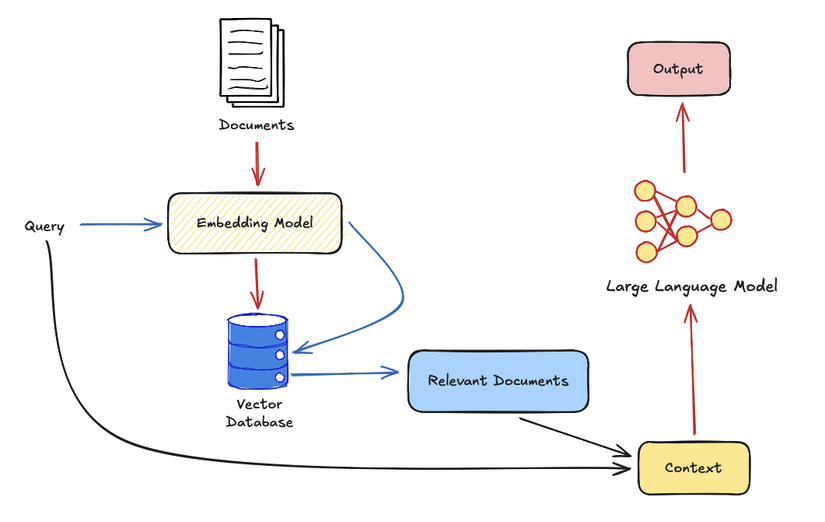
Cách thức hoạt động có thể được mô tả như sau:
-
Đầu tiên, bộ các văn bản chứa tri thức liên quan sẽ được thực hiện đánh chỉ mục (indexing) để phục vụ cho việc tìm kiếm. Trong RAG các kỹ thuật tìm kiếm dày (Dense Retrieval) thường được sử dụng do mục đích tìm kiếm phần lớn sẽ dựa trên ngữ nghĩa của văn bản (documents) và câu hỏi (query). Các mô hình dùng để biểu diễn ẩn (embedding model) văn bản sẽ được sử dụng (có thể tham khảo một vài mô hình tại mteb leaderboard), các cơ sở dữ liệu vector (vector database) cũng được sử dụng để lưu trữ và truy xuất nhanh văn bản (một vài vector database có thể tham khảo tại đây)
-
Tiếp theo, hệ thống sẽ tìm kiếm những văn bản có liên quan đến câu query của người dùng rồi sẽ thêm dữ kiện trong văn bản vào câu prompt để hỏi LLM, từ đó mô hình sẽ có khả năng hiểu biết tốt hơn và tạo ra câu trả lời tốt hơn.
Lợi ích của RAG
- Luôn có thông tin up-to-date mà không cần phải training lại
- Tăng độ chính xác cho những câu hỏi liên quan đến lĩnh vực hẹp (domain-specific)
- Có khả năng diễn giải về nguồn của câu trả lời
- Giảm thiểu tình trạng ảo giác
Điểm yếu của RAG
- Làm tăng thời gian tính toán và chi phí về lưu trữ, bảo trì
- Phụ thuộc vào chất lượng mô hình tìm kiếm
- Cài đặt khó khăn và phức tạp
CAG là gì
Với những điểm yếu đã nêu ở trên, ta cần một phương pháp hiệu quả hơn để cải thiện các thách thức của mô hình ngôn ngữ lớn. Đó là lý do CAG (Cache-Augmented Generation) ra đời. Ý tưởng cơ bản của CAG là sẽ tải trước toàn bộ văn bản vào trong extended context của model và tình toán trước giá trị key-value cache. Với cách tiếp cận này, CAG có thể đảm bảo rằng quá trình suy luận mà có phụ thuộc vào ngữ cảnh sẽ trở nên nhanh và tin cậy hơn. Vậy cụ thể CAG đã làm như nào? Ta cùng đi tìm hiểu tiếp.
CAG hoạt động như nào
Kỹ thuật "key" nhất của CAG chính là K-V Cache, vậy chúng ta hãy cùng tìm hiểu về Self-Attention và KV cache trước khi xem CAG hoạt động như nào nha.
Ôn lại về self attention
Self-attention là một kỹ thuật siêu nổi tiếng trong lĩnh vực học sâu, cốt lõi của mô hình Transformers, ông tổ của các mô hình LLM bây giờ. Kỹ thuật này cho phép mô hình có thể "tập trung" vào một vài phần trong chuỗi đầu vào trong quá trình sinh ra token kế tiếp. Ví dụ một câu: "She poured the coffee into the cup" thì mô hình sẽ có thể tập trung hơn vào từ "poured" và từ "coffee" khi sinh từ "into" tiếp theo vì các từ này cung cấp thông tin ngữ cảnh cho từ kế tiếp.
Giải thích theo góc nhìn toán học thì mục tiêu của self-attention sẽ là biến đổi token đầu vào thành context vector mà có thông tin của tất cả các token khác. Ví dụ như cụm từ "she poured coffee" thì mô hình sẽ phải tính toán ra 3 context vector tương ứng với các token (coi mỗi token là 1 từ).
Giá trị Attention sẽ được tính bằng công thức sau:
Để giải thích công thức này một cách trực quan và dễ hiểu, ta sẽ đi vào 1 ví dụ: Trong hình bên dưới khi từ "poured" được xử lý, các bước sau sẽ được thực hiện:
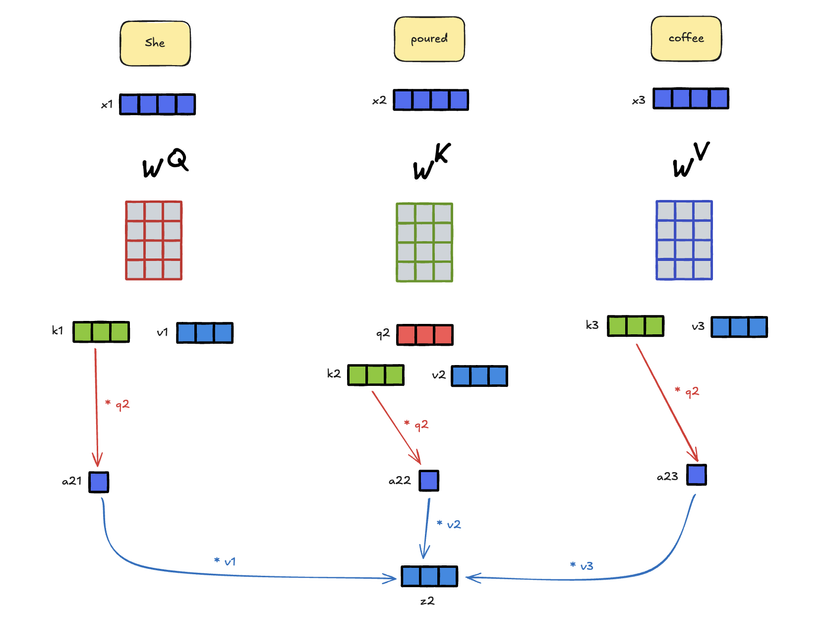
- Đầu tiên, mỗi token đầu vào sẽ được nhân độc lập với các ma trận Key và Value và để ra được giá trị ma trận và . Ngoài ra, token đang được xử lý để tìm ra context vector sẽ được nhân với ma trận . Đầu ra của bước này sẽ là các vector keys (k), values (v) với toàn bộ token trong đầu vào và vector query (q) cho token đang được xử lý. Các ma trận , , đều là trọng số mạng nơ ron được khởi tạo ngẫu nhiên và được tối ưu qua quá trình huấn luyện.
- Tiếp theo, giá trị Attention sẽ được tính toán với công thức trên, 2 vector key và query sẽ được nhân với nhau rồi được normalized để tạo ra attention weights. Trong ví dụ này, a21 là một attention weight giữa từ "she" và "poured".
- Cuối cùng, mỗi attention weight nhân với value vector tương ứng. Sau đó các vector riêng lẻ sẽ được cộng vào thành context vector z. Trong ví dụ này, z2 sẽ tương ứng với từ đầu vào x2 "poured".
Kỹ thuật KV Cache
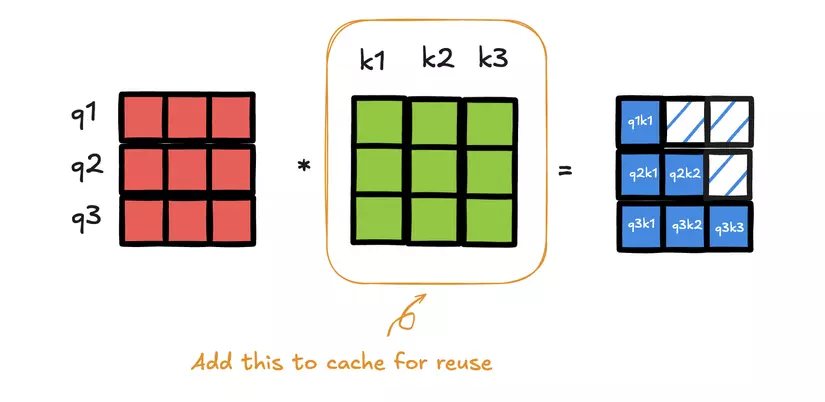
Dễ thấy với kiến trúc attention như trên thì khi tính toán context vector cho 1 token thì giá trị của ma trận K và V là không thay đổi với toàn bộ token và sẽ phải tính toán lặp lại liên tục khi xử lý các token. Điều này rõ ràng là tốn tài nguyên vô ích nên người ta đã đề xuất 1 phương pháp là tính toán trước giá trị K và V của toàn bộ token rồi lưu lại vào bộ nhớ (ram hoặc ổ đĩa) để khi cần tính toán thì chỉ cần lấy ra chứ không cần tính toán lại. Tối ưu hơn nhiều rồi phải không?
Kiến trúc của CAG
Như đã trình bày ở trên, CAG sử dụng năng lực của extented context của các long-context LLMs (Các mô hình như Gemini cho phép độ dài context khá lớn) để tích hợp tri thức bên ngoài mà không cần tìm kiếm. Bằng cách load toàn bộ tài liệu tri thức (Ví dụ các bộ văn bản ) và tính toán sẵn ky-value cache , ta có thể giải quyết các vấn đề về tính toán, văn bản rời rạc và tìm kiếm thời gian thực trong các hệ thống RAG truyền thống. CAG sẽ chia thành 3 phases chính trong hình:
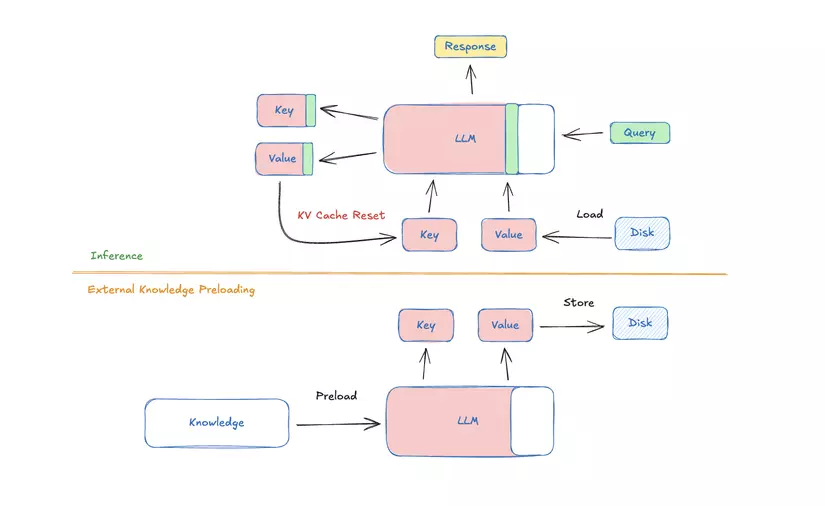
1. External Knowledge Preloading
Trong giai đoạn này, toàn bộ tập văn bản có liên quan đến ứng dụng thực thế sẽ được tiền xử lý và điều chỉnh lại để có thể vừa với context window của mô hình. Mô hình LLM , bộ tham số sẽ xử lý và biến đổi nó thành KV cache rồi được lưu trên ram hoặc đĩa để sử dụng sau. Quá trình tính này chỉ thực hiện 1 lần nênn không làm ảnh hưởng đến chi phí tính toán:
2. Inference
Trong quá trình suy luận, KV cache được tính toán trước sẽ được tải lên cùng với query của user . LLM sẽ sử dụng cache để tạo ra response:
Bằng cách preloading hết toàn bộ tri thức ngoài, quá trình này loại bỏ độ trễ của việc retrieval và giảm thiểu lỗi trong quá trình tìm kiếm. Cách này cũng như prompt kết hợp , đảm bảo rằng mô hình hiểu được cả query của user cũng như tri thức bên ngoài
3. Cache Reset
Qua các phiên làm việc, KV cache sẽ được cập nhật thêm các token trong câu hỏi của người dùng vào và lưu trữ thống nhất, tránh việc phải load cả KV cache từ ổ đĩa nhiều lần, đảm bảo tốc độ tính toán. Tuy nhiên việc này theo thời gian sẽ làm mô hình bị nhầm lẫn thông tin nên sau một vài phiên sẽ phải tái tạo lại KV cache ban đầu chỉ bằng cách loại bỏ những token đã thêm vào, đơn giản phải không:
Lợi ích và hạn chế của CAG
Lợi ích:
- Giảm thiểu thời gian tính toán
- Ngữ cảnh thống nhất, không bị phụ thuộc vào mô hình tìm kiếm, tăng cường độ chính xác
- Kiến trúc đơn giản
Hạn chế
- Bị giới hạn bởi contexts length của mô hình
- Phải thường xuyên update KV cache
- Độ dài prompt có thể bị giới hạn
- Hơi tù, không được linh hoạt như RAG
Ý kiến cá nhân
Mình thấy đây là một đề xuất cũng khá hay tuy nhiên còn nhiều câu hỏi về việc triển khai trong thực tế. Hy vọng trong tương lai sẽ có nhiều nghiên cứu hơn và giải quyết được các hạn chế của CAG
Tài liệu tham khảo
- Chan, Brian J., et al. "Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks." arXiv preprint arXiv:2412.15605 (2024).
- RAG vs CAG vs Fine-tuning: A Deep Dive into Faster, Smarter Knowledge Integration
- Transformers Key-Value Caching Explained
All rights reserved
