Cấu hình NUMA Node cho các hệ thống multiprocessors
1. Tổng quan về kiến trúc bộ nhớ NUMA
Non-Uniform Memory Access (NUMA) là một kiến trúc bộ nhớ chia sẻ được sử dụng trong các hệ thống multiprocessing. Trong đó, mỗi CPU được gán một bộ nhớ cục bộ (local memory) riêng và có thể truy cập bộ nhớ từ các CPU khác.
- Truy cập bộ nhớ cục bộ: Độ trễ thấp và băng thông cao;
- Truy cập bộ nhớ của CPU khác: Độ trễ cao hơn và băng thông thấp hơn.
1.1. Kiến trúc multiprocessors với bộ nhớ chia sẻ
Với sự ra đời của CSDL quan hệ, nhu cầu về các hệ thống có khả năng xử lý nhiều hoạt động đồng thời của User và Big Data trở nên phổ biến. Hiệu suất của bộ xử lý đơn (uniprocessor) ngày càng ấn tượng, nhưng các hệ thống multiprocessors vẫn có khả nănsg xử lý khối lượng công việc này tốt hơn.
Để tiết kiệm chi phí, các hệ thống với bộ nhớ chia sẻ (shared-memory) được nghiên cứu. Ban đầu, các hệ thống sử dụng công tắc chéo (crossbar switch), tuy nhiên, độ phức tạp của thiết kế tăng lên khi tăng số lượng bộ xử lý (processor). Khắc phục điều này bằng các hệ thống dựa trên bus (bus-based systems).
Trong hệ thống bus, các processors có thể truy cập toàn bộ không gian bộ nhớ bằng cách gửi yêu cầu qua bus, đây là một phương pháp rất tiết kiệm chi phí để sử dụng bộ nhớ sẵn có một cách tối ưu nhất.
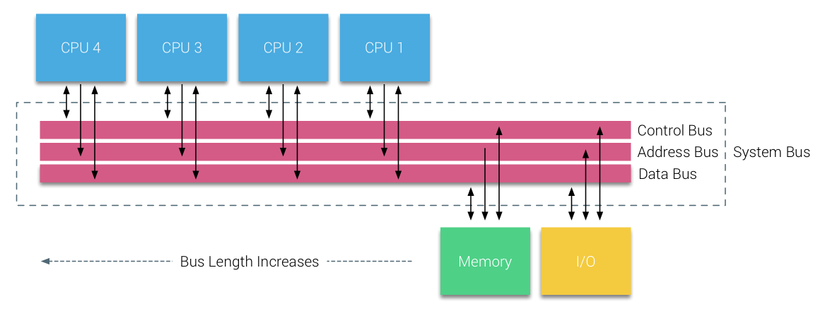
Tuy nhiên, các hệ thống bus-based cũng gặp phải vấn đề về khả năng mở rộng. Vấn đề chính là băng thông giới hạn, điều này làm hạn chế số lượng processor mà bus có thể hỗ trợ. Việc thêm CPU vào hệ thống dẫn đến hai vấn đề chính:
- Băng thông sẵn có trên mỗi node giảm khi số lượng CPU tăng lên, do tất cả processors chia sẻ cùng một bus.
- Chiều dài của bus tăng khi thêm nhiều processors, làm tăng độ trễ truy cập bộ nhớ.
1.2. Giao thức snoop cache (caching snoop protocols)
Gắn bộ nhớ đệm (cache) vào mỗi CPU giúp tăng hiệu suất theo nhiều cách. Việc đưa bộ nhớ gần hơn với CPU giúp giảm thời gian truy cập trung bình và đồng thời giảm tải băng thông trên bus bộ nhớ. Tuy nhiên, thách thức khi thêm cache vào mỗi CPU trong kiến trúc shared-memory là cho phép tồn tại nhiều bản sao của cùng một khối bộ nhớ (memory block). Đây được gọi là vấn đề nhất quán bộ nhớ đệm (cache coherency problem). Tức là, trong hệ thống multiprocessors hoặc multicores, mỗi core có cache riêng (L1, L2, L3). Nếu một core thay đổi dữ liệu trong cache của mình, nhưng các core khác vẫn giữ bản sao cũ của dữ liệu đó, sẽ xảy ra lỗi nhất quán bộ nhớ đệm.
Để giải quyết vấn đề này, mỗi cache cần theo dõi (snoop) hoạt động trên bus hệ thống để kiểm tra khi nào dữ liệu bị thay đổi hoặc đọc bởi các processors khác. Và các giao thức snoop cache tạo ra một mô hình đảm bảo dữ liệu chính xác mà không tiêu tốn toàn bộ băng thông trên bus. Giao thức phổ biến nhất là write-invalidate, trong đó tất cả các bản sao khác của dữ liệu sẽ bị xóa trước khi ghi vào cache cục bộ. Khi một processor khác cố gắng đọc dữ liệu này, nếu xảy ra cache miss (cache không chứa dữ liệu hợp lệ), nó sẽ nhận dữ liệu từ cache của CPU chứa bản cập nhật gần nhất. Mô hình này giúp tiết kiệm đáng kể băng thông trên bus và đã mở đường cho các hệ thống Uniform Memory Access (UMA).
1.3. Kiến trúc UMA
Các processors trong hệ thống bus-based multiprocessors có thời gian truy cập đồng nhất đến mọi mô-đun bộ nhớ trong hệ thống, thường được gọi là Uniform Memory Access (UMA) hoặc Symmetric Multi-Processors (SMPs).
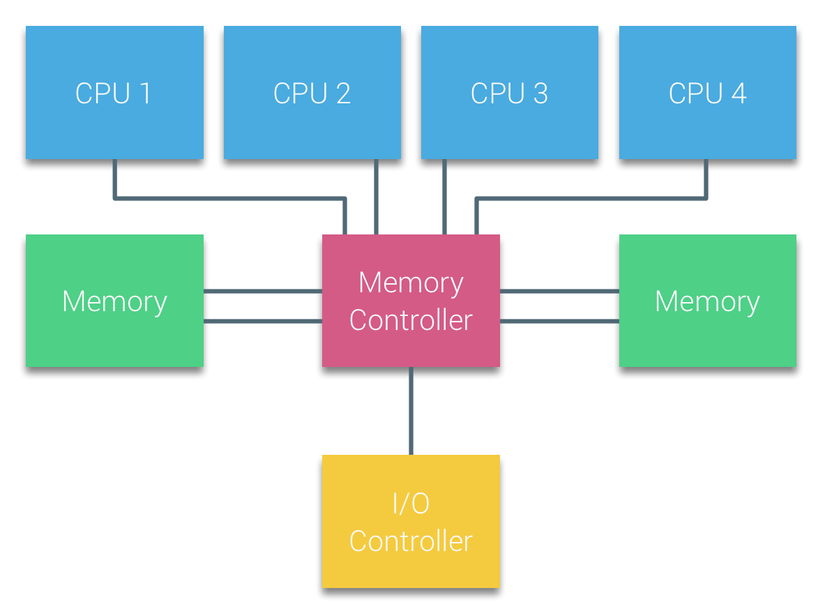
Trong các hệ thống UMA, các CPUs được kết nối thông qua bus hệ thống đến Northbridge. Northbridge chứa Memory Controller, và mọi quá trình giao tiếp với Memory đều phải đi qua Northbridge. I/O Controller, chịu trách nhiệm quản lý dữ liệu vào/ra từ tất cả các thiết bị ngoại vi, cũng được kết nối với Northbridge. Do đó, mọi thao tác I/O phải đi qua Northbridge trước khi đến CPU.
Để tăng băng thông và giảm tắc nghẽn tại Northbridge, các hệ thống sử dụng nhiều bus và kênh bộ nhớ. Một số hệ thống còn kết nối các Memory Controllers bên ngoài vào Northbridge để cải thiện băng thông và hỗ trợ nhiều bộ nhớ hơn. Tuy nhiên, do băng thông nội bộ của Northbridge có giới hạn và giao thức snoopy cache thời kỳ đầu sử dụng phương thức broadcasting (truyền phát đến tất cả CPU), UMA bị hạn chế khả năng mở rộng.
1.4. Kiến trúc NUMA
Để nâng cao khả năng mở rộng và hiệu suất, 3 thay đổi được thực hiện trong kiến trúc multiprocessors với bộ nhớ chia sẻ:
- Tổ chức bộ nhớ truy cập không đồng nhất (NUMA)
- Kết nối liên kết point-to-point
- Cơ chế duy trì nhất quán cache có khả năng mở rộng (Scalable cache coherence)
1.4.1. Tổ chức bộ nhớ truy cập không đồng nhất (NUMA)
NUMA loại bỏ mô hình bộ nhớ tập trung và giới thiệu các đặc tính liên kết theo tô-pô. Bằng cách phân loại memory dựa trên độ dài đường truyền tín hiệu từ processor đến memory, NUMA giúp tránh các bottlenecks về độ trễ và băng thông. Điều này được thực hiện bằng cách thiết kế lại hoàn toàn hệ thống processor và chipset.
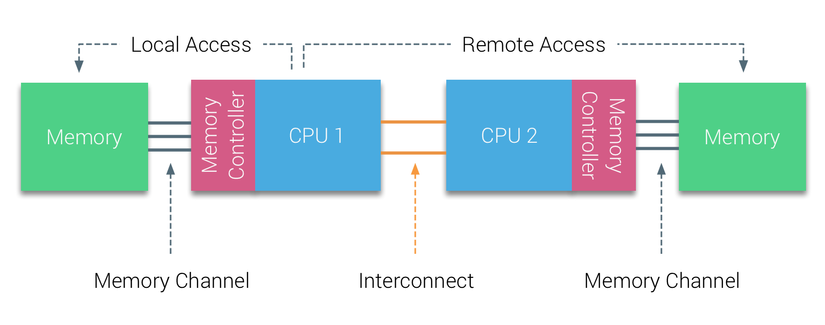
Ví dụ về hệ thống NUMA với hai CPU:
- Bộ nhớ kết nối với CPU1 được gọi là bộ nhớ cục bộ (local memory).
- Bộ nhớ kết nối với CPU2 được gọi là bộ nhớ từ xa (remote memory) đối với CPU1.
Truy cập bộ nhớ từ xa có độ trễ cao hơn so với bộ nhớ cục bộ, vì dữ liệu phải đi qua liên kết point-to-point để kết nối với Memory Controller của bộ nhớ từ xa. Do sự khác biệt trong thời gian truy cập bộ nhớ, hệ thống NUMA có đặc điểm truy cập bộ nhớ không đồng nhất (Non-Uniform Memory Access).
1.4.2. Kết nối liên kết point-to-point
AMD đã giới thiệu kết nối point-to-point HyperTransport với kiến trúc vi xử lý AMD Opteron. Intel đã từ bỏ kiến trúc dual independent bus của họ vào năm 2007 bằng cách giới thiệu Kiến trúc QuickPath trong dòng Nehalem Processor. Kiến trúc Nehalem là một sự thay đổi quan trọng trong vi kiến trúc của Intel và được coi là thế hệ thực sự đầu tiên của dòng Intel Core.
Kiến trúc Broadwell hiện tại là thế hệ thứ 4 của thương hiệu Intel Core (Intel Xeon E5 v4). Trong kiến trúc QuickPath, bộ điều khiển bộ nhớ được tích hợp vào CPU và giới thiệu giao thức kết nối point-to-point QuickPath Interconnect (QPI) làm liên kết dữ liệu giữa các CPU trong hệ thống.
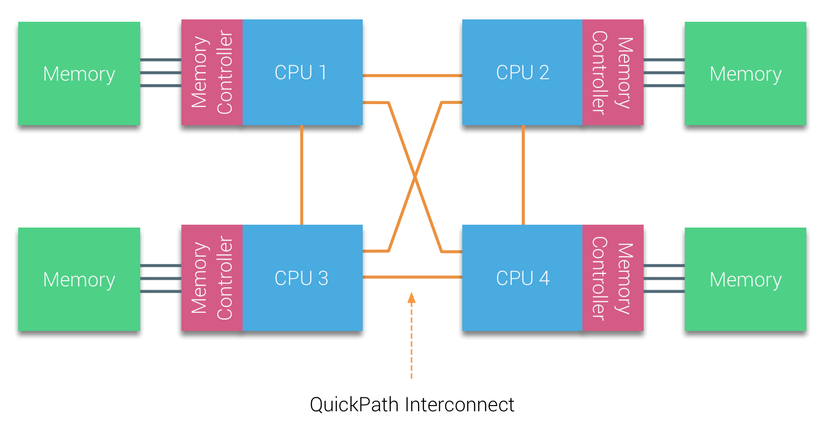
Kiến trúc Nehalem Processor không chỉ thay thế bus front-side truyền thống mà còn tái cấu trúc toàn bộ hệ thống con thành một thiết kế mô-đun dành cho CPU máy chủ. Thiết kế mô-đun này được giới thiệu với tên gọi “Uncore” (System Agent), đóng vai trò như một thư viện xây dựng giúp tối ưu hóa bộ nhớ đệm và tốc độ liên kết. Việc loại bỏ front-side bus giúp cải thiện khả năng mở rộng băng thông, nhưng vẫn cần giải quyết vấn đề giao tiếp giữa các processors, khi xử lý dung lượng bộ nhớ và băng thông lớn.
1.4.3. Cơ chế duy trì nhất quán cache có khả năng mở rộng
Mỗi core có một đường kết nối riêng đến L3 cache. Mỗi đường này bao gồm hàng nghìn dây dẫn, và ta không thể mở rộng tốt nếu muốn thu nhỏ manufacturing process xuống nanomet trong khi vẫn tăng số lượng core truy cập cache.
Để cải thiện khả năng mở rộng, kiến trúc Sandy Bridge đã di chuyển bộ nhớ đệm L3 ra khỏi Uncore và giới thiệu vòng liên kết trên chip có thể mở rộng (scalable ring on-die interconnect). Điều này cho phép Intel phân vùng và phân phối L3 cache thành các lát (slice) có kích thước bằng nhau, giúp tăng băng thông và độ liên kết. Mỗi lát có dung lượng 2.5 MB và được gán cho một core. Vòng liên kết giúp mỗi core có thể truy cập tất cả các lát khác. Hình minh họa bên dưới mô tả die configuration của một CPU Xeon thuộc vi kiến trúc Broadwell (v4) Low Core Count (LCC) (2016).
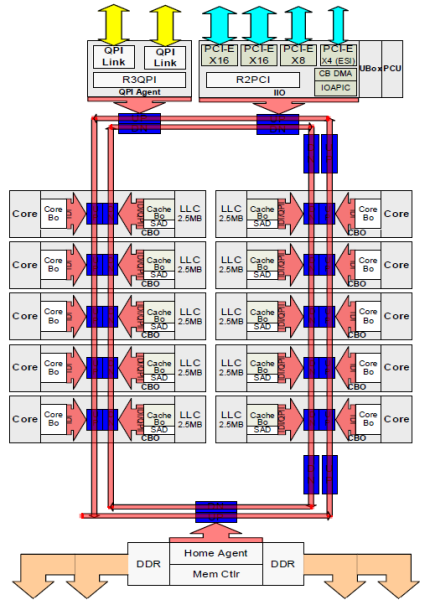
Kiến trúc cache này yêu cầu một giao thức snooping để đảm bảo tính nhất quán bộ nhớ đệm (cache coherency). Giao thức này phải xử lý cả cache phân tán cục bộ, cũng như sự tương tác giữa các processors khác trong hệ thống. Khi số lượng core tăng lên, lưu lượng snoop cũng tăng theo, vì mỗi core liên tục gặp các lỗi cache misses. Điều này làm tăng mức tiêu thụ băng thông của các liên kết QPI và cache cấp cuối (LLC – Last Level Cache), đòi hỏi sự phát triển liên tục của các giao thức duy trì tính nhất quán cache.
2. NUMA Configuration
Việc xem xét các layer vật lý giúp ta hiểu rõ hơn về cách CPU scheduler của VMkernel hoạt động. Điều này hỗ trợ trong việc lựa chọn configuration phần cứng tối ưu cho hiệu suất.
2.1. Thuật ngữ trong CPU
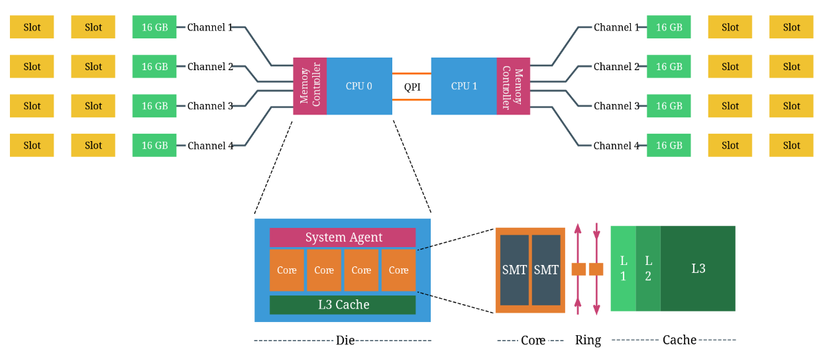
- CPU Package: Bộ vi xử lý hoàn chỉnh mà ta có thể cầm trên tay, chứa CPU die và được lắp vào socket CPU trên bo mạch chủ.
- CPU Die: Khối silicon bên trong CPU package, chứa các cores và system agent.
- Core: Đơn vị xử lý độc lập, có thể thực thi tác vụ một cách riêng biệt.
- Simultaneous Multithreading (SMT): Kỹ thuật đa luồng đồng thời, trong đó mỗi core vật lý có thể xử lý nhiều luồng (threads).
- Hyper-Threading (HT): Là phiên bản SMT độc quyền của Intel, cho phép một core vật lý xuất hiện dưới dạng hai lõi logic (hoặc hai luồng xử lý).
- Scalable Ring On-Die Interconnect: Một vòng kết nối nội bộ giúp các core xử lý giao tiếp với nhau và truy cập I/O hiệu quả.
2.2. Quản lý NUMA và phân bổ tài nguyên trên ESXi
Xét hệ thống có hai CPU Intel 2630 v4, mỗi CPU có 10 cores (20 luồng với Hyper-Threading). Bộ xử lý Intel 2630 v4 dựa trên vi kiến trúc Broadwell và hỗ trợ 4 kênh nhớ, với tối đa 3 DIMM trên mỗi kênh. Mỗi kênh được lắp một thanh RAM DDR4 16 GB, cung cấp tổng cộng 64 GB RAM cho mỗi CPU, và tổng 128 GB RAM cho toàn hệ thống. Vậy hệ thống có hai NUMA nodes, mỗi node bao gồm 10 cores và 64 GB RAM.
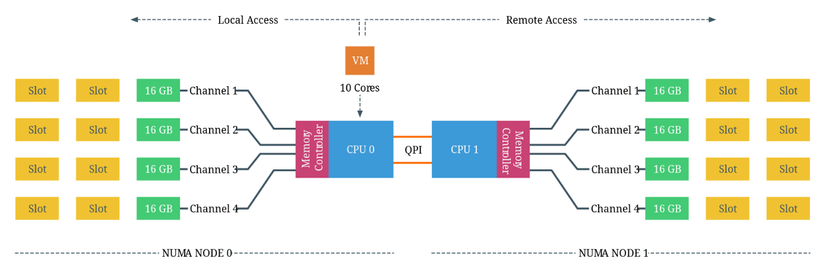
CPU có thể truy cập cả bộ nhớ cục bộ của mình và bộ nhớ từ xa được quản lý bởi các CPU khác trong hệ thống. Bộ nhớ từ xa được truy cập thông qua QPI (QuickPath Interconnect). Việc phân bổ bộ nhớ cho máy ảo (VM) được xử lý bởi CPU và NUMA schedulers của kernel ESXi. Mục tiêu của NUMA scheduler là tối đa hóa việc truy cập bộ nhớ cục bộ và phân bổ tài nguyên hiệu quả nhất có thể. Điều này phụ thuộc vào CPU và memory configuration của VM cũng như của hệ thống.
Ở hệ thông trên, mỗi core có thể truy cập tối đa 128 GB bộ nhớ. Như đã đề cập trước đó, NUMA scheduler của kernel ESXi cố gắng tối ưu hóa việc phân bổ và sắp xếp vCPU, đảm bảo CPU sử dụng tối đa bộ nhớ cục bộ khả dụng. Khi số vCPU của một VM vượt quá số core của một CPU vật lý, ESXi sẽ phân bổ vCPU đều trên số CPU vật lý tối thiểu cần thiết. ESXi cũng cung cấp thông tin về bố cục NUMA vật lý cho OS của VM, cho phép OS và/hoặc ứng dụng hỗ trợ NUMA lập lịch xử lý một cách tối ưu nhất có thể.
- NUMA = enable
- Node Interleaving = disabled
Chú ý: Khi Node Interleaving được đặt ở chế độ mặc định (disabled), BIOS ACPI sẽ tạo Bảng Phân Bổ Tài Nguyên Hệ Thống (SRAT - System Resource Allocation Table).
- Trong SRAT, thông tin về cấu hình phần cứng và kiến trúc bộ nhớ của CPU được mô tả, bao gồm CPU và phạm vi bộ nhớ nào thuộc về NUMA node cụ thể nào đó.
- Bộ nhớ của mỗi NUMA node sẽ được ánh xạ thành một khối địa chỉ bộ nhớ liên tục.
- ESXi sử dụng SRAT để nhận diện ngân hàng bộ nhớ nào là cục bộ đối với mỗi CPU vật lý và cố gắng gán bộ nhớ cục bộ cho từng vCPU của VM.
3. Cache Coherency
Khi nhắc đến NUMA, hầu hết mọi người chỉ tập trung vào RAM và số core của CPU vật lý, và tầm quan trọng của tính nhất quán bộ đệm (cache coherency) trong kiến trúc này thường bị bỏ qua.
Định vị bộ nhớ gần CPU giúp tăng khả năng mở rộng và giảm độ trễ nếu dữ liệu được truy xuất cục bộ. Và hiệu suất của hệ thống NUMA phụ thuộc rất nhiều vào khả năng mở rộng và hiệu quả của giao thức nhất quán bộ đệm (cache coherence protocol).
Khi nghiên cứu các tài liệu cũ về NUMA, chúng ta thấy rằng kiến trúc NUMA hiện đại thường được gọi là ccNUMA (Cache Coherent NUMA), nhấn mạnh đến tính nhất quán của bộ đệm trong hệ thống NUMA.
3.1. Giao thức Snoopy bus
Một hệ thống bộ nhớ của một hệ thống multi-CPU được coi là nhất quán nếu:
- CPU 1 ghi vào một địa chỉ bộ nhớ (X)
- Sau đó, CPU 2 đọc lại X
- Không có ghi nào khác vào X trong khoảng thời gian đó
- Giá trị CPU 2 đọc được chính là giá trị mà CPU 1 đã ghi trước đó*
Để đảm bảo bộ đệm cục bộ (local cache) luôn được cập nhật, giao thức snoopy bus đã ra đời. Giao thức này cho phép các cache theo dõi hoạt động ghi dữ liệu trên bus. Nếu một CPU ghi vào một biến được lưu trong cache của mình, các CPU còn lại có thể "nghe lén" (snoop) và cập nhật lại bản sao của biến đó trong cache của mình.
Trong kiến trúc multicore CPU ngày nay, tính nhất quán bộ đệm xảy ra ở hai cấp độ:
- Bên trong CPU (giữa các cores trong cùng package).
- Giữa các CPU (thông qua QPI, UPI hoặc các liên kết giao tiếp khác).
Hiệu suất bộ nhớ (băng thông và độ trễ) phụ thuộc rất nhiều vào giao thức snoop, vì nó quyết định tốc độ đồng bộ hóa dữ liệu giữa các bộ đệm và bộ nhớ chính.
3.2. Kiến trúc Cache
Sandy Bridge (v1) đã giới thiệu một kiến trúc cache mới. Hệ thống phân cấp bao gồm L1, L2 và L3 được truy cập thông qua kiến trúc vòng kết nối có thể mở rộng (scalable ring) tích hợp trên die. Mặc dù tất cả các cache đều nằm trên die của CPU, nhưng độ trễ giữa các cấp cache là khác nhau.
- L1 là cache nhanh nhất, CPU thường mất 4 chu kỳ để tải dữ liệu từ L1, 12 chu kỳ để tải dữ liệu từ L2 và khoảng 26 đến 31 chu kỳ để tải dữ liệu từ L3.
- Trong khi đó, việc truy xuất dữ liệu từ bộ nhớ cục bộ mất khoảng 190 chu kỳ, và nếu phải lấy dữ liệu từ bộ nhớ từ xa, CPU có thể mất đến 310 chu kỳ.
Mỗi CPU core có L1 và L2 cache riêng biệt, được gọi là bộ nhớ đệm riêng tư (private cache) vì không core nào khác có thể ghi đè lên các dòng cache của nó. Trong khi đó, L3 được chia sẻ giữa các core. L1 cache được chia thành hai phần riêng biệt: L1 Instruction cache (32KB) và L1 Data cache - L1D (32KB). L2 cache (256KB) hợp nhất, lưu trữ cả lệnh và dữ liệu, và được xem là exclusive cache. Điều này có nghĩa là nó không nhất thiết phải chứa toàn bộ bits đã có trong L1, tuy nhiên, do dung lượng lớn hơn nên L2 có xu hướng chứa cùng một dữ liệu và lệnh với L1. Khi dữ liệu được nạp từ bộ nhớ chính, nó sẽ đi qua toàn bộ các cấp cache trên đường đến core (L3 → L2 → L1). L3 được thiết kế như một inclusive cache, có nghĩa là nó phải chứa toàn bộ dữ liệu hiện có trong L2 và L1.
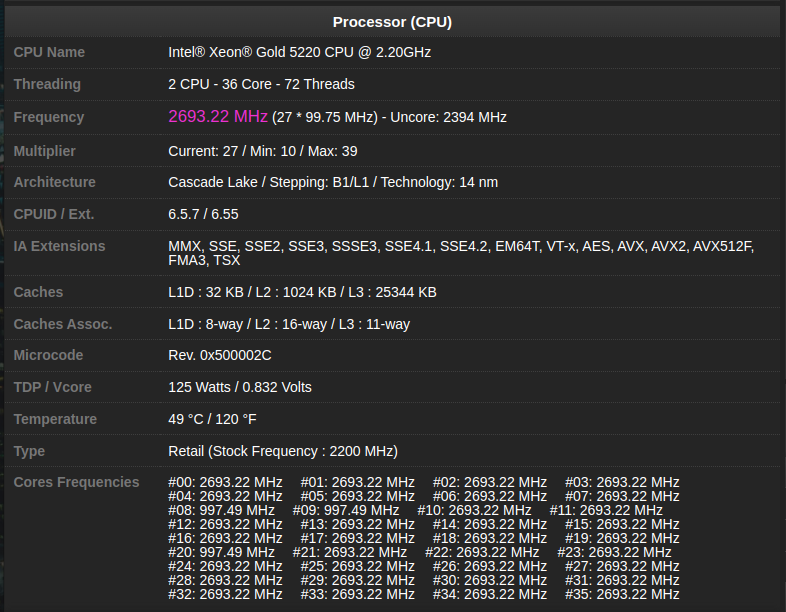
3.2.1. Data Prefetching
Để cải thiện hiệu suất, dữ liệu có thể được nạp trước vào L1 và L2 cache một cách suy đoán, quá trình này được gọi là prefetching. Prefetcher có nhiệm vụ tải dữ liệu vào cache trước khi CPU core thực sự cần đến nó. Theo Intel, công nghệ này có thể cải thiện hiệu suất lên đến 30%.
Vi kiến trúc Xeon hỗ trợ cả hardware prefetching và software prefetching. Một công nghệ software prefetching phổ biến là SSE (Streaming SIMD Extension), cung cấp gợi ý cho CPU về dữ liệu cần nạp trước khi thực hiện một lệnh. Các hardware prefetchers được phân tách giữa L1 và L2 cache.
Thành phần thực tế lưu trữ dữ liệu trong (L1D) được gọi là DCU (Data Cache Unit), có kích thước 32KB. L1D chịu trách nhiệm quản lý tất cả các thao tác tải (load) và lưu (store) dữ liệu. DCU prefetcher có nhiệm vụ nạp trước các dòng cache tiếp theo từ hệ thống bộ nhớ khi phát hiện một mẫu truy cập nhất định. Trong khi đó, DCU IP prefetcher cố gắng tải trước lệnh tiếp theo trước khi CPU core thực sự yêu cầu. L2 prefetcher cũng tương tác với L3. Khi L2 có quá nhiều yêu cầu đang chờ xử lý, L2 prefetcher sẽ lưu trữ dữ liệu vào L3 để tránh việc loại bỏ các dòng cache hữu ích.
3.2.2. L3 Cache - Last Level Cache (LLC)
L1 và L2 cache là riêng biệt cho từng core, lưu trữ dữ liệu mà core đó đọc, ghi hoặc sửa đổi. Trong khi đó, LLC được chia sẻ giữa các core. Sandy Bridge (v1) đã từ bỏ thiết kế cache hợp nhất trong Uncore, thay vào đó sử dụng cấu trúc cache phân tán và phân vùng. Tổng dung lượng LLC được chia thành các phân đoạn 2.5 MB, có thể được truy cập và sử dụng đầy đủ bởi tất cả các core trong hệ thống.
Một core không thể kiểm soát vị trí lưu trữ dữ liệu trong LLC và chỉ có khả năng truy cập toàn bộ LLC. Việc truy cập thông qua kiến trúc vòng kết nối (scalable on-die ring), và độ trễ phụ thuộc vào số lượng bước nhảy (hops) cần thiết để truy xuất dữ liệu.

3.3. Kiến trúc Scalable On-Die Ring
LLC của Intel là inclusive cache, tức là nó chứa tất cả dữ liệu được lưu trữ trong L1 và L2 cache. Các địa chỉ bộ nhớ được băm (hashed) và phân phối giữa các phân đoạn LLC để tận dụng băng thông cao của scalable on-die interconnect, đồng thời giảm thiểu hiện tượng tắc nghẽn (hot spots) và tranh chấp địa chỉ cache (cache contention). Kiến trúc này cũng giúp đảm bảo tính nhất quán (coherency).
Các phân đoạn L3 (L3 slices) được kết nối với scalable on-die interconnect, liên kết giữa các core CPU và Uncore, trong đó chứa:
- R3QPI (Ring to QPI Interconnect): Cầu nối giữa vòng nội bộ và liên kết QPI.
- Home Agent: Quản lý Bộ điều khiển bộ nhớ tích hợp (Integrated Memory Controller).
Vòng kết nối này có hai mảng thẻ (tag arrays):
- Một mảng dành cho truy cập dữ liệu (data accesses).
- Một mảng dành cho các yêu cầu duy trì tính nhất quán và prefetching.
Vòng chạy theo hai hướng (kim đồng hồ và ngược kim đồng hồ) để tối ưu hóa quãng đường từ CPU core đến phân đoạn cache gần nhất. Theo Intel, băng thông của vòng trên kiến trúc Sandy Bridge đạt khoảng 844GB/s. Từ Haswell (v3) trở đi, các vòng kết nối được liên kết bằng buffered interconnects, cho phép chúng hoạt động độc lập, trùng với thời điểm Intel giới thiệu chế độ Cluster-on-Die (CoD) cache snoop.
Khả năng mở rộng của dòng Xeon dẫn đến các thiết kế die khác nhau. Có ba cấu hình số lõi chính: Low Core Count (LCC - số lõi thấp), Medium Core Count (MCC - số lõi trung bình), và High Core Count (HCC - số lõi cao).
| Maximum core count | Die Design | Core Columns | Memory Controllers |
|---|---|---|---|
| 10 | LCC | 2 | 1 |
| 16 | MCC | 3 | 2 |
| 22 | HCC | 4 | 2 |
3.4. Cache Snooping
Dữ liệu từ một phân đoạn LLC có thể được đọc bởi bất kỳ core nào trong hệ thống. Khi dữ liệu này được đưa vào private cache của core, nó có thể bị sửa đổi. Khi xảy ra một thao tác cache (cache operation) có thể ảnh hưởng đến tính nhất quán dữ liệu, cache sẽ phát sóng thông tin (broadcast) đến tất cả các cache khác. Mỗi cache sẽ lắng nghe (snoop) các thông điệp này và phản ứng phù hợp. Các giao thức duy trì tính nhất quán bộ nhớ đệm (cache coherency protocols) theo dõi những thay đổi này. Giao thức phổ biến nhất dựa trên cơ chế vô hiệu hóa (invalidation-based protocol) là MESI.
| Trạng thái L2 cache | Định nghĩa | Mô tả | Vị trí của cache line |
|---|---|---|---|
| M (Modified) | Đã chỉnh sửa | Dữ liệu trong cache đã được cập nhật so với bộ nhớ chính | Chỉ tồn tại trong một core |
| E (Exclusive) | Độc quyền | Dữ liệu trong cache đồng nhất với bộ nhớ chính | Chỉ tồn tại trong một core |
| S (Shared) | Chia sẻ | Dữ liệu trong cache có thể được chia sẻ với các core khác. Nó đồng nhất giữa các cache nhưng có thể không đồng nhất với bộ nhớ chính | Tồn tại trên nhiều core |
| I (Invalid) | Không hợp lệ | Dữ liệu trong cache không còn hợp lệ và có thể bị ghi đè | Tồn tại trên nhiều core |
Intel đã mở rộng và áp dụng giao thức MESIF. Giao thức này thay đổi vai trò của trạng thái Shared (S) bằng cách bổ sung trạng thái Forwarding (F). Trong MESI, khi dữ liệu ở trạng thái Shared, mọi cache chứa cache line đều có thể phản hồi request, tạo ra lưu lượng lớn trong hệ thống nhiều core. Đặc biệt, trong hệ thống NUMA, nơi các CPU chia sẻ không gian địa chỉ bộ nhớ, điều này có thể dẫn đến nhiều phản hồi trùng lặp với độ trễ cao.
Để giải quyết vấn đề này, một cache duy nhất được thăng cấp lên trạng thái F (Forwarding). Cache này là cache duy nhất có thể phản hồi và gửi dữ liệu, trong khi các cache khác chứa cache line đó vẫn ở trạng thái Shared nhưng im lặng (Silent). Trạng thái F luôn chứa phiên bản mới nhất của dữ liệu, giúp cải thiện tính cục bộ thời gian của cache và giảm khả năng dữ liệu bị loại bỏ.
Sự tối ưu này giúp giảm đáng kể lưu lượng interconnect, vì trong MESI, tất cả các cache ở trạng thái Shared đều phản hồi, còn trong MESIF, chỉ có một cache duy nhất (F state) phản hồi, giảm thiểu giao tiếp không cần thiết.
3.5. Snoop Modes
Chế độ snoop (snoop mode) xác định agent nào sẽ quản lý các hoạt động snoop do các core phát sinh. Các snoop request có thể được gửi bởi caching agent (Cbox) của mỗi LLC slice hoặc bởi home agent. Mỗi thế hệ micro-architecture mới của Intel đều giới thiệu một chế độ snoop mới. Các chế độ này có thể được cấu hình thông qua BIOS, ảnh hưởng trực tiếp đến độ trễ cache (cache latency), mức tiêu thụ băng thông và tác động đến hiệu năng tổng thể của hệ thống.
Mặc dù Intel khuyến nghị một chế độ snoop mặc định cho các nhà cung cấp máy chủ, không phải BIOS nào cũng tuân theo khuyến nghị này. Do đó, cần đưa QPI Snoop Modes vào tài liệu cấu hình hệ thống. Nếu hệ thống đã được cấu hình theo mặc định của Intel, không nên thay đổi trừ khi có lý do dựa trên dữ liệu thực nghiệm. Hiện nay, có bốn chế độ snoop, trong đó chế độ Cluster-on-Die (CoD) chỉ khả dụng nếu hệ thống có hai home nodes trên một package (các thiết kế MCC và HCC die).
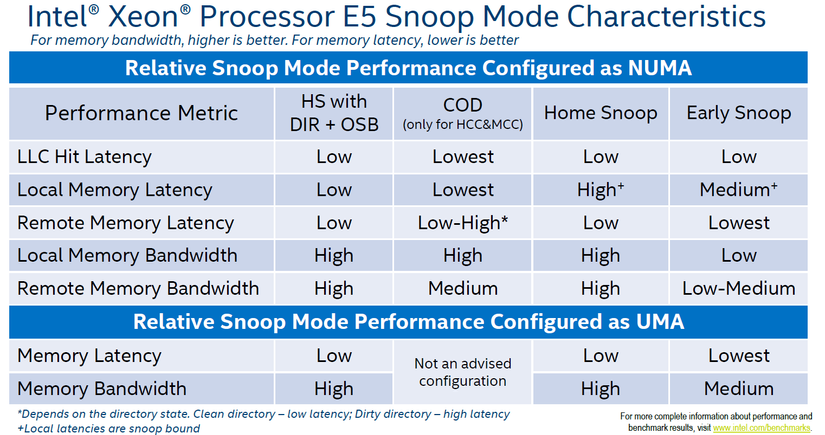
3.5.1. Early Snoop
Chế độ này được giới thiệu từ Sandy Bridge (v1) và có mặt trên tất cả các thế hệ CPU mới hơn. Trong chế độ này, caching agent trực tiếp tạo và gửi snoop probe hoặc snoop request thông qua scalable on-die ring. Nó có thể gửi snoop trực tiếp đến các cache agent khác hoặc broadcast đến tất cả các agent trong hệ thống.
Mô hình này có độ trễ thấp do snoop request được xử lý nhanh, dù snoop broadcast có thể chiếm nhiều băng thông, đặc biệt trong các thiết kế HCC die, gây tắc nghẽn giữa các NUMA nodes. Vì vậy, không khuyến nghị sử dụng chế độ này cho các workload tối ưu NUMA. Một số nhà sản xuất không tối ưu BIOS defaults và vẫn dùng chế độ này trên các hệ thống mới, do đó cần kiểm tra BIOS của hệ thống.
3.5.2. Home Snoop
Được giới thiệu từ Ivy Bridge (v2) và có mặt trên tất cả các thế hệ CPU mới hơn. Trong chế độ này, home agent (gắn với bộ điều khiển bộ nhớ) thay vì caching agent sẽ chịu trách nhiệm tạo snoop request. Dữ liệu phải đi qua home agent và vòng liên kết on-die scalable ring, khiến độ trễ cao hơn so với Early Snoop. Bằng cách sử dụng home agent như một thực thể trung tâm, mô hình này giúp giảm tiêu thụ băng thông, thích hợp cho workload cần tối ưu băng thông.
3.5.3. Home Snoop với Directory và Opportunistic Snoop Broadcast (OSB)
Cải tiến từ Home Snoop, cho phép snoop CPU từ xa một cách suy đoán (speculatively snoop) song song với việc đọc thư mục (directory read) trên home agent. Home agent chứa một “in-memory snoop directory”, giúp theo dõi trạng thái của các cache line, giảm tải snoop traffic đặc biệt trong các yêu cầu đọc.
- Khi hệ thống có băng thông trống, home agent sẽ snoop song song với directory lookup.
- Khi hệ thống bị tải nặng, snoop sẽ chỉ gửi đến các agent được directory xác định là cần snoop, giúp giảm overhead và tận dụng băng thông hiệu quả hơn.
Chế độ snoop mode này được giới thiệu từ Ivy Bridge (v2) và được loại bỏ trong Haswell (v3). Nó được đưa trở lại trong Broadwell (v4) và trở thành chế độ mặc định khuyến nghị của Intel cho thế hệ Broadwell. Không phải nhà sản xuất nào cũng tuân theo khuyến nghị của Intel, do đó cần kiểm tra BIOS settings.
3.5.4. Cluster-on-Die (CoD)
Mặc dù Home Snoop với DIR + OSB có hiệu năng tổng thể tốt nhất, nhưng nếu workload được tối ưu mạnh cho NUMA, thì Cluster-on-Die có thể là lựa chọn tốt hơn. Chế độ này cung cấp hiệu năng tốt nhất cho các thao tác cục bộ.
- Độ trễ LCC hit thấp nhất.
- Độ trễ bộ nhớ local thấp.
- Hiệu năng bộ nhớ từ xa phụ thuộc vào tần suất ghi của workload.
Nếu tối ưu hóa kích thước và phân bổ đúng công việc vào các NUMA nodes, chế độ COD có thể cải thiện hiệu suất. Tuy nhiên, nếu trung tâm dữ liệu ảo (virtual data center) được thiết kế để chạy với tỷ lệ hợp nhất cao (high consolidation ratio), điều này có thể khiến ESXi CPU scheduler phải phân phối các VM có kích thước nhỏ trên nhiều NUMA nodes, thì chế độ Home Snoop với Directory và OSB có thể phù hợp hơn.
3.6. Chi tiết về kiến trúc COD
3.6.1. Điều kiện sử dụng COD
Cluster-on-Die (COD) chỉ khả dụng trên các thiết kế chip MCC và HCC. Khi kích hoạt COD, CPU sẽ được chia logic thành hai NUMA node, trong đó mỗi node bao gồm một phần của scalable ring on-die interconnect, bộ home agent và bộ điều khiển bộ nhớ tích hợp (IMC). Trên thiết kế MCC và HCC, có hai bộ điều khiển bộ nhớ đang hoạt động, mỗi bộ điều khiển phục vụ hai kênh bộ nhớ. Do đó, các NUMA nodes sẽ tương ứng với các bộ điều khiển này.
Lưu ý quan trọng: Khi bật COD, mỗi CPU sẽ có hai NUMA nodes, đồng nghĩa với việc một hệ thống dual-socket sẽ có bốn NUMA nodes. Ví dụ, trước khi bật COD trên một hệ thống 512GB RAM, hệ thống sẽ tạo ra hai NUMA nodes, mỗi node sử dụng 256GB RAM. Sau khi bật COD, hệ thống tạo ra bốn NUMA nodes, mỗi node sử dụng 128GB RAM.
3.6.2. Cách hoạt động của COD
COD phân vùng LLC và RAM, giúp giảm độ trễ bằng cách giảm số lượng LLC slices trong một NUMA node. Ví dụ, CPU Intel Xeon E5-2699 v4 có 22 lõi, khi bật COD, CPU sẽ chia thành 2 miền độc lập (affinity domains), mỗi miền có 11 slices LLC. Điều này giúp dữ liệu chỉ phân bổ trong 11 slices thay vì 22 slices, giảm số lượng "hops" cần thiết để truy cập dữ liệu. Trên Broadwell (v4), COD còn giúp loại bỏ giao tiếp chéo giữa các buffered interconnect, giảm xung đột trên vòng kết nối (ring collisions) và tối ưu băng thông.
Khi một cache miss xảy ra trong LLC của một miền, nó sẽ liên hệ trực tiếp với home agent phụ trách bộ nhớ. Mỗi home agent sẽ quản lý các dòng bộ nhớ của riêng mình, điều này giúp LLC có thể chứa cache lines từ bộ nhớ "từ xa". Nếu NUMA scheduler không thể gán chính xác (affinitize) tiến trình và bộ nhớ, thì lưu lượng sẽ đi qua buffered interconnect.
3.7. Khuyến nghị Snoop Mode
- Nếu các VMs được tối ưu để chạy trong một NUMA node duy nhất, COD sẽ mang lại hiệu suất cao.
- Nếu vận hành nhiều Wide VMs, nên chọn snoop mode "Home Snoop with Directory and Opportunistic Snoop Broadcast (OSB)", vì COD tập trung vào việc giảm độ trễ thông qua affinity.
- Với hệ thống ưu tiên độ trễ thấp, nên tự quản lý NUMA và vô hiệu hóa NUMA auto balancing.
Tài liệu tham khảo
[1] Frankdenneman. (2020, January 26). Introduction 2016 NUMA Deep Dive Series. frankdenneman.nl. https://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series/ [2] Team, S. P. &. S. D. (2024, June 25). Automatic Non-Uniform Memory Access (NUMA) balancing. https://documentation.suse.com/sles/15-SP6/html/SLES-all/cha-tuning-numactl.html [3] 9.2. Automatic NUMA Balancing | Red Hat Product Documentation. (n.d.). https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/7/html/virtualization_tuning_and_optimization_guide/sect-virtualization_tuning_optimization_guide-numa-auto_numa_balancing#sect-Virtualization_Tuning_Optimization_Guide-NUMA-Auto_NUMA_Balancing
All rights reserved
