Deep Dive – Phân Tích Chi Tiết LSTM: Giữ Thông Tin Lâu Dài, So Sánh với RNN và Công Thức Toán Học 🔍
👋 Chào mừng bạn quay trở lại! Nếu bạn đã theo dõi bài Tìm Hiểu LSTM: Bí Quyết Giữ Thông Tin Lâu Dài Hiệu Quả 🧠🔗 trước đó, bạn sẽ biết LSTM vượt trội RNN nhờ cell state và cổng điều khiển. Nhưng làm sao cell state "sống sót" qua chuỗi dài? Tại sao gradient không biến mất? Hôm nay, chúng ta sẽ "đào sâu" vào:
- Cơ chế lưu trữ thông tin qua Forget/Input/Output gates.
- So sánh trực tiếp LSTM vs RNN qua góc nhìn toán học.
- Breakdown từng công thức – hiểu tường tận cách LSTM học!
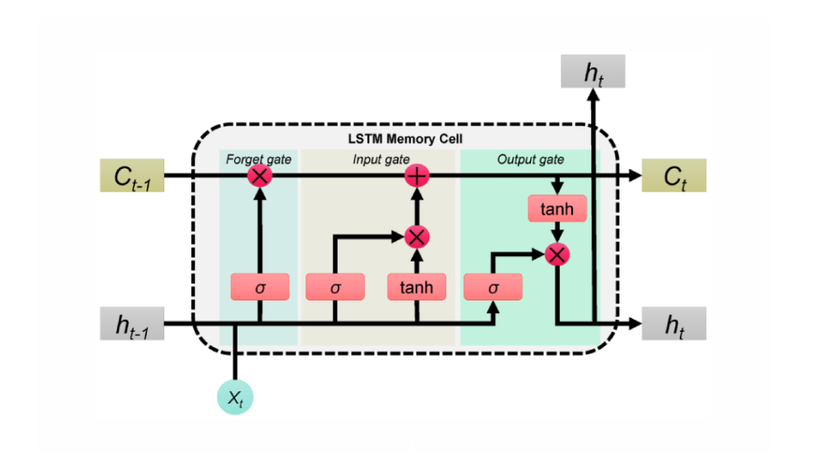
Cell State: "Siêu Năng Lực" Giữ Thông Tin Dài Hạn 🦸♀️
-
Forget Gate có nhiệm vụ giảm trọng số cho các thông tin không liên quan, giúp mô hình tập trung vào những dữ liệu thiết yếu. Cơ chế này sử dụng hàm sigmoid để “quét” qua thông tin cũ và chỉ giữ lại phần quan trọng.
Ví dụ, khi xử lý câu "Tôi thích ăn táo vì chúng...", nếu mô hình đã xác định chủ đề chính là "táo", thì Forget Gate sẽ giảm trọng số của cụm từ "Tôi thích", loại bỏ thông tin không cần thiết và giúp tập trung vào ý chính của câu.
-
Input Gate có nhiệm vụ kiểm soát và lựa chọn thông tin mới cần được thêm vào cell state. Cơ chế này sử dụng hàm sigmoid để đánh giá mức độ quan trọng của dữ liệu mới, kết hợp với hàm tanh tạo ra các giá trị ứng cử, đảm bảo rằng chỉ những thông tin thiết yếu mới được lưu trữ.
Cell state như một bộ lọc thông minh:
LSTM vs RNN: Cuộc Đua Của Gradient 🏎️
Vấn Đề Của RNN
Recurrent Neural Networks (RNN) gặp một số vấn đề quan trọng liên quan đến gradient khi lan truyền ngược (backpropagation through time - BPTT):
-
Hidden State Trong RNN:
Hidden state được tính toán theo công thức:
Trong đó:
- là hidden state tại thời điểm .
- là ma trận trọng số.
- là đầu vào tại thời điểm .
- là bias.
-
Vấn Đề Gradient Vanishing
Gradient phụ thuộc vào tích ma trận .
Khi số bước thời gian tăng lên, nếu các phần tử trong ma trận có giá trị nhỏ hơn 1, gradient sẽ suy giảm theo hàm mũ, dẫn đến vanishing gradient. Điều này làm cho các trạng thái ban đầu của chuỗi dữ liệu gần như không có ảnh hưởng đến đầu ra cuối cùng.
LSTM Cải Thiện Thế Nào?
Long Short-Term Memory (LSTM) được thiết kế để giải quyết vấn đề gradient vanishing bằng cách sử dụng cell state thay vì chỉ dựa vào hidden state như RNN.
-
Gradient Chủ Yếu Truyền Qua Cell State
Ở đây, là gate kiểm soát mức độ thông tin được giữ lại từ trạng thái trước đó.
-
Giữ Gradient Không Đổi Khi Cần Thiết
Khi (tức là khi LSTM cần giữ thông tin lâu dài), gradient gần như không thay đổi theo thời gian. Điều này giúp tránh hiện tượng vanishing gradient, cho phép LSTM ghi nhớ thông tin từ các bước thời gian xa hơn so với RNN.
Giải Mã Toán Học 🧮
1. Các thành phần cốt lõi của một cell LSTM
- Forget Gate ( ): Quyết định loại bỏ những thông tin không cần thiết từ cell state.
- Input Gate ( ): Quyết định thông tin mới nào sẽ được lưu trữ.
- Output Gate ( ): Quyết định thông tin nào sẽ được xuất ra làm hidden state cho bước tiếp theo.
- Cell State ( ): Bộ nhớ dài hạn (được cập nhật tại mỗi bước thời gian).
- Hidden State ( ): Bộ nhớ ngắn hạn (được suy ra từ cell state).
2. Các phương trình toán học
Tại mỗi bước thời gian , với đầu vào và các trạng thái trước đó cũng như , LSTM tính toán như sau:
Bước 1: Forget Gate
Mục đích: Quyết định bao nhiêu phần của (cell state trước đó) cần bị loại bỏ.
Đầu vào: Concatenation của (trạng thái ẩn trước đó) và (đầu vào hiện tại).
Trọng số: (trọng số của Forget Gate), (bias).
Hàm kích hoạt: Hàm sigmoid cho ra giá trị trong khoảng từ 0 (loại bỏ) đến 1 (giữ lại).
Bước 2: Input Gate & Candidate Cell State
Mục đích:
- : Quyết định lượng của (candidate cell state) sẽ được thêm vào .
- : Tạo ra giá trị đề xuất cập nhật cho cell state.
Trọng số: (trọng số cho input gate & candidate cell state), (bias).
Hàm kích hoạt:
- Hàm sigmoid điều chỉnh giá trị của candidate cell state.
- Hàm nén các giá trị về khoảng nhằm đảm bảo cập nhật ổn định.
Bước 3: Update Cell State
Mục đích: Kết hợp thông tin cũ với thông tin mới .
Phép toán:
- : Phép nhân từng phần giúp loại bỏ các phần không cần thiết của .
- : Thêm thông tin mới có liên quan từ .
Bước 4: Output Gate & Hidden State
Mục đích:
- : Quyết định phần nào của sẽ được xuất ra làm .
- : Trạng thái ẩn được truyền cho bước thời gian tiếp theo.
Trọng số: (trọng số của output gate), (bias).
Hàm kích hoạt:
- : Hàm sigmoid lọc thông tin từ .
- : Nén giá trị của $C_t$0 về khoảng trước khi nhân với .
3. Các chi tiết quan trọng cần được giải thích
A. Concatenation của và
Đầu vào của mỗi cổng là sự nối kết của trạng thái ẩn trước đó và đầu vào hiện tại :
Điều này cho phép LSTM đưa ra quyết định dựa trên cả ngữ cảnh quá khứ và thông tin hiện tại.
B. Chia sẻ Tham số
Các trọng số và bias được sử dụng lại ở mọi bước thời gian, tương tự như trong RNN. Điều này giúp giảm số lượng tham số và cho phép xử lý các chuỗi có độ dài thay đổi.
C. Kích thước (Dimensions)
Giả sử:
- là kích thước của hidden state.
- là kích thước của đầu vào.
Ta có:
- Kích thước .
- Kích thước
- Kích thước
- Kích thước .
- Kích thước
D. Các Hàm Kích Hoạt
- Hàm Sigmoid ()
- Được sử dụng trong các cổng để cho ra giá trị trong khoảng từ 0 đến 1.
- Ví dụ: nghĩa là giữ lại của .
- Hàm Hyperbolic Tangent ( )
- Được sử dụng trong và để nén các giá trị về khoảng .
- Ngăn chặn hiện tượng gradient bùng nổ và tạo tính phi tuyến cho mô hình.
🎯 Kết Luận
Qua bài viết này, chúng ta đã cùng nhau khám phá chi tiết cách hoạt động của LSTM, từ cơ chế cổng tinh vi cho đến việc duy trì thông tin dài hạn một cách hiệu quả. Hiểu được cách LSTM quản lý thông tin qua các bước thời gian không chỉ giúp ta nhận thức rõ hơn về cách các mô hình deep learning xử lý dữ liệu chuỗi mà còn mở ra cánh cửa để tìm hiểu sâu hơn về các kiến trúc tiên tiến khác trong lĩnh vực xử lý ngôn ngữ tự nhiên.
Nếu bạn đã cảm thấy hứng thú với việc làm thế nào các mô hình như LSTM “ghi nhớ” được thông tin quan trọng qua nhiều bước, thì hãy tiếp tục hành trình khám phá của mình! Bước tiếp theo, chúng ta sẽ chuyển sang Word2vec – công cụ mạnh mẽ giúp biểu diễn từ ngữ dưới dạng vector, tạo nền tảng cho những bước tiến vượt bậc trong các mô hình NLP hiện đại như Transformers.
👉 Đừng bỏ lỡ bài viết về Word2vec – Giải Mã Mô Hình Biểu Diễn Ngôn Ngữ Trước Khi Đến Với Transformers để cùng khám phá cách các từ được chuyển hóa thành các vector số học có ý nghĩa và tìm hiểu cách mà bước chuyển này tạo nền tảng cho các kiến trúc tiên tiến trong NLP!
Cảm ơn bạn đã đồng hành cùng bài viết này – hẹn gặp lại trong hành trình khám phá sâu hơn về thế giới của NLP và Deep Learning!
All rights reserved
