Foundations of Large Language Models: Pre-training phần 1
Lời tựa
Các mô hình ngôn ngữ lớn (Large Language Models - LLMs) bắt nguồn từ lĩnh vực xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP), nhưng chúng đã trở thành một trong những tiến bộ công nghệ mang tính cách mạng nhất trong lĩnh vực trí tuệ nhân tạo (Artificial Intelligence - AI) trong những năm gần đây. Một hiểu biết quan trọng mà LLMs mang lại là kiến thức về thế giới và ngôn ngữ có thể được thu thập thông qua các tác vụ mô hình hóa ngôn ngữ quy mô lớn (large-scale language modeling tasks), và bằng cách này, chúng ta có thể tạo ra một mô hình phổ quát có khả năng xử lý nhiều vấn đề khác nhau. Khám phá này đã tác động sâu sắc đến các phương pháp nghiên cứu trong NLP và nhiều ngành liên quan. Chúng ta đã chuyển từ việc đào tạo các hệ thống chuyên biệt từ đầu bằng cách sử dụng một lượng lớn dữ liệu có nhãn (labeled data) sang một mô hình mới là sử dụng pre-training quy mô lớn để có được các mô hình nền tảng (foundation models), sau đó được fine-tune, aligned và prompted.
Bài viết bao gồm bốn chương:
- Chương 1 giới thiệu những điều cơ bản về pre-training. Đây là nền tảng của LLMs, và các phương pháp pre-training phổ biến cùng với kiến trúc mô hình sẽ được thảo luận ở đây.
- Chương 2 giới thiệu các mô hình sinh (generative models), là LLMs mà chúng ta thường đề cập đến ngày nay. Sau khi trình bày quy trình cơ bản xây dựng các mô hình này, chúng ta cũng sẽ khám phá cách mở rộng quy mô đào tạo mô hình (scale up model training) và xử lý văn bản dài (long texts).
- Chương 3 giới thiệu các phương pháp prompting cho LLMs. Chúng ta sẽ thảo luận về các chiến lược prompting khác nhau, cùng với các phương pháp tiên tiến hơn như chain-of-thought reasoning và thiết kế prompt tự động (automatic prompt design).
- Chương 4 giới thiệu các phương pháp alignment cho LLMs. Chương này tập trung vào instruction fine-tuning và alignment dựa trên phản hồi của con người (human feedback).
Ký hiệu
biến số
vectơ hàng hoặc ma trận
hàm của
giá trị lớn nhất của
giá trị của làm tối đa hóa
chuỗi token đầu vào cho mô hình
token đầu vào tại vị trí
chuỗi token đầu ra được tạo ra bởi mô hình
token đầu ra tại vị trí
tham số mô hình
xác suất của
xác suất có điều kiện của khi biết
phân phối xác suất của một biến số khi biết
xác suất của được tham số hóa bởi
trạng thái ẩn tại bước thời gian trong các mô hình tuần tự (sequential models)
ma trận của tất cả các trạng thái ẩn theo thời gian trong một chuỗi
ma trận truy vấn (query), khóa (key) và giá trị (value) trong cơ chế attention
Hàm Softmax chuẩn hóa vectơ hoặc ma trận đầu vào
hàm mất mát (loss function)
tập dữ liệu (dataset) được sử dụng để đào tạo hoặc fine-tuning mô hình
gradient của hàm mất mát đối với các tham số
KL divergence giữa các phân phối và
CHƯƠNG 1
Pre-training
Sự phát triển của các mô hình chuỗi nơ-ron (neural sequence models) như Transformers và những tiến bộ trong học tự giám sát quy mô lớn (large-scale self-supervised learning) đã mở ra khả năng hiểu và tạo ngôn ngữ phổ quát (universal language understanding and generation). Thành tựu này chủ yếu nhờ vào pre-training, quá trình tách các thành phần chung từ các hệ thống nơ-ron và đào tạo chúng trên lượng lớn dữ liệu chưa gán nhãn (unlabeled data) bằng tự giám sát (self-supervision). Các mô hình pre-trained này, được xem là các mô hình nền tảng (foundation models), có thể dễ dàng được điều chỉnh cho nhiều tác vụ khác nhau thông qua fine-tuning hoặc prompting, làm thay đổi đáng kể cách tiếp cận trong NLP. Thay vì học có giám sát quy mô lớn (large-scale supervised learning) cho từng tác vụ cụ thể, chúng ta có thể điều chỉnh các mô hình nền tảng pre-trained.
Mặc dù pre-training phổ biến trong NLP gần đây, khái niệm này đã xuất hiện từ lâu trong deep learning. Các nỗ lực ban đầu bao gồm học không giám sát (unsupervised learning) cho RNNs, mạng feedforward sâu (deep feedforward networks), và autoencoders. Trong kỷ nguyên deep learning hiện đại, sự trỗi dậy của pre-training một phần đến từ học không giám sát quy mô lớn (large-scale unsupervised learning) của các mô hình word embedding. Pre-training cũng thu hút sự chú ý trong computer vision, với việc đào tạo các mô hình xương sống (backbone models) trên các tập dữ liệu như ImageNet và ứng dụng cho các tác vụ hạ nguồn (downstream tasks). Nghiên cứu lớn về pre-training trong NLP bắt đầu với các mô hình ngôn ngữ (language models) sử dụng học tự giám sát (self-supervised learning), ví dụ như BERT và GPT. Các mô hình này sử dụng ý tưởng đào tạo để dự đoán các từ bị masked trong văn bản lớn, cho thấy khả năng mô hình hóa cấu trúc ngôn ngữ đáng kể mà không cần đào tạo trực tiếp. Tính tổng quát của pre-training giúp các hệ thống đạt hiệu suất cao trong nhiều bài toán NLP, thậm chí vượt trội các hệ thống có giám sát trước đó. Gần đây, LLMs pre-trained đạt được thành công lớn hơn, mở ra tiềm năng cho trí tuệ nhân tạo tổng quát hơn (more general artificial intelligence).
Chương này sẽ thảo luận về pre-training trong NLP, bắt đầu với giới thiệu tổng quan về phương pháp và ứng dụng. BERT sẽ được dùng làm ví dụ để minh họa cách mô hình chuỗi được đào tạo qua tác vụ tự giám sát (self-supervised task) là masked language modeling. Tiếp theo là thảo luận về điều chỉnh các mô hình chuỗi pre-trained cho các tác vụ NLP khác nhau. Chương này tập trung chủ yếu vào pre-training trong NLP, không đi sâu vào LLMs sinh (generative large language models), mà sẽ được đề cập trong các chương sau.
1.1 Pre-training các mô hình NLP
Thảo luận về pre-training trong NLP thường tập trung vào hai loại vấn đề chính: mô hình hóa chuỗi (sequence modeling) (hoặc mã hóa chuỗi (sequence encoding)) và tạo chuỗi (sequence generation). Để đơn giản, chúng ta có thể mô tả chúng bằng một mô hình chung như sau:
Trong đó:
- là chuỗi token đầu vào, với là token đặc biệt ( hoặc [CLS]) ở đầu chuỗi.
- (hoặc ) là mạng nơ-ron với tham số .
- là đầu ra của mạng, có thể thay đổi tùy theo bài toán (ví dụ: phân phối từ vựng trong language modeling, hoặc chuỗi vector trong sequence encoding).
Có hai vấn đề cơ bản liên quan đến pre-training:
- Tối ưu hóa cho tác vụ pre-training: Khác với các bài toán học tiêu chuẩn, pre-training không hướng đến một tác vụ hạ nguồn (downstream task) cụ thể. Mục tiêu là đào tạo mô hình có khả năng tổng quát hóa trên nhiều tác vụ khác nhau.
- Áp dụng mô hình pre-trained cho các tác vụ hạ nguồn: Để sử dụng mô hình pre-trained cho các tác vụ cụ thể, cần điều chỉnh các tham số thông qua fine-tuning với dữ liệu gán nhãn hoặc prompting mô hình với mô tả tác vụ.
Phần tiếp theo sẽ thảo luận về các ý tưởng cơ bản để giải quyết hai vấn đề này.
1.1.1 Pre-training không giám sát (Unsupervised), giám sát (Supervised) và tự giám sát (Self-supervised)
Trong deep learning, pre-training là quá trình tối ưu hóa mạng nơ-ron trước khi được đào tạo hoặc điều chỉnh cho các tác vụ cụ thể. Ý tưởng chính là mô hình pre-trained trên một tác vụ có thể được điều chỉnh để thực hiện các tác vụ khác, giảm sự cần thiết phải đào tạo từ đầu các mạng phức tạp trên dữ liệu gán nhãn hạn chế. Thay vào đó, ta tận dụng các tác vụ có tín hiệu giám sát dễ dàng thu được, tạo ra các mô hình tổng quát hơn.
Trong giai đoạn đầu của deep learning, pre-training không giám sát (unsupervised pre-training) là phương pháp được chú trọng. Các tham số mạng nơ-ron được tối ưu hóa dựa trên tiêu chí không trực tiếp liên quan đến tác vụ cụ thể, ví dụ như giảm thiểu cross-entropy tái cấu trúc đầu vào. Pre-training không giám sát thường đóng vai trò là bước chuẩn bị cho học có giám sát (supervised learning), mang lại lợi ích như tìm kiếm cực tiểu cục bộ tốt hơn và hiệu ứng chính quy hóa, giúp giai đoạn học có giám sát tiếp theo ổn định và dễ dàng hơn.
Một phương pháp khác là pre-training giám sát (supervised pre-training), trong đó mạng nơ-ron được pre-train trên các tác vụ học có giám sát. Ví dụ, một mô hình chuỗi có thể được pre-train cho tác vụ phân loại sentiment câu. Sau đó, mô hình chuỗi pre-trained này được điều chỉnh (fine-tune) cho các tác vụ hạ nguồn khác. Ưu điểm của pre-training giám sát là sự đơn giản trong quá trình đào tạo (cả pre-training và fine-tuning) theo mô hình học có giám sát đã được nghiên cứu kỹ. Tuy nhiên, khi mạng nơ-ron trở nên phức tạp hơn, nhu cầu về dữ liệu gán nhãn cho pre-training cũng tăng lên, gây khó khăn khi dữ liệu gán nhãn quy mô lớn không có sẵn.
Phương pháp thứ ba là học tự giám sát (self-supervised learning). Trong phương pháp này, mạng nơ-ron được đào tạo bằng tín hiệu giám sát tự tạo từ dữ liệu chưa gán nhãn, thay vì tín hiệu từ con người. Điều này thường được thực hiện bằng cách xây dựng các tác vụ đào tạo từ dữ liệu chưa gán nhãn, ví dụ như tạo nhãn giả (pseudo labels). Mặc dù mới nổi lên gần đây trong NLP, học tự giám sát không phải là khái niệm mới. Trong machine learning, self-training là một khái niệm liên quan, trong đó mô hình được cải thiện lặp đi lặp lại bằng cách học từ nhãn giả. Tuy nhiên, pre-training tự giám sát trong NLP không dựa vào mô hình ban đầu để gán nhãn, mà tạo ra tín hiệu giám sát trực tiếp từ văn bản và đào tạo toàn bộ mô hình từ đầu. Ví dụ nổi tiếng là đào tạo mô hình chuỗi bằng cách dự đoán từ bị masked. Học tự giám sát quy mô lớn (large-scale self-supervised learning) đã dẫn đến thành công của pre-training trong nhiều tác vụ NLP.
Hình 1.1 minh họa sự so sánh giữa ba phương pháp pre-training. Pre-training tự giám sát đã trở nên rất thành công và là nền tảng của hầu hết các mô hình NLP hiện đại. Do đó, chương này và cuốn sách sẽ tập trung vào pre-training tự giám sát, cách mô hình chuỗi được pre-train và ứng dụng của chúng.
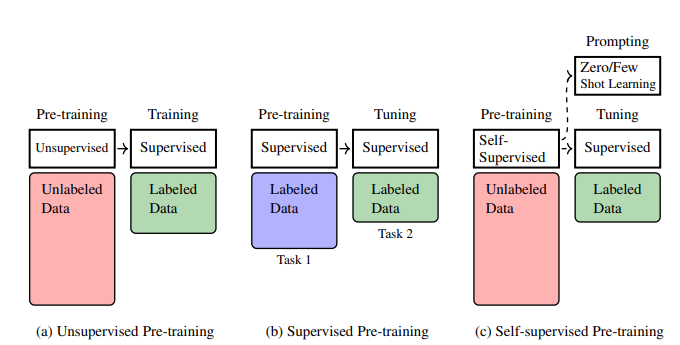
Hình 1.1: Minh họa pre-training không giám sát, giám sát và tự giám sát. Trong pre-training không giám sát, pre-training được thực hiện trên dữ liệu chưa được gán nhãn quy mô lớn. Nó có thể được xem như một bước sơ bộ để có một điểm khởi đầu tốt cho quá trình tối ưu hóa tiếp theo, mặc dù vẫn cần nỗ lực đáng kể để đào tạo thêm mô hình với dữ liệu được gán nhãn sau pre-training. Trong pre-training có giám sát, giả định cơ bản là các tác vụ học có giám sát khác nhau có liên quan. Vì vậy, chúng ta có thể đào tạo mô hình trên một tác vụ trước, và chuyển mô hình thu được sang một tác vụ khác với một số nỗ lực đào tạo hoặc điều chỉnh. Trong pre-training tự giám sát, một mô hình được pre-trained trên dữ liệu chưa được gán nhãn quy mô lớn thông qua tự giám sát. Mô hình có thể được đào tạo tốt theo cách này, và chúng ta có thể điều chỉnh nó một cách hiệu quả cho các tác vụ mới thông qua fine-tuning hoặc prompting.
1.1.2 Adapting Pre-trained Models
Như đã đề cập ở trên, hai loại mô hình chính được sử dụng rộng rãi trong pre-training NLP.
-
Mô hình mã hóa chuỗi (Sequence Encoding Models). Cho một chuỗi các từ hoặc tokens, một mô hình mã hóa chuỗi biểu diễn chuỗi này dưới dạng một vectơ giá trị thực hoặc một chuỗi vectơ, và thu được một biểu diễn của chuỗi. Biểu diễn này thường được sử dụng làm đầu vào cho một mô hình khác, chẳng hạn như hệ thống phân loại câu.
-
Mô hình tạo chuỗi (Sequence Generation Models). Trong NLP, tạo chuỗi thường đề cập đến vấn đề tạo ra một chuỗi tokens dựa trên một ngữ cảnh (context) nhất định. Thuật ngữ ngữ cảnh có ý nghĩa khác nhau giữa các ứng dụng. Ví dụ, nó đề cập đến các tokens trước đó trong language modeling, và đề cập đến chuỗi ngôn ngữ nguồn trong machine translation.
Chúng ta cần các kỹ thuật khác nhau để áp dụng các mô hình này cho các tác vụ hạ nguồn sau pre-training. Ở đây chúng ta quan tâm đến hai phương pháp sau.
1.1.2.1 Fine-tuning các mô hình Pre-trained
Đối với pre-training mô hình mã hóa chuỗi (sequence encoding), fine-tuning là một phương pháp phổ biến để điều chỉnh mô hình pre-trained. Giả sử chúng ta có một encoder (ví dụ, Transformer encoder) với tham số đã được pre-train và tối ưu thành . Chúng ta có thể sử dụng encoder này để biểu diễn chuỗi đầu vào thành chuỗi vector :
Encoder thường là một thành phần của hệ thống NLP lớn hơn. Ví dụ, trong bài toán text classification (phân loại văn bản), để xác định polarity (tính tích cực, tiêu cực, trung tính) của văn bản, ta có thể thêm một classifier (mạng nơ-ron với tham số ) lên trên encoder. Mô hình text classification sẽ có dạng:
là phân phối xác suất trên các nhãn (ví dụ: {tích cực, tiêu cực, trung tính}).
Vì các tham số và chưa được tối ưu cho tác vụ classification, chúng ta cần fine-tune mô hình. Quá trình fine-tuning thường sử dụng dữ liệu gán nhãn cho tác vụ hạ nguồn, coi đây là bài toán học có giám sát (supervised learning). Kết quả là các tham số được cập nhật thành và . Ngoài ra, ta có thể đóng băng (freeze) tham số encoder và chỉ tối ưu , giúp classifier điều chỉnh hiệu quả với encoder pre-trained.
Sau khi fine-tuning, mô hình có thể được dùng để phân loại văn bản mới. Ví dụ, với câu "Tôi thích đồ ăn ở đây. Nó thật tuyệt vời!", sau khi tokenize thành , ta đưa vào mô hình fine-tuned :
Nhãn có xác suất cao nhất sẽ được chọn (trong ví dụ này là "tích cực").
Fine-tuning thường sử dụng ít dữ liệu gán nhãn hơn pre-training và ít tốn kém tính toán hơn. Điều này làm cho việc điều chỉnh mô hình pre-trained rất hiệu quả: chỉ cần một lượng nhỏ dữ liệu gán nhãn để điều chỉnh mô hình cho tác vụ mới. Chi tiết hơn về fine-tuning sẽ được thảo luận trong Phần 1.4.
1.1.2.2 Prompting các mô hình Pre-trained
Không như mô hình mã hóa chuỗi, các mô hình tạo chuỗi (sequence generation models) thường được sử dụng độc lập cho các tác vụ tạo ngôn ngữ như question answering và machine translation. Việc điều chỉnh (fine-tune) các mô hình này có thể được thực hiện trực tiếp trên các tác vụ hạ nguồn. Ví dụ, một mô hình encoder-decoder đa ngôn ngữ pre-trained có thể được fine-tune trên dữ liệu song ngữ để cải thiện hiệu suất dịch thuật.
Một ví dụ nổi bật trong mô hình tạo chuỗi là LLMs (Large Language Models), được đào tạo trên lượng lớn dữ liệu. LLMs được đào tạo để dự đoán token tiếp theo dựa trên các token đã có. Mặc dù tác vụ dự đoán token có vẻ đơn giản, nhưng nó cho phép mô hình học được kiến thức ngôn ngữ tổng quát. Khả năng dự đoán token tốt của LLMs cho phép chuyển nhiều bài toán NLP thành bài toán tạo văn bản thông qua prompting.
Ví dụ, bài toán text classification có thể được chuyển thành prompting bằng cách thêm vào câu đầu vào một phần để LLM hoàn thành:
"Tôi thích đồ ăn ở đây. Nó thật tuyệt vời! Tôi ___"
Phần completion (ví dụ: "happy", "tích cực") sẽ giúp xác định nhãn của văn bản gốc. Đây là một ví dụ về prompting đơn giản.
Instruction-based prompting có thể hướng dẫn LLMs thực hiện các tác vụ phức tạp hơn bằng cách cung cấp hướng dẫn rõ ràng:
Assume that the polarity of a text is a label chosen from {positive, negative,
neutral}. Identify the polarity of the input
Input: I love the food here. It’s amazing!
Polarity: _____"
Prompting này thể hiện khả năng zero-shot learning của LLMs, khi mô hình có thể thực hiện tác vụ mà không cần đào tạo cụ thể cho tác vụ đó. Một phương pháp khác là few-shot learning thông qua in-context learning (ICT). Phương pháp này sử dụng demonstrations (ví dụ mẫu) để hướng dẫn LLMs cách thực hiện tác vụ:
Assume that the polarity of a text is a label chosen from {positive, negative,
neutral}. Identify the polarity of the input.
Input: The traffic is terrible during rush hours, making it difficult to reach the
airport on time.
Polarity: Negative
Input: The weather here is wonderful.
Polarity: Positive
Input: I love the food here. It’s amazing!
Polarity: ____
Prompting và in-context learning đóng vai trò quan trọng trong sự phát triển của LLMs. Mặc dù prompting rất mạnh mẽ, việc fine-tuning vẫn cần thiết để đảm bảo mô hình tuân theo instruction chính xác và alignment với giá trị con người. Các khía cạnh này sẽ được thảo luận chi tiết hơn trong các chương sau.
1.2 Các Tác vụ Pre-training Tự Giám sát (Self-supervised Pre-training Tasks)
Phần này sẽ trình bày về các phương pháp pre-training tự giám sát (self-supervised pre-training approaches) cho các kiến trúc nơ-ron khác nhau, bao gồm kiến trúc chỉ dùng decoder (decoder-only), chỉ dùng encoder (encoder-only) và encoder-decoder, tập trung vào kiến trúc Transformer. Do pre-training là một khái niệm rộng, phần này sẽ giới thiệu ngắn gọn các phương pháp cơ bản.
1.2.1 Pre-training Chỉ Dùng Decoder
Kiến trúc chỉ dùng decoder (decoder-only architecture) được sử dụng rộng rãi trong phát triển các mô hình ngôn ngữ (language models). Ví dụ, Transformer decoder có thể được dùng làm mô hình ngôn ngữ bằng cách loại bỏ các lớp con cross-attention. Mô hình này dự đoán phân phối xác suất của tokens tại một vị trí dựa trên các tokens trước đó , ký hiệu là (hoặc ). Trong language modeling, phân phối chuẩn có thể được xem là biểu diễn one-hot của từ cần dự đoán. Hàm mất mát (loss function) được sử dụng để đo lường sự khác biệt giữa dự đoán của mô hình và thực tế. Cross-entropy loss theo thang logarit (log-scale cross-entropy loss) là lựa chọn phổ biến trong NLP.
Với một chuỗi tokens , loss trên chuỗi này là tổng loss trên các vị trí :
trong đó là biểu diễn one-hot của .
Hàm mất mát này có thể được áp dụng cho một tập hợp các chuỗi . Mục tiêu của pre-training là tối ưu tham số để giảm thiểu tổng loss trên :
Mục tiêu này tương đương với ước tính khả năng hợp lý tối đa (maximum likelihood estimation):
Với tham số tối ưu , mô hình ngôn ngữ pre-trained có thể được sử dụng để tính xác suất tại mỗi vị trí trong chuỗi.
1.2.2 Pre-training Chỉ Dùng Encoder
Encoder nhận chuỗi tokens và tạo ra chuỗi vector . Việc pre-training encoder trực tiếp gặp khó khăn vì đầu ra là vector giá trị thực, không dễ dàng đánh giá chất lượng bằng dữ liệu gold-standard. Một phương pháp phổ biến là kết hợp encoder với các lớp đầu ra (output layers) để thu được tín hiệu giám sát (supervision signals) dễ dàng hơn.
Hình 1.2 minh họa kiến trúc thường dùng cho pre-training Transformer encoders: thêm lớp Softmax lên trên Transformer encoder. Kiến trúc này tạo ra chuỗi phân phối xác suất:
Trong đó là phân phối đầu ra tại vị trí , và thể hiện lớp Softmax được tham số hóa bởi .
Điểm khác biệt giữa mô hình này và mô hình ngôn ngữ tiêu chuẩn là ý nghĩa đầu ra . Trong language modeling, dự đoán từ tiếp theo trong quá trình giải mã tự hồi quy (auto-regressive decoding) chỉ dựa trên các từ trước vị trí . Ngược lại, trong pre-training encoder, toàn bộ chuỗi đầu vào được quan sát đồng thời, nên việc dự đoán một token cụ thể trong chuỗi không mang ý nghĩa tương tự. Hình 1.2 minh họa quá trình pre-training encoder với lớp Softmax và cách encoder pre-trained được ứng dụng trong các tác vụ cụ thể sau khi loại bỏ lớp Softmax và kết hợp với mạng dự đoán (prediction network), thường kèm theo fine-tuning.
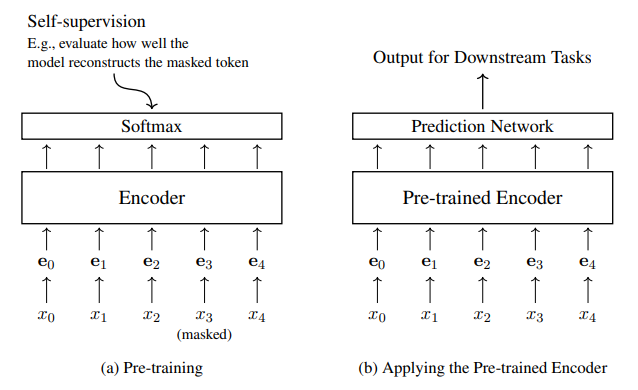
Hình 1.2: Pre-training một Transformer encoder (bên trái) và sau đó áp dụng encoder pre-trained (bên phải). Trong giai đoạn pre-training, encoder, cùng với một lớp Softmax, được đào tạo thông qua tự giám sát (self-supervision). Trong giai đoạn ứng dụng, lớp Softmax bị loại bỏ, và encoder pre-trained được kết hợp với một mạng dự đoán (prediction network) để giải quyết các vấn đề cụ thể. Nói chung, để điều chỉnh tốt hơn cho các tác vụ này, hệ thống được fine-tune bằng cách sử dụng dữ liệu được gán nhãn.
1.2.2.1 Masked Language Modeling
Masked language modeling là một phương pháp pre-training encoder phổ biến, nền tảng của mô hình BERT. Ý tưởng chính là tạo ra bài toán dự đoán bằng cách masking ngẫu nhiên một số tokens trong chuỗi đầu vào và huấn luyện mô hình để dự đoán các tokens bị masked đó.
So với causal language modeling (language modeling thông thường), masked language modeling có điểm khác biệt quan trọng. Trong causal language modeling, mô hình chỉ sử dụng ngữ cảnh bên trái (left-context) để dự đoán từ tiếp theo, trong khi masked language modeling sử dụng cả ngữ cảnh bên trái và bên phải để dự đoán từ bị masked, tạo ra một mô hình hai chiều (bidirectional model).
Cụ thể, với chuỗi đầu vào , một tập hợp vị trí tokens sẽ được chọn để masking. Các tokens tại các vị trí này trong sẽ được thay thế bằng ký hiệu đặc biệt [MASK], tạo thành chuỗi bị masked .
Ví dụ, với chuỗi:
The early bird catches the worm
ta có thể tạo chuỗi bị masked:
The [MASK] bird catches the [MASK]
Mục tiêu là tối ưu hóa mô hình để dự đoán chính xác chuỗi gốc từ chuỗi bị masked . Mục tiêu đào tạo là tối đa hóa xác suất tái cấu trúc , hoặc đơn giản hóa bằng cách tối đa hóa xác suất của các tokens bị masked. Mục tiêu này có thể được biểu diễn dưới dạng maximum likelihood estimation:
hoặc sử dụng cross-entropy loss:
Ví dụ, với chuỗi "the early bird catches the worm" và hai tokens bị masked, loss function sẽ tối đa hóa:
Sau pre-training, lớp Softmax tham số có thể được loại bỏ, và encoder pre-trained có thể được fine-tune hoặc sử dụng trực tiếp cho các tác vụ hạ nguồn.
1.2.2.2 Permuted Language Modeling
Mặc dù masked language modeling (MLM) phổ biến, nó có một số nhược điểm. Thứ nhất, token đặc biệt [MASK] chỉ xuất hiện trong giai đoạn đào tạo (training) mà không có trong giai đoạn kiểm thử (test time), gây ra sự khác biệt giữa đào tạo và suy luận. Thứ hai, MLM bỏ qua sự phụ thuộc giữa các tokens bị masked, ví dụ, các tokens bị masked được dự đoán độc lập với nhau.
Permuted language modeling (PLM) được giới thiệu để giải quyết các vấn đề này. Tương tự như causal language modeling, PLM dự đoán tokens một cách tuần tự, nhưng không theo thứ tự cố định từ trái sang phải. Thay vào đó, PLM cho phép dự đoán tokens theo bất kỳ thứ tự nào. Điểm quan trọng là thứ tự tokens trong văn bản gốc vẫn giữ nguyên, chỉ có thứ tự dự đoán là thay đổi.
Ví dụ, với chuỗi 5 tokens , trong language modeling tiêu chuẩn, thứ tự dự đoán là . Xác suất của chuỗi có thể được mô hình hóa thông qua một quá trình tạo.
Trong permuted language modeling, chúng ta có thể chọn thứ tự khác, ví dụ . Quá trình tạo chuỗi sau đó có thể được biểu thị như sau:
Với thứ tự dự đoán mới này, việc tạo ra một số tokens có thể được điều kiện hóa trên một ngữ cảnh rộng hơn. Ví dụ, khi dự đoán , mô hình xem xét cả ngữ cảnh bên trái () và ngữ cảnh bên phải (). Các embeddings (kết hợp token và positional embeddings) vẫn giữ thông tin về vị trí ban đầu của các tokens. Về mặt hiệu quả, PLM tương tự như masked language modeling ở chỗ chúng ta "mask" và sử dụng các tokens xung quanh () để dự đoán nó.
Việc triển khai permuted language models trên Transformers khá đơn giản. Vì cơ chế self-attention không phụ thuộc vào thứ tự đầu vào, chúng ta không cần sắp xếp lại chuỗi. Thay vào đó, thứ tự hoán vị được thể hiện thông qua việc thiết lập attention masks phù hợp trong self-attention. Ví dụ, để tính , chúng ta vẫn đưa chuỗi theo thứ tự, nhưng sử dụng attention masks để ngăn chặn attention từ đến .
Hình 1.3 so sánh masking self-attention trong causal language modeling, masked language modeling và permuted language modeling để minh họa rõ hơn.

Hình 1.3: So sánh kết quả masking self-attention của causal language modeling, masked language modeling và permuted language modeling. Ô màu xám biểu thị token tại vị trí không chú ý đến token tại vị trí . Ô màu xanh lam biểu thị rằng token tại vị trí chú ý đến token tại vị trí . biểu thị embedding của ký hiệu [MASK], là sự kết hợp của token embedding và positional embedding.
viết ngắn gọn lại, trình bày lại phần nội dung sau bằng markdown, nhưng không được ngắn quá, các thuật ngữ tiếng anh nên được giữ lại, không được bôi đậm chữ tùy tiện:
1.2.2.3 Pre-training Encoders như Classifiers
Một phương pháp pre-training encoder khác là sử dụng các tác vụ classification. Trong học tự giám sát (self-supervised learning), điều này thường được thực hiện bằng cách tạo ra các bài toán classification từ dữ liệu văn bản chưa gán nhãn. Có hai tác vụ phổ biến như sau:
1. Next Sentence Prediction (NSP)
- Ý tưởng: Mục tiêu là huấn luyện encoder nắm bắt mối quan hệ giữa hai câu.
- Quy trình:
- Mô hình được cung cấp hai câu, Sent và Sent .
- Đầu vào được định dạng như sau:
[CLS] Sent $_{A}$ [SEP] Sent $_{B}$ [SEP]. - Encoder xử lý chuỗi đầu vào và tạo ra biểu diễn.
- Lớp Softmax được thêm vào trên biểu diễn của token
[CLS]() để thực hiện binary classification. - Mô hình dự đoán xem Sent có phải là câu tiếp theo của Sent hay không.
- Tạo dữ liệu đào tạo:
- Mẫu tích cực: Sử dụng các cặp câu liên tiếp thực sự từ văn bản.
- Mẫu tiêu cực: Tạo cặp bằng cách ghép một câu Sent với một câu Sent được lấy mẫu ngẫu nhiên từ văn bản.
- Mục tiêu đào tạo: Đào tạo classifier nhị phân để phân biệt mẫu tích cực và tiêu cực. NSP thường được dùng như một loss phụ trợ cho pre-training dựa trên masked language modeling.
![image.png]()

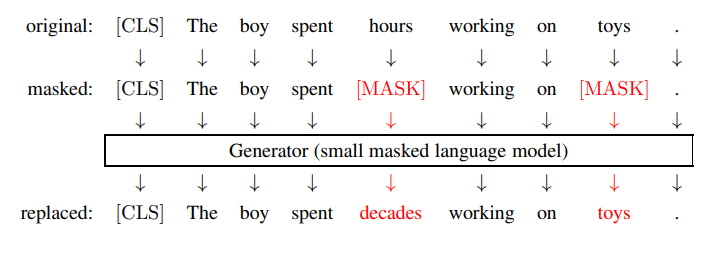
2. Đào tạo Encoder để nhận diện Tokens bị thay thế (ELECTRA-like)
- Ý tưởng: Huấn luyện encoder phân biệt tokens gốc và tokens bị thay thế trong một chuỗi.
- Quy trình:
- Generator: Sử dụng một mô hình masked language nhỏ (generator) để tạo ra một chuỗi mới từ chuỗi đầu vào ban đầu. Generator mask một số tokens ngẫu nhiên và dự đoán tokens thay thế.
![image.png]()
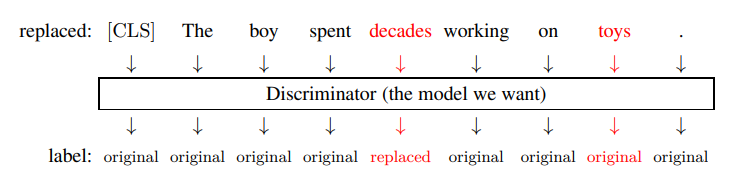
- Discriminator: Một Transformer encoder khác (discriminator) được đào tạo để phân loại từng token trong chuỗi đã được "generator tạo ra" là original (giữ nguyên từ chuỗi gốc) hay replaced (bị thay thế bởi generator).
![image.png]()
- Generator: Sử dụng một mô hình masked language nhỏ (generator) để tạo ra một chuỗi mới từ chuỗi đầu vào ban đầu. Generator mask một số tokens ngẫu nhiên và dự đoán tokens thay thế.
- Mục tiêu đào tạo:
- Generator: Được đào tạo như một masked language model bằng maximum likelihood estimation.
- Discriminator: Được đào tạo như một classifier nhị phân để phân biệt tokens original và replaced bằng cách sử dụng loss dựa trên classification.
- Đào tạo đồng thời: Trong ELECTRA, loss của generator và discriminator được kết hợp để đào tạo đồng thời cả hai mô hình. Có thể sử dụng GANs, nhưng phức tạp hơn và khó mở rộng.
- Ứng dụng sau đào tạo: Sau khi đào tạo, generator bị loại bỏ, và encoder (discriminator) được sử dụng làm mô hình pre-trained cho các tác vụ hạ nguồn.
1.2.3 Pre-training Encoder-Decoder
Kiến trúc encoder-decoder thường được dùng trong NLP cho các bài toán sequence-to-sequence như machine translation và question answering. Mô hình encoder-decoder có thể được mở rộng để xử lý nhiều tác vụ khác bằng cách xem văn bản vừa là đầu vào vừa là đầu ra, tạo ra hệ thống text-to-text đa năng cho mọi bài toán NLP. Ý tưởng là pre-train mô hình encoder-decoder để học kiến thức ngôn ngữ tổng quát (general-purpose knowledge of language) thông qua tự giám sát (self-supervision), sau đó fine-tune cho các tác vụ cụ thể với dữ liệu text-to-text mục tiêu.
1.2.3.1 Pre-training Encoder-Decoder kiểu Masked
Mô hình T5 tiếp cận nhiều tác vụ NLP theo định dạng text-to-text:
Văn bản nguồn bao gồm instruction tác vụ và đầu vào, văn bản đích là phản hồi. Ví dụ, dịch tiếng Trung sang tiếng Anh:
Các tác vụ khác cũng được biểu diễn tương tự, bao gồm cả các bài toán như chấm điểm bản dịch, được chuyển thành bài toán tạo văn bản. Cách tiếp cận này tạo ra một khuôn khổ cho khả năng hiểu và tạo ngôn ngữ phổ quát (universal language understanding and generation), cho phép một mô hình duy nhất thực hiện nhiều tác vụ. Fine-tuning là cần thiết để điều chỉnh mô hình pre-trained cho tác vụ cụ thể, có thể sử dụng instruction ngắn gọn hoặc mô tả chi tiết. Việc biểu diễn instruction bằng văn bản giúp mô hình học kiến thức về instruction trong giai đoạn pre-training, hỗ trợ zero-shot learning.
Các phương pháp self-supervised learning cho Transformer encoders/decoders có thể được áp dụng cho encoder-decoder. Một phương pháp phổ biến là đào tạo encoder-decoder như language models. Ví dụ, encoder nhận tiền tố chuỗi (sequence prefix), decoder tạo chuỗi còn lại (prefix language modeling).
Ví dụ:
Encoder học cách hiểu tiền tố, decoder học cách tiếp tục dựa trên đó. Dữ liệu đào tạo dễ dàng được tạo từ văn bản chưa gán nhãn. Đối với các tác vụ đa ngôn ngữ, mô hình nên được đào tạo trên dữ liệu đa ngôn ngữ để học biểu diễn chung (shared representations) giữa các ngôn ngữ.
Phương pháp thứ hai là masked language modeling. Các tokens trong chuỗi bị mask, và mô hình dự đoán các tokens bị mask này. Ví dụ, masking và tái cấu trúc câu:
Với kiến trúc encoder-decoder, encoder đọc chuỗi bị mask, decoder dự đoán chuỗi gốc, tạo thành denoising autoencoder. Ví dụ:
Mô hình học cách ánh xạ từ chuỗi bị hỏng sang chuỗi gốc, thu được khả năng hiểu (encoder) và tạo (decoder). Có thể mask các tokens liên tiếp (spans), ví dụ:
Sử dụng sentinel tokens như [X], [Y], [Z] để biểu diễn spans bị mask:
Cách này tạo ra chuỗi đào tạo ngắn hơn, hiệu quả hơn. Masked language modeling cung cấp khuôn khổ tổng quát cho đào tạo encoder-decoder, có thể điều chỉnh bằng cách thay đổi tỷ lệ masking và độ dài spans bị mask.
1.2.3.2 Đào tạo Denoising (Denoising Training)
Nếu xem việc đào tạo mô hình encoder-decoder như đào tạo denoising autoencoders, có nhiều phương pháp tạo nhiễu cho đầu vào và tái cấu trúc đầu vào. Mô hình encoder-decoder ánh xạ chuỗi đầu vào thành chuỗi đầu ra :
Trong denoising autoencoding, nhiễu được thêm vào để tạo . Mục tiêu là decoder phải tái tạo lại gốc từ :
Hàm mất mát có thể là cross-entropy loss. Mô hình BART đề xuất các phương pháp làm hỏng (corruption) chuỗi đầu vào khác nhau:
- Token Masking: Masking ngẫu nhiên tokens bằng ký hiệu [MASK] (tương tự masked language modeling).
- Token Deletion: Xóa ngẫu nhiên tokens khỏi chuỗi, thay vì thay thế bằng [MASK]. Ví dụ:
Gốc (x): Những chú chó con đang nô đùa bên ngoài ngôi nhà .
Token Masking ( ): Những chú chó con đang [MASK] bên ngoài [MASK] nhà .
Token Deletion ( ): Những chú chó con đang nô đùa bên ngoài ngôi nhà .
- Span Masking: Masking các spans (đoạn văn bản liên tục) không chồng lấp ngẫu nhiên bằng [MASK]. Span có thể có độ dài 0 (chèn [MASK] vào vị trí). Ví dụ:
Gốc (x): The puppies are frolicking outside the house .
Span Masking ( ): The [MASK] puppies are [MASK] house .
- Sentence Reordering: Hoán vị ngẫu nhiên thứ tự các câu trong một văn bản nhiều câu. Ví dụ:
Gốc: Làm việc chăm chỉ dẫn đến thành công . Thành công mang lại hạnh phúc .
: Thành công mang lại hạnh phúc . Làm việc chăm chỉ dẫn đến thành công .
- Document Rotation: Xoay vòng văn bản sao cho một token được chọn ngẫu nhiên trở thành token đầu tiên. Ví dụ, chọn token "leads":
Gốc: Hard work leads to success . Success brings happiness .
: leads to success . Success brings happiness . Hard work
Pre-training có thể kết hợp nhiều phương pháp làm hỏng, chọn ngẫu nhiên một phương pháp cho mỗi mẫu đào tạo. Hiệu quả pre-training phụ thuộc vào phương pháp làm hỏng, cần lựa chọn mục tiêu đào tạo phù hợp thông qua thử nghiệm.
1.2.4 So sánh các tác vụ Pre-training
Các tác vụ pre-training có thể được phân loại dựa trên mục tiêu đào tạo:
- Language Modeling: Tạo chuỗi tự hồi quy (auto-regressive), dự đoán token tiếp theo dựa trên ngữ cảnh trước đó.
- Masked Language Modeling: Masking ngẫu nhiên tokens và dự đoán chúng dựa trên toàn bộ chuỗi bị masked (khuôn khổ mask-predict).
- Permuted Language Modeling: Tương tự masked language modeling, nhưng thay đổi thứ tự dự đoán token (bị masked) thông qua hoán vị và attention masks. Dự đoán tuần tự dựa trên ngữ cảnh được chọn ngẫu nhiên.
- Discriminative Training: Tạo tín hiệu giám sát từ các tác vụ classification. Mô hình pre-training được tích hợp vào classifiers và đào tạo để cải thiện hiệu suất classification.
- Denoising Autoencoding: Dành cho mô hình encoder-decoder. Đầu vào là chuỗi bị hỏng, mô hình được đào tạo để tái cấu trúc chuỗi gốc.
Bảng 1.1 minh họa các tác vụ này bằng ví dụ và kiến trúc mô hình áp dụng. Các tác vụ pre-training có thể được so sánh trong cùng một khuôn khổ thử nghiệm. Có nhiều tác vụ pre-training khác, độc giả có thể tham khảo các khảo sát chuyên sâu hơn về chủ đề này.
| Phương pháp (Method) | Enc | Dec | E-D | Đầu vào (Input) | Đầu ra (Output) |
|---|---|---|---|---|---|
| Causal LM | The kitten is chasing the ball . | ||||
| Prefix LM | The kitten is | chasing the ball | |||
| Masked LM | The kitten chasing the | _ _ is _ _ ball _ | |||
| MASS-style | The kitten ball . | _ _ is chasing the _ _ | |||
| BERT-style | The kitten playing the | _ kitten is chasing _ ball _ | |||
| Permuted LM | The kitten is chasing the ball . | The kitten is chasing the ball | |||
| Next Sentence Prediction | The kitten is chasing the ball . Birds eat worms . | ||||
| Sentence Comparison | Mã hóa một câu là và một câu khác là | Điểm | |||
| Token Classification | The kitten is chasing the ball . | ||||
| Token Reordering | . kitten the chasing The is ball | The kitten is chasing the ball . | |||
| Token Deletion | The kitten is chasing the ball . | The kitten is chasing the ball . | |||
| Span Masking | The kitten is . | The kitten is chasing the ball . | |||
| Sentinel Masking | The kitten the | is chasing ball | |||
| Sentence Reordering | The ball rolls away swiftly . The kitten is chasing the ball . | The kitten is chasing the ball . The ball rolls away swiftly | |||
| Document Rotation | chasing the ball . The ball rolls away swiftly . The kitten is | The kitten is chasing the ball . The ball rolls away swiftly |
Bảng 1.1: So sánh các tác vụ pre-training, bao gồm language modeling, masked language modeling, permuted language modeling, discriminative training và denoising autoencoding. các tokens sentinel. Enc, Dec và E-D cho biết liệu phương pháp có thể được áp dụng cho các mô hình chỉ dùng encoder, chỉ dùng decoder, encoder-decoder hay không, tương ứng. Đối với các tác vụ tạo, các chỉ số trên được sử dụng để biểu diễn thứ tự của các tokens.
Citations
All rights reserved
