Foundations of Large Language Models: Pre-training phần 2
1.3 Ví dụ: BERT
Trong phần này, chúng ta giới thiệu các mô hình BERT, là một trong những mô hình mã hóa chuỗi pre-trained phổ biến và được sử dụng rộng rãi nhất trong NLP.
1.3.1 Mô hình tiêu chuẩn
Mô hình BERT tiêu chuẩn, được đề xuất trong công trình của Devlin et al. [2019], là một Transformer encoder được đào tạo bằng cả masked language modeling và các tác vụ next sentence prediction. Loss được sử dụng trong đào tạo mô hình này là tổng loss của hai tác vụ.
Như thường lệ trong đào tạo các mạng nơ-ron sâu (deep neural networks), chúng ta tối ưu hóa các tham số mô hình bằng cách giảm thiểu loss này. Để làm điều này, một số mẫu đào tạo được thu thập. Trong quá trình đào tạo, một batch các
mẫu đào tạo được chọn ngẫu nhiên từ bộ sưu tập này tại một thời điểm, và Loss được tích lũy trên các mẫu đào tạo này. Sau đó, các tham số mô hình được cập nhật thông qua gradient descent hoặc các biến thể của nó. Quá trình này được lặp lại nhiều lần cho đến khi một số tiêu chí dừng được đáp ứng, chẳng hạn như khi loss đào tạo hội tụ.
1.3.1.1 Hàm mất mát
Nói chung, các mô hình BERT được sử dụng để biểu diễn một câu đơn hoặc một cặp câu, và do đó có thể xử lý các bài toán hiểu ngôn ngữ hạ nguồn khác nhau. Trong phần này, chúng ta giả định rằng biểu diễn đầu vào là một chuỗi chứa hai câu Sent và Sent , được biểu thị là
Ở đây chúng ta tuân theo ký hiệu trong bài báo của BERT và sử dụng [SEP] để biểu thị dấu phân cách. Cho chuỗi này, chúng ta có thể thu được LossMLM và LossNSP một cách riêng biệt. Đối với masked language modeling, chúng ta dự đoán một tập con của các tokens trong chuỗi. Thông thường, một tỷ lệ phần trăm nhất định của các tokens được chọn ngẫu nhiên, ví dụ, trong mô hình BERT tiêu chuẩn, các tokens trong mỗi chuỗi được chọn. Sau đó, chuỗi được sửa đổi theo ba cách
- Token Masking. các tokens đã chọn bị masked và được thay thế bằng ký hiệu [MASK]. Ví dụ
Gốc: [CLS] Trời đang . [SEP] cần ô . [SEP]
Masked: [CLS] Trời đang [MASK] . [SEP] Tôi cần [MASK] chiếc ô . [SEP]
trong đó các tokens đã chọn được gạch chân. Dự đoán các tokens bị masked khiến mô hình học cách biểu diễn các tokens từ ngữ cảnh xung quanh của chúng.
- Thay thế ngẫu nhiên (Random Replacement). các tokens đã chọn được thay đổi thành một token ngẫu nhiên. Ví dụ,
Gốc: [CLS] Trời đang . [SEP] cần ô . [SEP]
Token ngẫu nhiên: [CLS] Trời đang mưa . [SEP] Tôi cần một chiếc mũ . [SEP]
Điều này giúp mô hình học cách khôi phục một token từ một đầu vào bị nhiễu.
- Không thay đổi (Unchanged). các tokens đã chọn được giữ nguyên không thay đổi.
Đây không phải là một tác vụ dự đoán khó, nhưng có thể hướng dẫn mô hình sử dụng bằng chứng dễ dàng hơn để dự đoán.
Gọi là tập hợp các vị trí đã chọn của một chuỗi token nhất định , và là chuỗi đã sửa đổi của . Hàm mất mát của masked language modeling có thể được định nghĩa là
trong đó là xác suất dự đoán tại vị trí khi biết . Hình 1.5 cho thấy một ví dụ đang chạy về tính toán .
Đối với next sentence prediction, chúng ta tuân theo phương pháp được mô tả trong Phần 1.2.2.3. Mỗi mẫu đào tạo được phân loại vào một tập hợp nhãn {IsNext, NotNext }, ví dụ,
Chuỗi: [CLS] Trời đang mưa . [SEP] Tôi cần một chiếc ô . [SEP]
Nhãn: IsNext
Chuỗi: [CLS] Con mèo ngủ trên подоконнике . [SEP] Táo mọc trên cây . [SEP]
Nhãn: NotNext
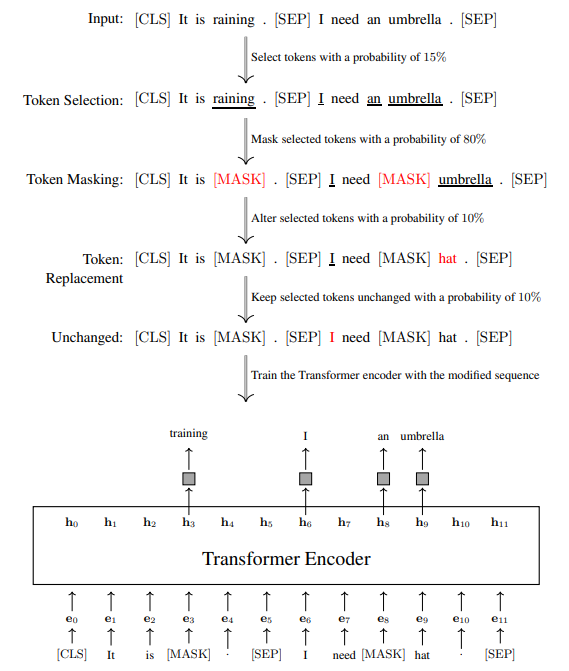
Hình 1.5: Một ví dụ đang chạy về masked language modeling kiểu BERT. Đầu tiên, tokens được chọn ngẫu nhiên. Các tokens đã chọn này sau đó được xử lý theo một trong ba cách: thay thế bằng một token [MASK] ( thời gian), thay thế bằng một token ngẫu nhiên ( thời gian), hoặc giữ nguyên không thay đổi ( thời gian). Mô hình được đào tạo để dự đoán các tokens đã chọn này dựa trên chuỗi đã sửa đổi. biểu diễn embedding của token tại vị trí . Các hộp màu xám biểu diễn các lớp Softmax.
Vectơ đầu ra của encoder cho token đầu tiên [CLS] được xem là biểu diễn chuỗi, được biểu thị bằng (hoặc ). Một classifier được xây dựng trên đỉnh của . Sau đó, chúng ta có thể tính xác suất của một nhãn khi biết , tức là, . Có nhiều hàm mất mát mà người ta có thể chọn cho các bài toán classification. Ví dụ, trong đào tạo khả năng hợp lý tối đa (maximum likelihood training), chúng ta có thể định nghĩa Loss là
trong đó là nhãn chính xác cho mẫu này.
1.3.1.2 Thiết lập mô hình
Như trong Hình 1.6, các mô hình BERT dựa trên kiến trúc Transformer encoder tiêu chuẩn. Đầu vào là một chuỗi các embeddings, mỗi embedding là tổng của token embedding, positional embedding và segment embedding.
Cả token embedding ( ) và positional embedding ( ) đều là tiêu chuẩn, như trong các mô hình Transformer. Segment embedding ( ) là một loại embedding mới cho biết liệu một token thuộc về Sent hay Sent . Điều này có thể được minh họa bằng ví dụ sau.
| Token | [CLS] | It | is | raining | . | [SEP] | I | need | an | umbrella | . | [SEP] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PE(0) | PE(1) | PE(2) | PE(3) | PE(4) | PE(5) | PE(6) | PE(7) | PE(8) | PE(9) | PE(10) | PE(11) | |
Phần chính của các mô hình BERT là một mạng Transformer nhiều lớp. Một lớp Transformer bao gồm một lớp con self-attention và một lớp con FFN. Cả hai đều tuân theo kiến trúc post-norm: output input input , trong đó là hàm cốt lõi của lớp con (hoặc mô hình self-attention hoặc FFN), và là đơn vị layer normalization. Thông thường, một số lớp Transformer được xếp chồng lên nhau để tạo thành một mạng sâu. Tại mỗi vị trí của chuỗi, biểu diễn đầu ra là một vectơ giá trị thực được tạo ra bởi lớp cuối cùng của mạng.
Có một số khía cạnh mà người ta có thể xem xét trong việc phát triển các mô hình BERT.
- Kích thước từ vựng . Trong Transformers, mỗi token đầu vào được biểu diễn dưới dạng một mục trong một từ vựng . Từ vựng lớn có thể bao gồm nhiều biến thể hình thức bề mặt của từ hơn, nhưng có thể dẫn đến tăng yêu cầu về dung lượng lưu trữ.
- Kích thước Embedding . Mọi token đều được biểu diễn dưới dạng một vectơ giá trị thực chiều. Như đã trình bày ở trên, vectơ này là tổng của token embedding, positional embedding và segment embedding, tất cả đều là các vectơ giá trị thực chiều.
- Kích thước ẩn . Đầu vào và đầu ra của một lớp con có kích thước . Bên cạnh đó, hầu hết các trạng thái ẩn của một lớp con là các vectơ chiều. Nói chung, có thể được xem gần đúng là chiều rộng của mạng.
- Số lượng Heads ( ). Trong các lớp con self-attention, người ta cần chỉ định số lượng heads được sử dụng trong multi-head self-attention. Số này càng lớn, càng có nhiều không gian con mà attention được thực hiện. Trong các hệ thống thực tế, chúng ta thường đặt .
- Kích thước ẩn FFN . Kích thước của lớp ẩn của FFNs được sử dụng trong Transformers thường lớn hơn . Ví dụ, một cài đặt điển hình là . Đối với Transformers lớn hơn, chẳng hạn như các mô hình lớn gần đây, có thể được đặt thành một giá trị rất lớn.
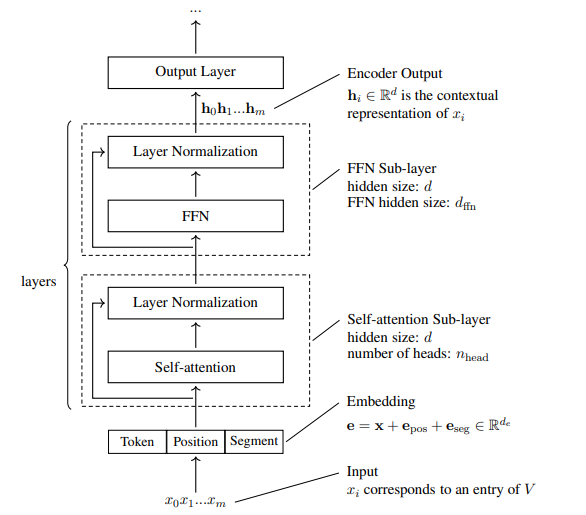
Hình 1.6: Kiến trúc mô hình của BERT (Transformer encoder). Các tokens đầu vào trước tiên được biểu diễn dưới dạng embeddings, mỗi embedding là tổng của token embedding, positional embedding và segment embedding tương ứng. Sau đó, chuỗi embedding được xử lý bởi một stack các lớp Transformer. Mỗi lớp trong stack này bao gồm một lớp con self-attention và một lớp con FFN. Đầu ra của mô hình BERT là một chuỗi các vectơ được tạo ra bởi lớp Transformer cuối cùng.
- Độ sâu mô hình . Sử dụng các mạng sâu là một cách hiệu quả để cải thiện khả năng biểu diễn của Transformers. Đối với các mô hình BERT, thường được đặt thành 12 hoặc 24. Tuy nhiên, các mạng có độ sâu thậm chí lớn hơn cũng khả thi và có thể được áp dụng để tăng cường hơn nữa.
Các cài đặt khác nhau của các hyper-parameters này dẫn đến các kích thước mô hình khác nhau. Có hai mô hình BERT được sử dụng rộng rãi.
- , tổng số tham số .
- , tổng số tham số .
Đào tạo các mô hình BERT tuân theo quy trình đào tạo tiêu chuẩn của Transformers. Đào tạo các mô hình lớn hơn như đòi hỏi nhiều nỗ lực và thời gian đào tạo hơn. Đây là một vấn đề phổ biến đối với pre-training, đặc biệt khi một mô hình được đào tạo trên một lượng dữ liệu rất lớn. Trong thực tế,
thường có những cân nhắc về hiệu quả đào tạo. Ví dụ, một cách thực hành là trước tiên đào tạo một mô hình BERT trên các chuỗi tương đối ngắn trong một số lượng lớn các bước đào tạo, và sau đó tiếp tục đào tạo nó trên các chuỗi có độ dài đầy đủ cho các bước đào tạo còn lại.
1.3.2 Đào tạo nhiều hơn và các mô hình lớn hơn
Sự thành công của BERT đã thúc đẩy các nỗ lực mở rộng mô hình, bao gồm tăng lượng dữ liệu đào tạo và phát triển các mô hình lớn hơn. RoBERTa, một phiên bản mở rộng của BERT, minh họa cho xu hướng này. RoBERTa cho thấy rằng việc sử dụng nhiều dữ liệu đào tạo và tính toán hơn có thể cải thiện đáng kể hiệu suất của BERT mà không cần thay đổi kiến trúc. Ngoài ra, RoBERTa cũng chỉ ra rằng việc loại bỏ loss Next Sentence Prediction (NSP) không làm giảm hiệu suất trên các tác vụ hạ nguồn khi quy mô đào tạo được mở rộng. Những phát hiện này nhấn mạnh rằng việc mở rộng quy mô pre-training trên các tác vụ đơn giản là một hướng đi hiệu quả để cải thiện mô hình.
Một hướng cải tiến khác là tăng số lượng tham số mô hình. Ví dụ, các mô hình BERT với hàng tỷ tham số đã được xây dựng. Tuy nhiên, việc mở rộng quy mô này cũng đặt ra những thách thức mới, như sự không ổn định và khó khăn trong việc hội tụ khi đào tạo các mô hình rất lớn. Đào tạo các mô hình này đòi hỏi sự cân nhắc kỹ lưỡng về kiến trúc, tính toán song song, và khởi tạo tham số. Ví dụ, việc đào tạo một mô hình BERT 3.9 tỷ tham số đã yêu cầu sử dụng hàng trăm GPUs.
1.3.3 Các mô hình hiệu quả hơn
BERT, mặc dù mạnh mẽ, nhưng kích thước lớn gây ra yêu cầu bộ nhớ cao và hiệu suất chậm. Phát triển các phiên bản BERT nhỏ hơn và nhanh hơn là một mục tiêu quan trọng. Các hướng nghiên cứu để tạo ra các mô hình BERT hiệu quả hơn bao gồm:
- Knowledge Distillation: Đào tạo các mô hình "student" nhỏ hơn bằng cách học theo đầu ra của các mô hình "teacher" lớn hơn, đã được đào tạo tốt. Knowledge distillation có thể được áp dụng ở nhiều mức độ biểu diễn khác nhau, bao gồm cả từ lớp đầu ra và các lớp ẩn.
- Model Compression: Áp dụng các kỹ thuật nén mô hình như pruning (cắt tỉa bớt các lớp, tham số, attention heads) và quantization (giảm độ chính xác của tham số mô hình).
- Dynamic Networks: Sử dụng các mô hình động để điều chỉnh độ phức tạp tính toán dựa trên từng đầu vào. Ví dụ, depth-adaptive models cho phép mô hình thoát ra ở độ sâu tối ưu, bỏ qua các lớp còn lại. Length-adaptive models điều chỉnh độ dài chuỗi đầu vào, bỏ qua các tokens ít quan trọng.
- Parameter Sharing: Chia sẻ tham số giữa các lớp để giảm kích thước mô hình. Ví dụ, chia sẻ các tham số của toàn bộ lớp Transformer trên các layer stack.
1.3.4 Các mô hình đa ngôn ngữ
BERT ban đầu tập trung vào tiếng Anh, nhưng sau đó đã được mở rộng sang nhiều ngôn ngữ khác. Multilingual BERT (mBERT) được đào tạo trên dữ liệu từ 104 ngôn ngữ với từ vựng lớn hơn, cho phép các biểu diễn từ các ngôn ngữ khác nhau được ánh xạ vào cùng một không gian, chia sẻ kiến thức giữa các ngôn ngữ.
Các mô hình đa ngôn ngữ rất quan trọng cho cross-lingual learning, khi mô hình được đào tạo trên một ngôn ngữ và áp dụng cho ngôn ngữ khác. Ví dụ, fine-tuning mBERT trên tiếng Anh và sử dụng cho tiếng Trung.
Để cải thiện khả năng cross-lingual, Cross-lingual Language Models (XLMs) được phát triển, sử dụng dữ liệu song ngữ trong pre-training. Translation Language Modeling (TLM) là một phương pháp pre-training cho XLMs, trong đó mô hình được đào tạo trên các cặp câu song ngữ, mask tokens và học cách dự đoán chúng, đồng thời nắm bắt sự tương ứng giữa các ngôn ngữ.
Mô hình đa ngôn ngữ có khả năng xử lý code-switching tự nhiên, do từ vựng chung coi tất cả các tokens như một phần của một ngôn ngữ "mới".
Hiệu suất của pre-training đa ngôn ngữ phụ thuộc vào nhiều yếu tố như kích thước từ vựng, tỷ lệ mẫu ngôn ngữ, kích thước mô hình. Các mô hình lớn hơn và từ vựng lớn hơn cần thiết khi hỗ trợ nhiều ngôn ngữ hơn. Interference có thể xảy ra khi đào tạo quá lâu, làm giảm hiệu suất, do đó có thể cần dừng pre-training sớm.
1.4 Ứng dụng các mô hình BERT
Sau khi một mô hình BERT được pre-trained, nó có thể được sử dụng để giải quyết các vấn đề NLP. Nhưng các mô hình BERT không sẵn sàng ngay lập tức để thực hiện các tác vụ hạ nguồn cụ thể. Nói chung, cần có thêm công việc fine-tuning để làm cho chúng thích ứng. Bước đầu tiên, chúng ta cần một predictor để alignment đầu ra của mô hình với vấn đề quan tâm. Gọi là một mô hình BERT với các tham số pre-trained , và Predict là một mạng dự đoán với các tham số . Bằng cách tích hợp mạng dự đoán với đầu ra của mô hình BERT, chúng ta phát triển một mô hình để giải quyết các tác vụ hạ nguồn. Mô hình này có thể được biểu thị là
trong đó là đầu vào và là đầu ra phù hợp với bài toán. Ví dụ, trong các bài toán classification, mô hình xuất ra một phân phối xác suất trên các nhãn.
Sau đó, chúng ta thu thập một tập hợp các mẫu được gán nhãn , và fine-tune mô hình bằng cách
trong đó biểu diễn một tuple gồm một đầu vào và đầu ra tương ứng của nó. Ký hiệu của phương trình này có vẻ hơi phức tạp, nhưng quá trình đào tạo/điều chỉnh là tiêu chuẩn. Chúng ta tối ưu hóa mô hình bằng cách giảm thiểu loss trên các mẫu điều chỉnh. Kết quả là các tham số tối ưu hóa và . Quá trình tối ưu hóa bắt đầu với các tham số pre-trained . Ở đây chúng ta sử dụng $\hat{\theta}^{+}$để chỉ ra rằng các tham số được khởi tạo bằng , và sử dụng để biểu thị đầu ra mô hình được tính toán bằng cách sử dụng các tham số và .
Với các tham số đã được fine-tune và , chúng ta có thể áp dụng mô hình cho dữ liệu mới của cùng các tác vụ mà mô hình đã được fine-tune. Hình thức của các tác vụ hạ nguồn xác định định dạng đầu vào và đầu ra của mô hình, cũng như kiến trúc của mạng dự đoán. Sau đây, chúng ta liệt kê một số tác vụ mà các mô hình BERT thường phù hợp.
- Classification (Văn bản đơn). Một trong những ứng dụng được sử dụng rộng rãi nhất của các mô hình BERT là text classification. Trong tác vụ này, một mô hình BERT nhận một chuỗi tokens và mã hóa nó thành một chuỗi các vectơ. Vectơ đầu ra đầu tiên (hoặc ) thường được sử dụng làm biểu diễn của toàn bộ văn bản. Mạng dự đoán nhận làm đầu vào để tạo ra một phân phối các nhãn. Gọi là một văn bản đầu vào. Xem bên dưới để biết minh họa về text classification dựa trên BERT.
![image.png]()
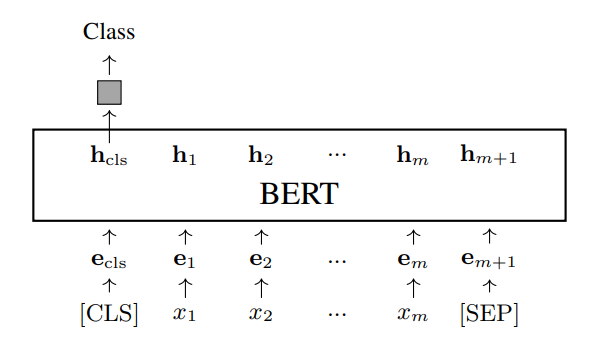
Ở đây hộp màu xám biểu thị mạng dự đoán. Nhiều bài toán NLP có thể được phân loại là các tác vụ text classification, và đã có một số benchmarks text classification để đánh giá các mô hình pre-trained. Ví dụ, chúng ta có thể phân loại văn bản theo tính đúng ngữ pháp của chúng (grammaticality) hoặc tông giọng cảm xúc (sentiment). Lưu ý rằng mạng dự đoán có thể là bất kỳ mô hình classification nào, chẳng hạn như mạng nơ-ron sâu hoặc một mô hình classification truyền thống hơn. Toàn bộ mô hình sau đó có thể được đào tạo hoặc fine-tune theo kiểu của một mô hình classification tiêu chuẩn. Ví dụ, mạng dự đoán có thể chỉ đơn giản là một lớp Softmax và các tham số mô hình có thể được tối ưu hóa bằng cách tối đa hóa xác suất của các nhãn chính xác.
- Classification (Cặp văn bản). Classification cũng có thể được thực hiện trên một cặp văn bản. Giả sử chúng ta có hai văn bản, và . Chúng ta có thể nối các văn bản này để tạo thành một chuỗi duy nhất có độ dài len. Sau đó, chúng ta dự đoán một nhãn cho chuỗi văn bản kết hợp này dựa trên vectơ , như sau
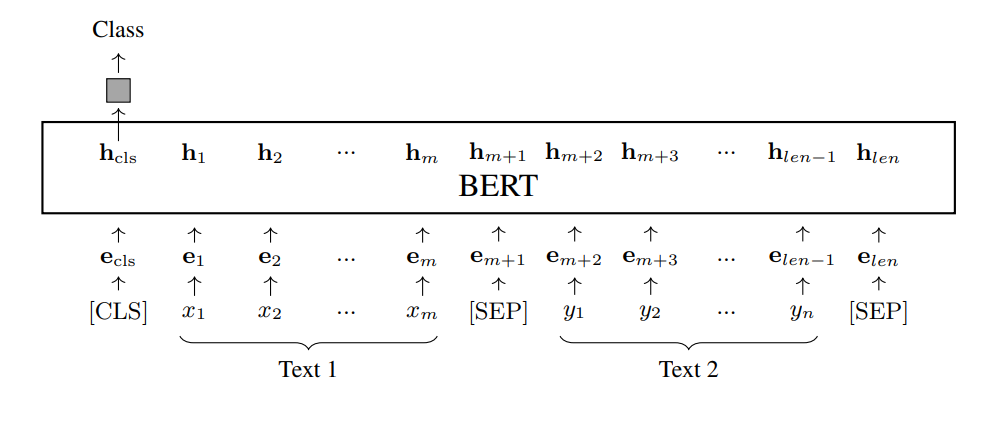
trong đó len . Text pair classification bao gồm một số vấn đề, bao gồm phán đoán semantic equivalence (xác định xem hai văn bản có tương đương về mặt ngữ nghĩa hay không), phán đoán text entailment (xác định xem một giả thuyết có thể được suy luận hoặc kéo theo một cách logic từ một tiền đề hay không), grounded commonsense inference (xác định xem một sự kiện có khả năng xảy ra hay không khi biết ngữ cảnh của nó) và question-answering inference (xác định xem một câu trả lời có tương ứng với một câu hỏi nhất định hay không).
- Regression. Thay vì tạo ra một phân phối nhãn, chúng ta có thể yêu cầu mạng dự đoán xuất ra một điểm số giá trị thực. Ví dụ, bằng cách thêm một lớp Sigmoid vào mạng dự đoán, hệ thống có thể được sử dụng để tính toán mức độ tương đồng giữa hai câu cho trước. Kiến trúc giống với kiến trúc của các hệ thống classification dựa trên BERT, chỉ có sự thay đổi của lớp đầu ra.
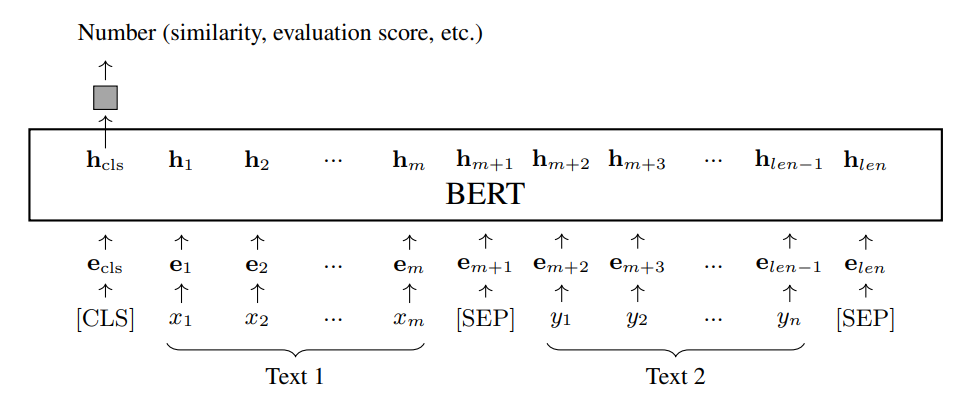
Để đào tạo hoặc fine-tuning, chúng ta có thể giảm thiểu loss hồi quy của đầu ra mô hình như thường lệ.
- Sequence Labeling. Sequence labeling là một phương pháp machine learning có thể áp dụng cho một loạt các bài toán NLP. Phương pháp này gán một nhãn cho mỗi token trong một chuỗi đầu vào, và một số chú thích ngôn ngữ sau đó có thể được suy ra từ chuỗi nhãn này. Một ví dụ về sequence labeling trong NLP là part-of-speech (POS) tagging. Chúng ta gán nhãn cho mỗi từ trong một câu bằng POS tag tương ứng của nó. Một ví dụ khác là named entity recognition (NER), trong đó chúng ta gán nhãn cho mỗi từ bằng NER tag, và các named entities được xác định bằng cách sử dụng các tags này. Xem bên dưới để biết minh họa về kiến trúc mô hình cho NER.
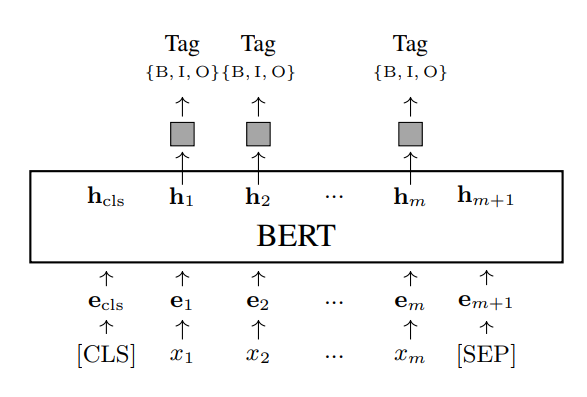
Ở đây là tập hợp tags của NER. Ví dụ, B-ORG có nghĩa là bắt đầu của một tổ chức, I-ORG có nghĩa là từ nằm trong một tổ chức, và O có nghĩa là từ không thuộc bất kỳ named entity nào. Mô hình NER này có thể xuất ra một phân phối trên tập hợp tags tại mỗi vị trí, được biểu thị là . Việc đào tạo hoặc fine-tuning mô hình có thể được thực hiện trên các phân phối này . Ví dụ, giả sử là xác suất của tag chính xác tại vị trí . Loss đào tạo có thể được định nghĩa là negative likelihood
Tìm chuỗi nhãn tốt nhất khi biết một mô hình NER đã được đào tạo là một vấn đề được nghiên cứu kỹ lưỡng trong NLP. Điều này thường đạt được thông qua dynamic programming, trong bối cảnh tìm đường đi trên một lattice, có độ phức tạp tuyến tính.
- Span Prediction. Một số tác vụ NLP yêu cầu dự đoán một span trong một văn bản. Một ví dụ phổ biến là reading comprehension. Trong tác vụ này, chúng ta được cung cấp một truy vấn và một văn bản ngữ cảnh . Mục tiêu là xác định một span liên tục trong trả lời truy vấn tốt nhất. Bài toán này có thể được đóng khung như một tác vụ giống như sequence labeling, trong đó chúng ta dự đoán một nhãn cho mỗi để cho biết sự bắt đầu hoặc kết thúc của span. Chúng ta thêm hai mạng lên trên đầu ra BERT cho : một mạng để tạo ra xác suất là điểm bắt đầu của span (được biểu thị bằng ), và một mạng để tạo ra xác suất là điểm kết thúc của span (được biểu thị bằng ). Kiến trúc mô hình thu được được hiển thị như sau
![image.png]()
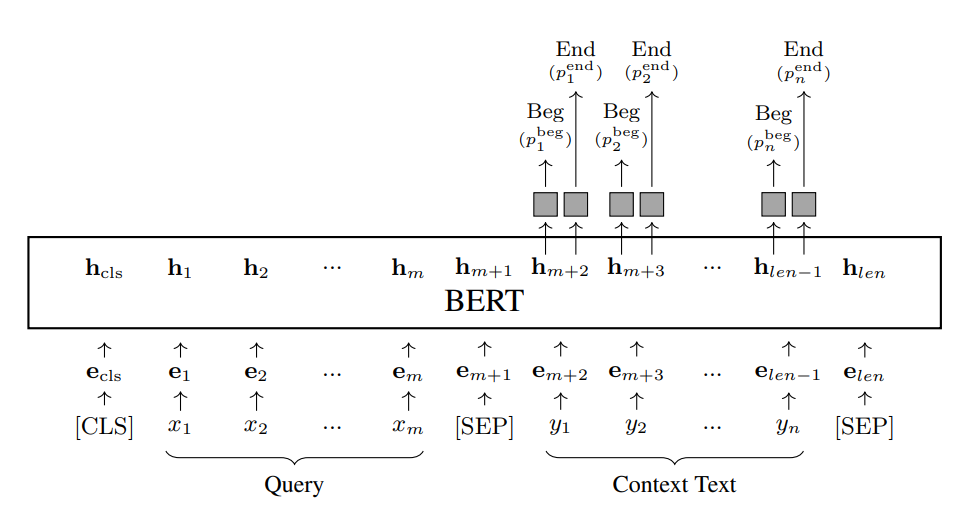
Chúng ta đóng gói truy vấn và văn bản ngữ cảnh lại với nhau để thu được chuỗi đầu vào. Các mạng dự đoán chỉ được áp dụng cho đầu ra cho văn bản ngữ cảnh, tạo ra các xác suất và tại mỗi vị trí. Loss có thể được tính bằng cách cộng tổng log likelihoods của hai mô hình trên toàn bộ văn bản ngữ cảnh.
Tại thời gian kiểm thử, chúng ta tìm kiếm span tốt nhất bằng cách
- Mã hóa cho các mô hình Encoder-decoder. Mặc dù trọng tâm của chúng ta trong phần này chủ yếu là vào các bài toán hiểu ngôn ngữ, nhưng cần lưu ý rằng các mô hình BERT có thể được áp dụng cho một phạm vi rộng hơn các tác vụ NLP. Trên thực tế, các mô hình BERT có thể được sử dụng trong tất cả các kịch bản mà chúng ta cần mã hóa một đoạn văn bản. Một ứng dụng mà chúng ta chưa đề cập đến là text generation, bao gồm một loạt các tác vụ như machine translation, summarization, question answering và dialogue generation. Các tác vụ này có thể được xây dựng thành các bài toán sequence-to-sequence: chúng ta sử dụng một encoder để biểu diễn văn bản nguồn và một decoder để tạo ra văn bản đích tương ứng. Một phương pháp đơn giản để áp dụng các mô hình BERT là coi chúng như encoders. Trước khi fine-tuning, chúng ta có thể khởi tạo các tham số của encoder bằng các tham số từ mô hình BERT pre-trained. Sau đó, mô hình encoder-decoder có thể được fine-tune trên các cặp văn bản như thường lệ. Sau đây cho thấy kiến trúc của một hệ thống neural machine translation, trong đó một mô hình BERT được áp dụng ở phía nguồn.
![image.png]()
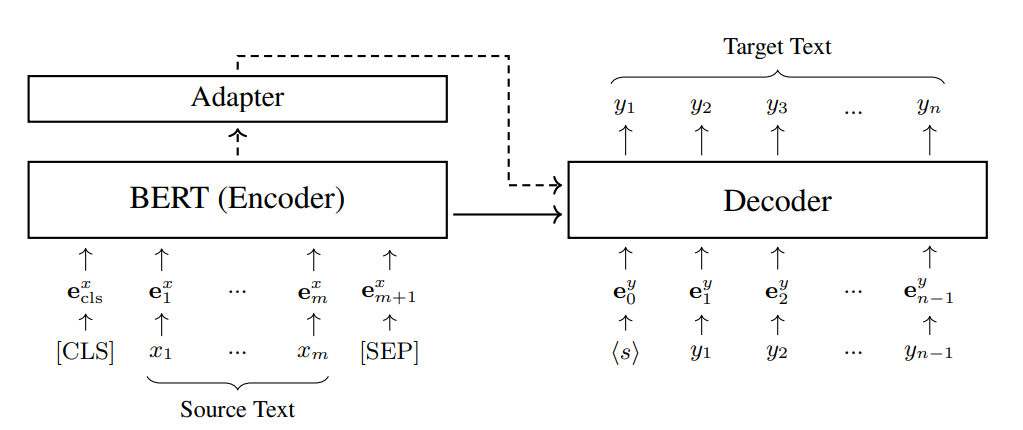
Ở đây biểu thị chuỗi nguồn, biểu thị chuỗi đích, biểu thị chuỗi embedding của , và biểu thị chuỗi embedding của . Adapter, là tùy chọn, ánh xạ đầu ra của mô hình BERT sang dạng phù hợp hơn với decoder.
Fine-tuning các mô hình BERT là một vấn đề kỹ thuật phức tạp, bị ảnh hưởng bởi nhiều yếu tố, chẳng hạn như lượng dữ liệu fine-tuning, kích thước mô hình và optimizer được sử dụng trong fine-tuning. Nói chung, chúng ta muốn fine-tune các mô hình này một cách đầy đủ để chúng có thể hoạt động tốt trong các tác vụ hạ nguồn. Tuy nhiên, fine-tuning các mô hình BERT cho các tác vụ cụ thể có thể dẫn đến overfitting,
điều này đến lượt nó làm giảm khả năng tổng quát hóa của chúng cho các tác vụ khác. Ví dụ, giả sử chúng ta có một mô hình BERT hoạt động tốt trên một tác vụ cụ thể. Nếu sau đó chúng ta fine-tune nó cho các tác vụ mới, điều này có thể làm giảm hiệu suất của nó trên tác vụ ban đầu. Vấn đề này liên quan đến vấn đề catastrophic forgetting trong continual training, trong đó một mạng nơ-ron quên thông tin đã học trước đó khi được cập nhật trên các mẫu mới. Trong các ứng dụng thực tế, một cách phổ biến để giảm bớt catastrophic forgetting là thêm một số dữ liệu cũ vào fine-tuning và đào tạo mô hình với dữ liệu đa dạng hơn. Ngoài ra, người ta có thể sử dụng các phương pháp chuyên biệt cho catastrophic forgetting, chẳng hạn như experience replay và elastic weight consolidation . Bạn đọc quan tâm có thể tham khảo một số khảo sát để thảo luận chi tiết hơn về vấn đề này trong continual learning.
All rights reserved
