[GPU in AI] Bài 4: cuML cho bài toán ML
Ở bài trước chúng ta đã tìm hiểu cách sử dụng GPU để xử lí data bằng cuDF thì ở bài này mình sẽ hướng dẫn các bạn dùng cuML để xử lí các bài toán ML bằng GPU
Trước khi đi vào bài hôm nay mình sẽ trả lời câu hỏi của bài trước: Qua các bức ảnh trên tại sao total time không bằng tổng time của CPU và GPU ? : đó là do profile sẽ không tính thời gian copy data từ CPU <---> GPU
cuML
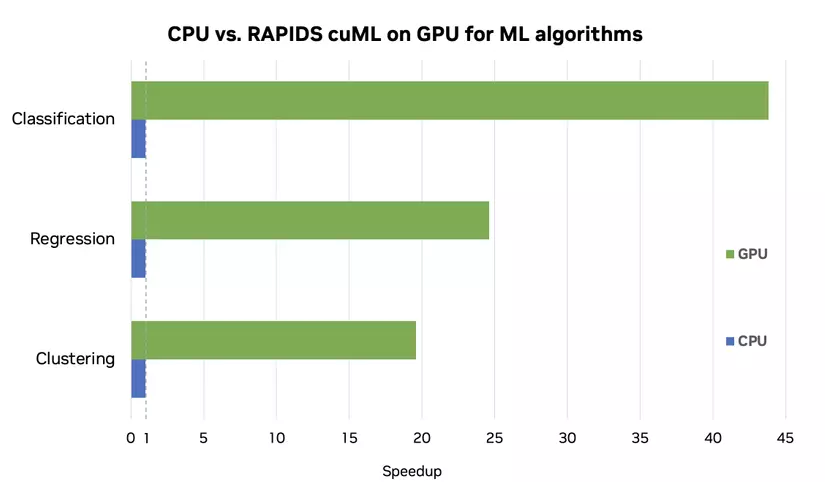
Như mình đã trình bày ở bài 2 thì cuML là 1 trong những thư viện của RAPIDS, nó giúp chúng ta có thể sử dụng các model ML ở GPU 1 cách dễ dàng với syntax hoàn toàn giống với sklearn
Code
Đầu tiên chúng ta cũng phân tích các bước cơ bản data
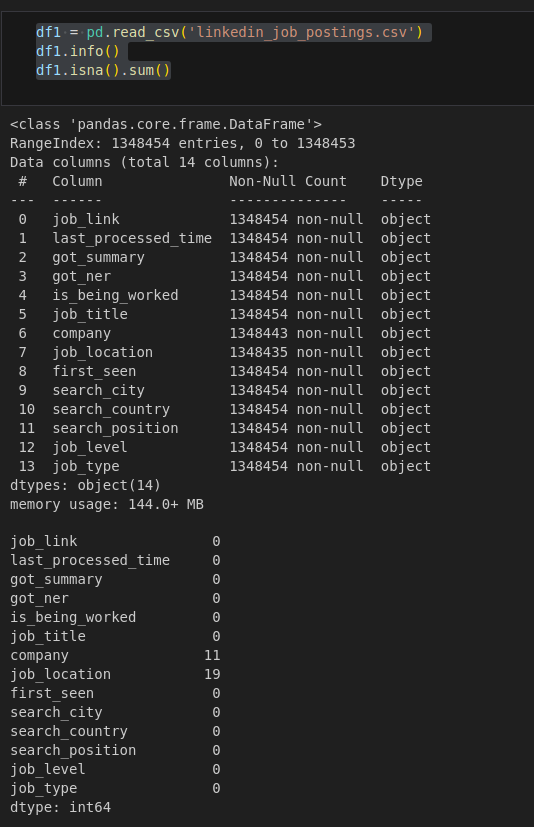
Tại đây chúng ta thấy là toàn bộ dữ liệu đều là object và có 1 số cột bị missing value
Bây giờ là lúc để so sánh tốc độ giữa CPU và GPU khi chúng ta xử lí full từ processing data cho tới build model và cho đến khi dự đoán ra kết quả
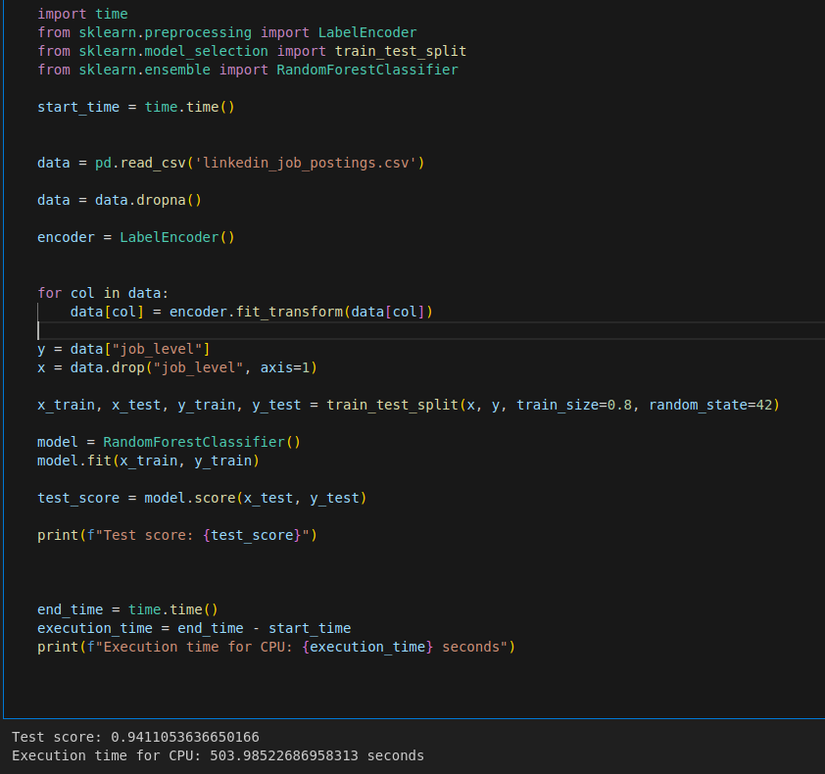
CPU
GPU
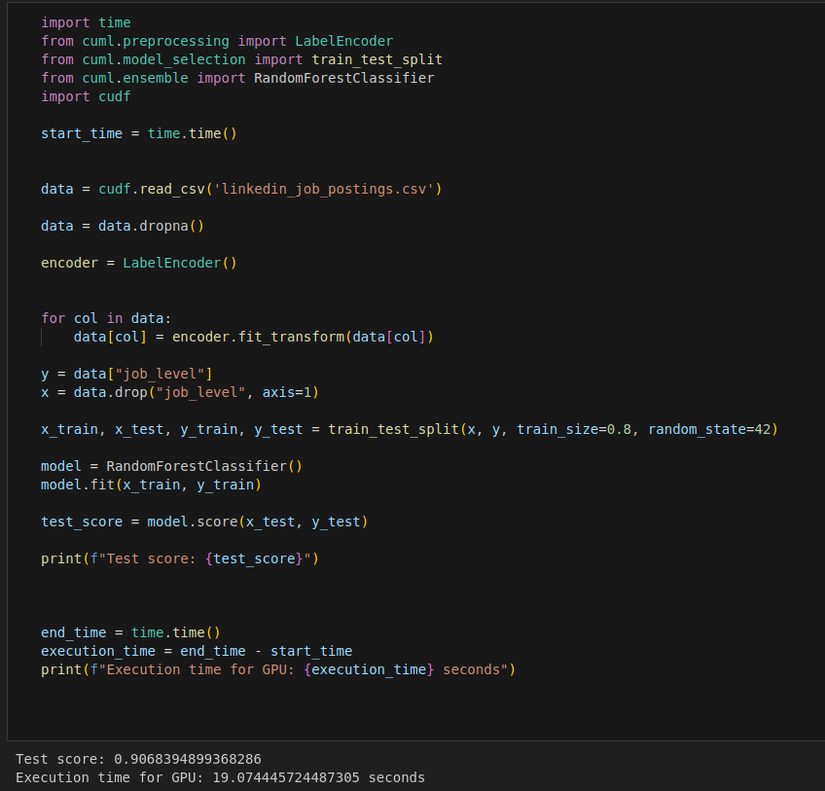
Như các bạn có thể thấy thì gần như chúng ta không hề thay đổi bất kì đoạn code nào ( chỉ thay đổi nhỏ ở khúc import thư viện: sklearn ---> cuml ) mà tốc độ xử lí đã tăng lên 26 lần NHƯNG ở đây accuracy đã bị giảm đôi chút là vì khi chúng ta sử dụng cuML thì datatype của chúng ta sẽ được map về unit8 - unit16 - unit32 nhằm mục đích tăng tốc độ xử lí cũng như giảm bộ nhớ.
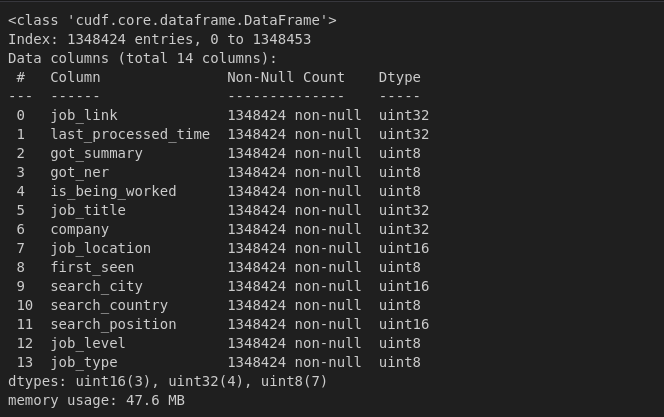
1 lưu ý ở đây là cuML không chỉ đơn thuần chuyển đổi dữ liệu về unit8 - unit16 - unit32 theo bình thường mà họ có áp dụng kĩ thuật quantization - kĩ thuật có thể giúp chúng ta giảm số bit khi lưu trữ dữ liệu nhưng kết quả thay đổi không đáng kể.
Cụ thể hơn bạn có thể thấy lúc đầu chúng ta cần memory usage: 144.0+ MB nhưng khi qua cuML thì chỉ còn memory usage: 47.6 MB
Ở bài toán ML thì mình sẽ không đi sâu về kĩ thuật quatization này, nhưng ở các bài viết sau khi áp dụng GPU cho DL thì mình sẽ nói rõ hơn
Qua đây chúng ta có thể thấy rằng tốc độ xử lí của GPU rất kinh khủng và cũng rất dễ dàng để sử dụng NHƯNG không phải lúc nào chúng ta cũng nên sử dụng GPU là vì:
Để sử dụng GPU thì dữ liệu của chúng ta phải được copy từ CPU ( hay còn gọi là host ) về GPU ( hay còn gọi là device ) vậy nên nếu dữ liệu của chúng ta quá ít thì việc copy qua lại giữa CPU - GPU cũng là 1 vấn đề lớn nên chúng ta phải cân nhắc và dùng GPU cho bài toán ML chỉ khi chúng ta gặp dữ liệu lớn
Ở đây thì thế nào là dữ liệu lớn - bé, tại vì mỗi máy tính của chúng ta có tốc độ xử lí khác nhau nên có thể đối với mình là lớn nhưng có thể đối với các bạn là bé thì ở đây có 2 cách:
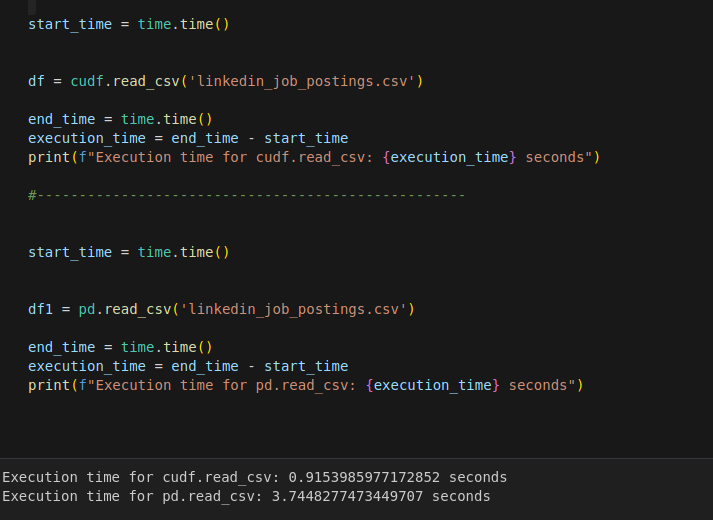
1: chúng ta đơn giản là đọc file csv bằng CPU - GPU rồi so sánh nếu như có sự chênh lệch lớn thì dùng GPU còn không thì CPU
2: chúng ta sẽ phân tích đoạn code bằng các công cụ của NVIDIA để xác định xem liệu chọn GPU có phù hợp hay không. Nếu các bạn chưa biết cách sử dụng các công cụ của NVIDIA thì có thể xem qua tại đây
All rights reserved
