[GPU in AI] Bài 5: autoML - cuDF
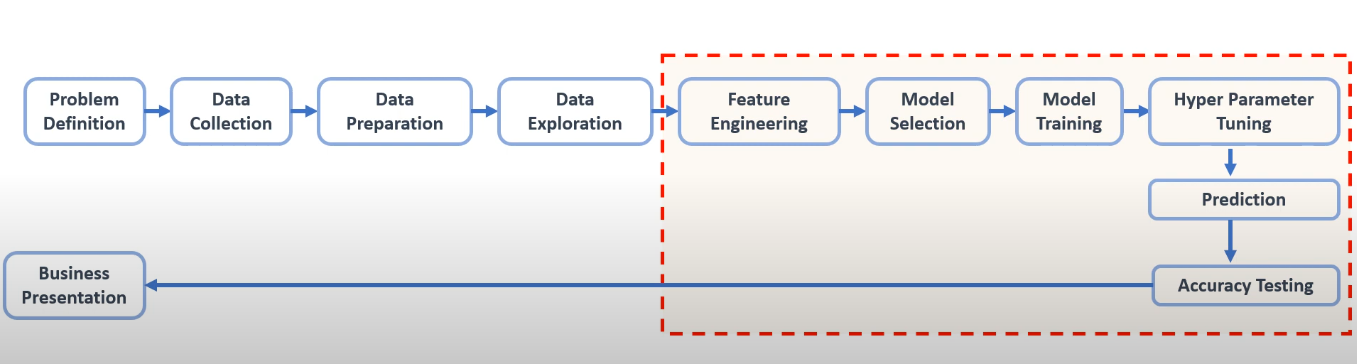
Đây là một pipeline hoàn chỉnh của quy trình phát triển một model Machine Learning. Ở bài viết này chúng ta sẽ tập trung vào các tasks trong ô vuông màu đỏ gồm: Feature Engineering, Model Selection, Model Training và Hyperparameter Tuning.
Một trong những thách thức lớn nhất là tìm ra mô hình tối ưu với các siêu tham số (hyper-parameters) phù hợp nhất cho bài toán. Quá trình này thường tốn nhiều thời gian và công sức, đòi hỏi thử nghiệm nhiều phương pháp khác nhau để đạt được hiệu suất tốt nhất.
Ở đây sẽ có 2 kĩ thuật mà chúng ta quá đỗi quen thuộc:
- Lazypredict: chỉ tìm được các mô hình với các tham số mặc định.
- GridSearchCV / RandomSearchCV: giúp tìm các hyper-parameters nhưng phải thực hiện thủ công.
=> Lazypredict + GridSearchCV: rất chậm và không chính xác.
-
Lý do chậm: Sau khi sử dụng lazypredict để chọn các mô hình hàng đầu, chúng ta lại sử dụng GridSearchCV để tìm các hyper-parameters cho từng mô hình, điều này mất rất nhiều thời gian (vì thuật toán của GridSearchCV là vòng lặp nên càng nhiều hyper-parameters thì càng lâu).
-
Lý do không chính xác: Chúng ta dễ ngộ nhận rằng các mô hình hàng đầu của lazypredict sẽ tiếp tục tốt khi có các hyper-parameters tối ưu. Tuy nhiên, có thể các mô hình không phải là hàng đầu với tham số mặc định, nhưng nếu kết hợp với hyper-parameters thích hợp, chúng sẽ đạt hiệu quả cao hơn.
Vậy nên ở bài viết này mình sẽ hướng dẫn các bạn cách tìm model với hyper-parameters tốt nhất cho bài toán của chúng ta và kết hợp với GPU để tăng tốc độ xử lí
TPOT AutoML

TPOT (Tree-based Pipeline Optimization Tool) là một công cụ tối ưu hóa pipeline dựa trên cây. Có thể hiểu đơn giản là TPOT kết hợp giữa Lazypredict và GridSearchCV, nhưng thay vì tìm kiếm một cách ngẫu nhiên hoặc tuần tự như GridSearchCV, TPOT sử dụng thuật toán genetic programming (lập trình di truyền) để tối ưu hóa mô hình.
Thuật toán genetic programming có thể được hiểu như một quá trình học tập dựa trên sự kế thừa và phát triển từ các thế hệ trước. Để dễ hình dung mình sẽ lấy 1 ví dụ, hãy xem xét một cuộc thi với nhiều vòng loại:
- Ở mỗi vòng, những ứng viên yếu sẽ bị loại bỏ, trong khi các ứng viên tốt hơn tiếp tục được chọn.
- Càng nhiều vòng loại, chất lượng ứng viên được chọn càng cao.
- Tuy nhiên, nếu có quá nhiều vòng loại, có thể dẫn đến việc không còn ứng viên nào đủ điều kiện, khiến quá trình tối ưu hóa không đạt kết quả mong muốn.
Đây chính là cách genetic programming vận hành trong TPOT: nó liên tục cải tiến mô hình bằng cách chọn lọc, biến đổi và kết hợp những mô hình tốt nhất qua nhiều thế hệ để tìm ra cấu trúc tối ưu và toàn bộ quá trình này đều auto hết.
Code
Ở đây mình dùng phiên bản TPOT nên bước processing data sẽ phải làm, còn nếu các bạn dùng TPOT2 (alpha) thì nó sẽ xử lí cho các bạn lun.
Cách dùng TPOT cũng rất đơn giản
import cudf
from cuml.preprocessing import LabelEncoder
from tpot import TPOTClassifier
data = cudf.read_csv('/kaggle/input/1-3m-linkedin-jobs-and-skills-2024/linkedin_job_postings.csv')
data = data.dropna()
encoder = LabelEncoder()
for col in data:
data[col] = encoder.fit_transform(data[col])
y = data["job_level"]
x = data.drop("job_level", axis=1)
x_train, x_test, y_train, y_test = train_test_split(x, y,train_size=0.75, test_size=0.25)
tpot=TPOTClassifier( generations=3,
population_size=2,
config_dict="TPOT cuML",
memory='auto',
scoring='roc_auc',
max_time_mins=40,
cv=2,
verbosity=2)
tpot.fit(x_train.to_numpy(), y_train.to_numpy())
print(tpot.score(x_test.to_numpy(), y_test.to_numpy()))
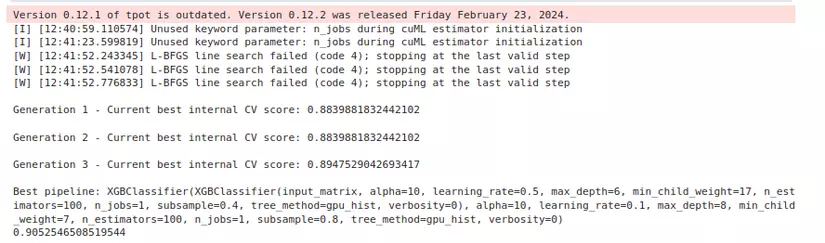
Chỉ với vài thao tác đơn giản chúng ta đã tìm ra được model với hyper-parameters phù hợp nhất và kết hợp với cuDF để chạy trên GPU để tăng tốc độ, ở đây mình sẽ giải thích 1 tí về code:
Lưu ý là ở đây để dùng được TPOT thì chúng ta phải chuyển datatype về numpy ( nhưng code chúng ta vẫn sẽ hoạt động ổn ở GPU về cuML linh hoạt trong datatype nên numpy vẫn xử lí được)
- generations: Số vòng loại trong cuộc thi, tức là số thế hệ mà thuật toán di truyền sẽ chạy để cải thiện mô hình. Càng nhiều thế hệ, mô hình có thể được tối ưu hóa tốt hơn, nhưng cũng tiêu tốn nhiều tài nguyên tính toán hơn.
- population_size: Số lượng mô hình tham gia vào quá trình tìm kiếm hyper-parameters trong mỗi thế hệ. Giá trị này càng lớn thì thuật toán càng có nhiều lựa chọn để chọn lọc và phát triển các mô hình tốt hơn.
Lưu ý khi dùng cuDF đọc file
data_cpu = pd.read_csv('/kaggle/input/student-score/StudentScore.xls')
print(data_cpu.info())
data_gpu = cudf.read_csv('/kaggle/input/student-score/StudentScore.xls')
print(data_gpu.info())
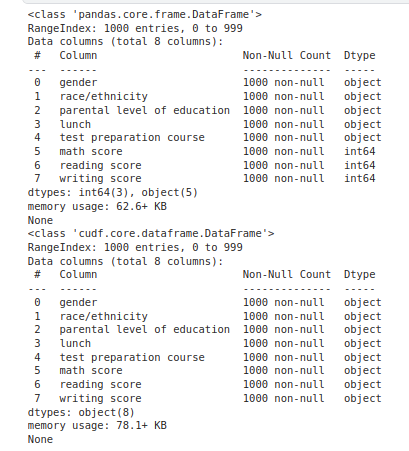
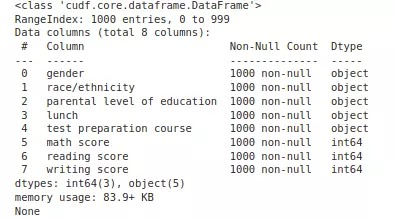
Bạn có thể thấy là cột math score, reading score, writing score bị convert sang object
Cách xử lí
1. Đọc pandas rồi convert về cuDF
data = pd.read_csv("/kaggle/input/student-score/StudentScore.xls")
data = cudf.DataFrame.from_pandas(data)
print(data.info())
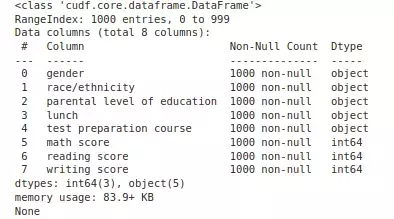
2. Chỉ cụ thể datatype khi đọc file bằng cuDF
dtype_mapping = {
"Math Score": "int64",
"Reading Score": "int64",
"Writing Score": "int64"
}
data_gpu = cudf.read_csv('/kaggle/input/student-score/StudentScore.xls', dtype=dtype_mapping)
print(data_gpu.info())
All rights reserved
