KUBERNETES (On-Premise) : FAILED TO CREATE SANDBOX

Đây là 1 trong những lỗi kinh điển trong quá trình vận hành K8s.
Có rất nhiều nguyên nhân gây ra lỗi này mình có thể kể ra như sau :
- Image Pull lỗi
- Conflict port (port 10250/10257/10259...)
- Không đủ tài nguyên (RAM/CPU)
- container runtime lỗi (containerd, CRI-O, Docker)
- CNI lỗi hoặc mạng không được cấu hình
- SELinux / AppArmor chặn truy cập -> Lỗi này phổ biến nếu ta build trên hệ thống dùng SELinux (CentOS, RHEL) và thường xuất hiện log : connect() failed (13: Permission denied)
Nhưng hôm nay, mình sẽ giới thiệu 1 nguyên nhân khác, và cũng nhiều người gặp khi vận hành K8s trên môi trường On Premise.
Số là cách đây 2 tháng mình có vác 1 con server cũ về để dựng homelab với những thông số sau :


Sau đó mình dựng cụm K8s, tất cả đều chạy trên Ubuntu 22.04


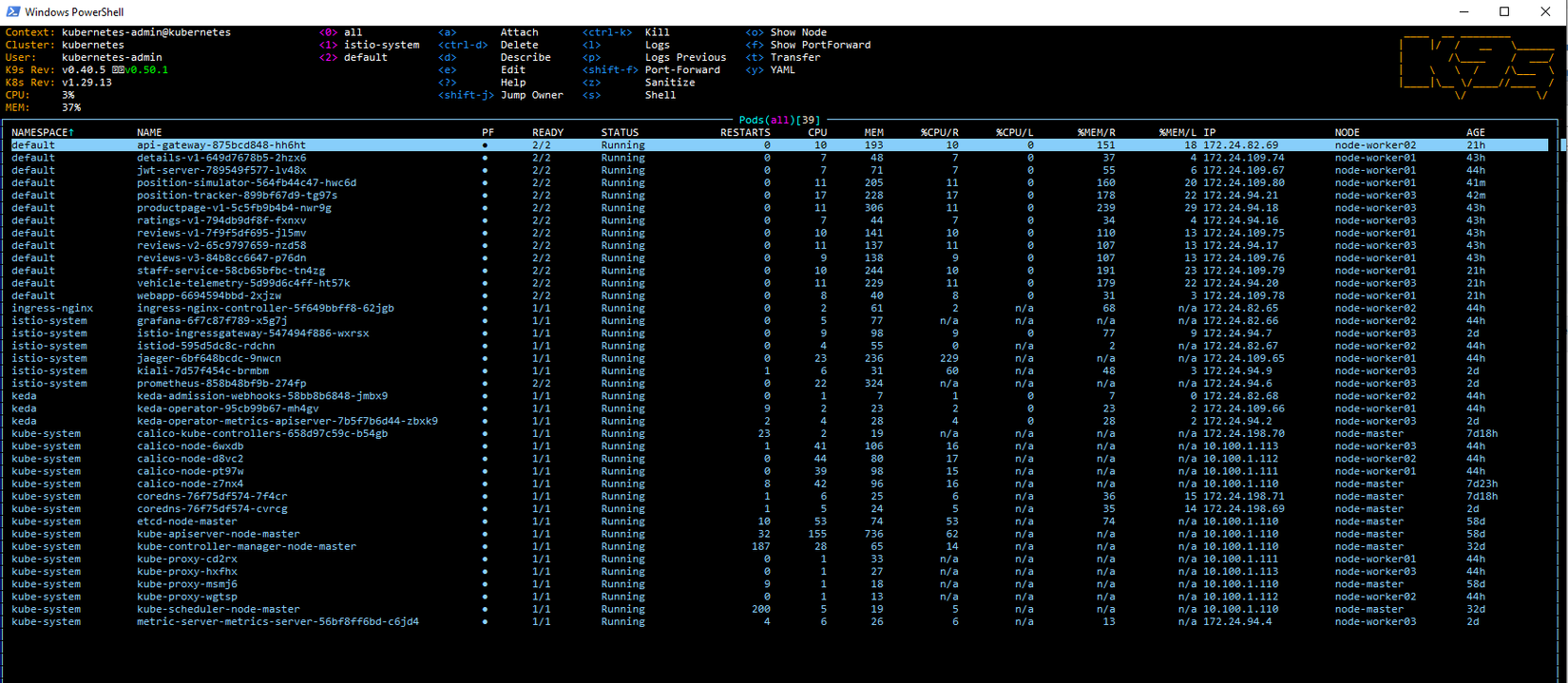
Ứng dụng của mình bao gồm :
- 1 app checking vị trí của xe giao hàng.
- 1 app bookinfo example của Istio
- 1 example về jwt-server


Và những tool để tracing, monitor như:
- Kiali
- Jaeger
- Prometheus
- Grafana
![image.png]()
![image.png]()
![image.png]()
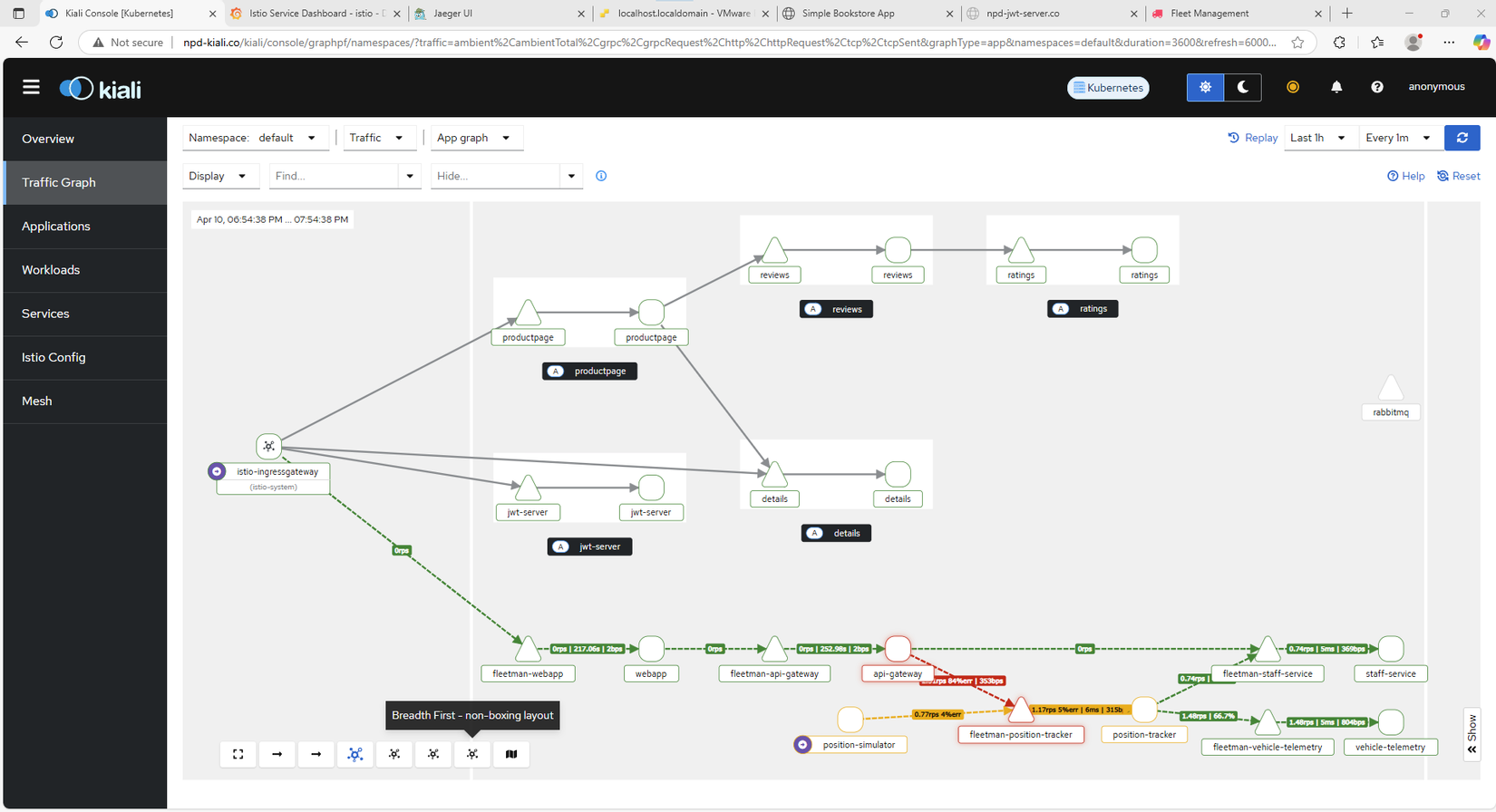
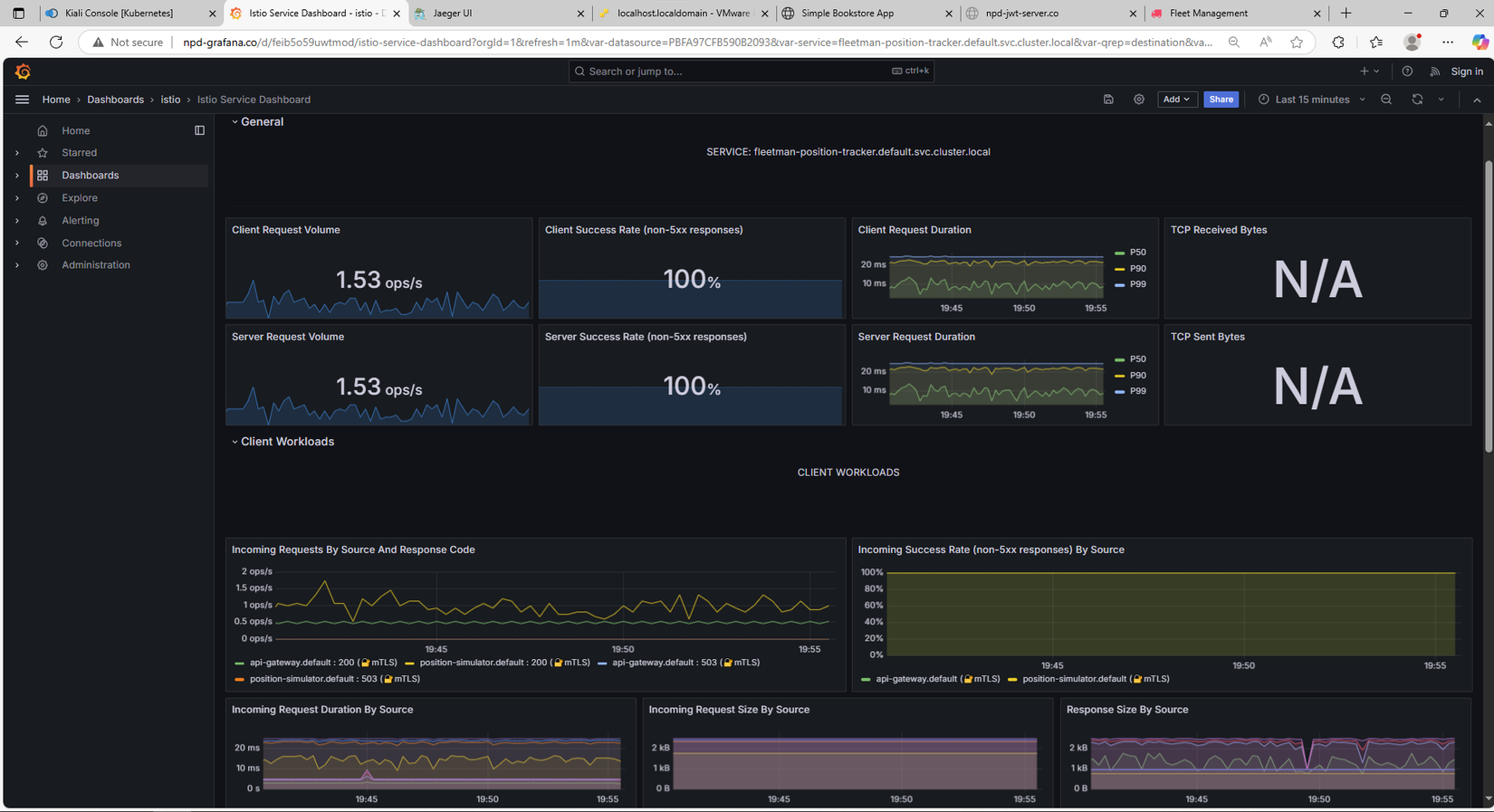
Sau 1 khoảng thời gian sử dụng, mình cảm nhận là dường như cụm K8s của mình khá là chậm, CPU của từng VMs đều có dấu hiệu tăng bất thường, mặc dù k chạy gì nhưng nó luôn vọt lên tầm 40-50% rồi lại hạ xuống về mức dưới 10%.
Khi ssh vào các VMs đều cảm giác khá là chậm.
Khi nào mình k dùng, thì mình hay tắt vào cuối tuần, đầu tuần sẽ bật lên để làm việc.
Nhưng quá trình khởi động cả cụm, khởi tạo các pod thường xuyên mất đến 20-30p, đặc biệt là những pods của Calico như calico-kube-controllers, calico-node, các pods của ArgoCD, Keda.
Và đặc biệt trong quá trình khởi tạo lại, thì pods kube-api, kube-scheduler, kube-controller thường xuyên bị Crashloopbackoff, error
 Và số lần phải restart ngày càng nhiều.
Và số lần phải restart ngày càng nhiều.
Rồi 1 ngày đẹp trời
Sau khi bật lại cụm K8s, thì pods calico báo lỗi như sau :
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to mount container k8s_POD_calico-node-h5vlv_kube-system_4af82d69-31a9-49c5-aff3-a52ba75d1d52_0 inpod sandbox k8s_calico-node-h5vlv_kube-system_4af82d69-31a9-49c5-aff3-a52ba75d1d52_0(94f892125383077bf219f9f27c4984d8a4df4b9c7b1095c38816caace9ac1479): creating overlay mount to /var/lib/containers/storage/overlay/e8f0d13f3c9d64c936c20a474d35930e2914cc4e5d910c060a6e5120cab27466/merged,mount_data="lowerdir=/var/lib/containers/storage/overlay/l/VLSPH22SLR55GHDHSKIT27ITHR,upperdir=/var/lib/containers/storage/overlay/e8f0d13f3c9d64c936c20a474d35930e2914cc4e5d910c060a6e5120cab27466/diff,workdir=/var/lib/containers/storage/overlay/e8f0d13f3c9d64c936c20a474d35930e2914cc4e5d910c060a6e5120cab27466/work,nodev,metacopy=on,volatile": input/output error
Có vẻ như kubelet không thể tạo Pod sandbox cho calico-node vì lỗi khi thực hiện mount overlay filesystem, cụ thể là:
creating overlay mount [...] input/output error
Đây là một lỗi phổ biến khi sử dụng container runtime như containerd hoặc CRI-O và storage backend overlayfs.
Lúc này mình đã hơi nghi nghi là do disk, vì trong số 3 disk của server, thì có 1 ổ HDD 500G là ổ cũ, mà cả cụm này mình đều build trên nó, nên thành ra mình nghi ngờ là do chất lượng của disk này không còn tốt.
Tiếp đó mình check trên con worker03 xem có lỗi gì liên quan đến disk không :
wasadm@node-worker03:~$ journalctl -xe | grep overlay
Apr 02 20:33:54 node-worker03 crio[784]: time="2025-04-02 20:33:54.256647690+07:00" level=error msg="Unmounting /var/lib/containers/storage/overlay/7408bf5016080bac8d4cd1699a1b28ce4bd558d9075abd87b6900cbe4f39a617/merged: invalid argument"
Apr 02 20:33:54 node-worker03 kernel: overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state.
Apr 02 20:33:54 node-worker03 kubelet[1430]: E0402 20:33:54.261110 1430 remote_runtime.go:193] "RunPodSandbox from runtime service failed" err="rpc error: code = Unknown desc = failed to mount container k8s_POD_calico-node-fwwf7_kube-system_68b83e27-d928-4060-a77a-a68c6599b2c0_0 in pod sandbox k8s_calico-node-fwwf7_kube-system_68b83e27-d928-4060-a77a-a68c6599b2c0_0(6605dda602e500a81de35f1c2bfb47ef96ff0e3f273553495042df16cde3f4cd): creating overlay mount to /var/lib/containers/storage/overlay/7408bf5016080bac8d4cd1699a1b28ce4bd558d9075abd87b6900cbe4f39a617/merged, mount_data=\"lowerdir=/var/lib/containers/storage/overlay/l/VLSPH22SLR55GHDHSKIT27ITHR,upperdir=/var/lib/containers/storage/overlay/7408bf5016080bac8d4cd1699a1b28ce4bd558d9075abd87b6900cbe4f39a617/diff,workdir=/var/lib/containers/storage/overlay/7408bf5016080bac8d4cd1699a1b28ce4bd558d9075abd87b6900cbe4f39a617/work,nodev,metacopy=on,volatile\": input/output error"
Lúc này tôi phát hiện ra :
overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state. ... creating overlay mount [...] input/output error
OverlayFS đang báo lỗi khi mount layer do upperdir có lỗi chưa được xử lý (unseen error). Điều này thường xảy ra do:
- File system dưới bị lỗi (
I/O error,corruption) - Disk gần đầy hoặc có bad blocks
- Các mount cũ không được dọn dẹp đúng cách
- CRI-O hoặc hệ thống containerd bị "tắc nghẽn" ở layer overlay
Tiếp đó tôi thử :
wasadm@node-worker03:~$ sudo dmesg | grep -i error
[ 2.678244] RAS: Correctable Errors collector initialized.
[ 9713.150040] blk_update_request: I/O error, dev sda, sector 20105520 op 0x1:(WRITE) flags 0x800 phys_seg 1 prio class 0
[ 9713.150222] EXT4-fs warning (device sda4): ext4_end_bio:344: I/O error 10 writing to inode 442747 starting block 2513191)
[ 9713.150231] Buffer I/O error on device sda4, logical block 1307686
[ 9724.196089] overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state.
[ 9737.549700] overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state.
[ 9764.329017] overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state.
[ 9809.242911] overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state.
[ 9825.959105] overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state.
Dòng lỗi rõ ràng nhất là:
blk_update_request: I/O error, dev sda, sector 20105520
EXT4-fs warning (device sda4): ext4_end_bio:344: I/O error 10 writing to inode ...
Buffer I/O error on device sda4
Đây là lỗi phần cứng (hoặc firmware) từ thiết bị lưu trữ. Khi đó, overlayfs không thể hoạt động bình thường :
overlayfs: Cannot mount volatile when upperdir has an unseen error. Sync upperdir fs to clear state.
Ok, lúc này thì tôi đành phải move hết cả cụm sang disk mới (cũng là ổ HDD)
 Tiếp đó, tôi vào check lại disk performance của ESXI:
Tiếp đó, tôi vào check lại disk performance của ESXI:

 Chẹp, lạ thật, thông số của các disk trên ESXI đều ổn, disk 500G kia k có dấu hiệu bị Latency read/write
Nhưng kệ, tôi vẫn tiếp tục công việc của mình.
Cảm nhận ban đầu sau khi move thì các VMs có vể chạy nhanh hơn so với trước.
Chẹp, lạ thật, thông số của các disk trên ESXI đều ổn, disk 500G kia k có dấu hiệu bị Latency read/write
Nhưng kệ, tôi vẫn tiếp tục công việc của mình.
Cảm nhận ban đầu sau khi move thì các VMs có vể chạy nhanh hơn so với trước.
Nhưng tôi đã nhầm
Thêm 1 lần nữa, tôi lại gặp lỗi :
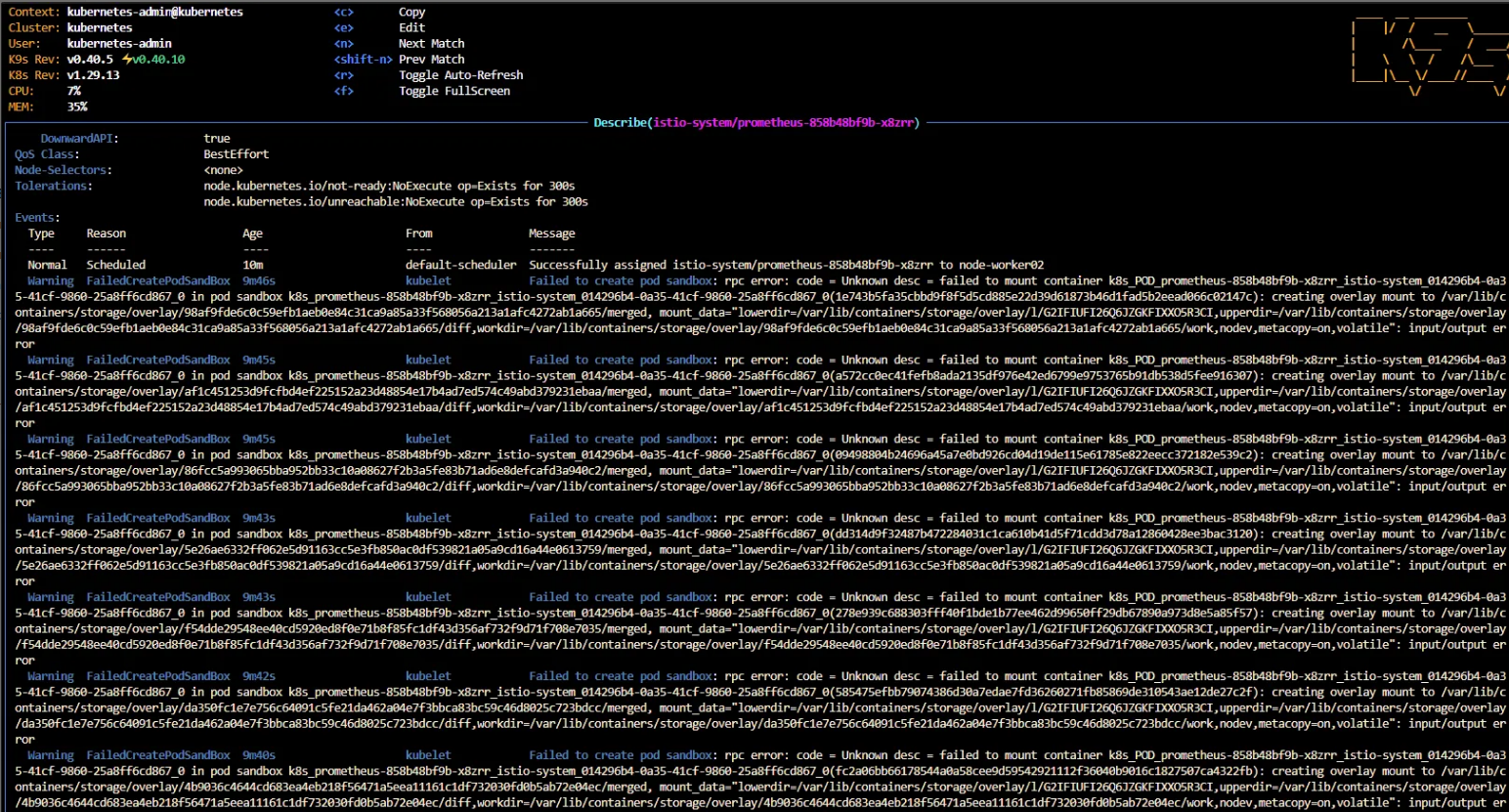
Warning FailedCreatePodSandBox 9m46s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to mount container k8s_POD_prometheus-858b48bf9b-x8zrr_istio-system_014296b4-0a3 ││ 5-41cf-9860-25a8ff6cd867_0 in pod sandbox k8s_prometheus-858b48bf9b-x8zrr_istio-system_014296b4-0a35-41cf-9860-25a8ff6cd867_0(1e743b5fa35cbbd9f8f5d5cd885e22d39d61873b46d1fad5b2eead066c02147c): creating overlay mount to /var/lib/c ││ ontainers/storage/overlay/98af9fde6c0c59efb1aeb0e84c31ca9a85a33f568056a213a1afc4272ab1a665/merged, mount_data="lowerdir=/var/lib/containers/storage/overlay/l/G2IFIUFI26Q6JZGKFIXXO5R3CI,upperdir=/var/lib/containers/storage/overlay ││ /98af9fde6c0c59efb1aeb0e84c31ca9a85a33f568056a213a1afc4272ab1a665/diff,workdir=/var/lib/containers/storage/overlay/98af9fde6c0c59efb1aeb0e84c31ca9a85a33f568056a213a1afc4272ab1a665/work,nodev,metacopy=on,volatile": input/output error
Lỗi này xảy ra với node-worker02
Và tôi check phần disk của nó :
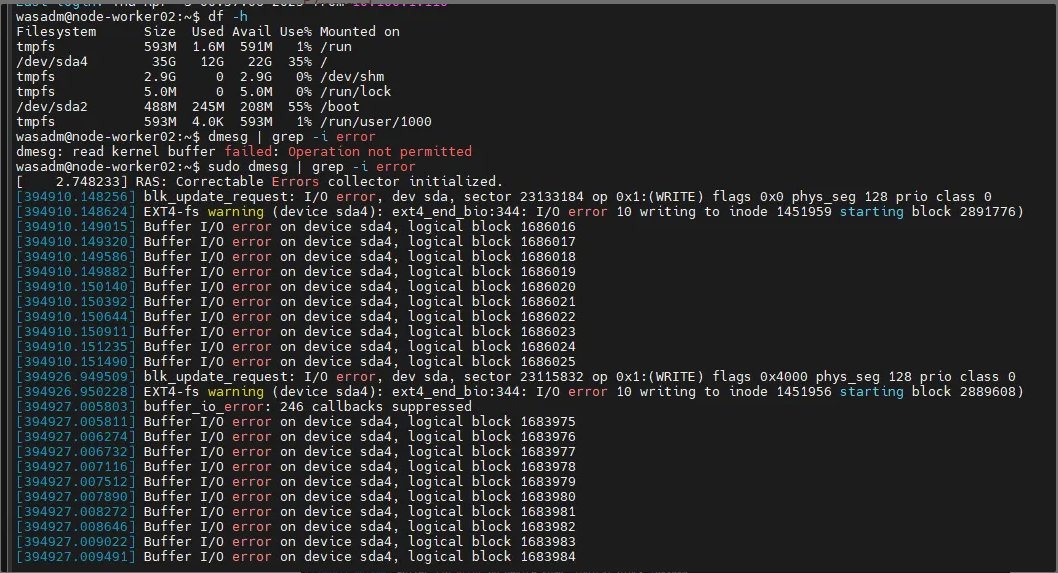
wasadm@node-worker02:~$ sudo dmesg | grep -i error
[ 2.748233] RAS: Correctable Errors collector initialized.
[394910.148256] blk_update_request: I/O error, dev sda, sector 23133184 op 0x1:(WRITE) flags 0x0 phys_seg 128 prio class 0
[394910.148624] EXT4-fs warning (device sda4): ext4_end_bio:344: I/O error 10 writing to inode 1451959 starting block 2891776)
[394910.149015] Buffer I/O error on device sda4, logical block 1686016
[394910.149320] Buffer I/O error on device sda4, logical block 1686017
[394910.149586] Buffer I/O error on device sda4, logical block 1686018
[394910.149882] Buffer I/O error on device sda4, logical block 1686019
[394910.150140] Buffer I/O error on device sda4, logical block 1686020
[394910.150392] Buffer I/O error on device sda4, logical block 1686021
[394910.150644] Buffer I/O error on device sda4, logical block 1686022
[394910.150911] Buffer I/O error on device sda4, logical block 1686023
[394910.151235] Buffer I/O error on device sda4, logical block 1686024
[394910.151490] Buffer I/O error on device sda4, logical block 1686025
[394926.949509] blk_update_request: I/O error, dev sda, sector 23115832 op 0x1:(WRITE) flags 0x4000 phys_seg 128 prio class 0
[394926.950228] EXT4-fs warning (device sda4): ext4_end_bio:344: I/O error 10 writing to inode 1451956 starting block 2889608)
[394927.005803] buffer_io_error: 246 callbacks suppressed
Đến đây tôi đã lờ mờ nhận ra vấn đề.
Điều gì đã làm cho error on device sda4, logical block ?
1. Kube-api
 Nếu để ý kỹ, chúng ta sẽ thấy thằng này hoạt động nhiều, mem và cpu đều cao, lí do là nó r/w liên tục vào ETCD.
Nếu để ý kỹ, chúng ta sẽ thấy thằng này hoạt động nhiều, mem và cpu đều cao, lí do là nó r/w liên tục vào ETCD.
2. ETCD
 Liên tục r/w data, cái này k phải bàn.
Liên tục r/w data, cái này k phải bàn.
3. Scheduler
Vì mình quên xóa HPA, nên thằng này nó liên tục đọc và cố gắng schedu pod theo object (quên mất)
4. Controller
 Khỏi phải nói, ông này cũng hoạt động realtime theo các pods
Khỏi phải nói, ông này cũng hoạt động realtime theo các pods
5. Các thành phần đi kèm trong Istio :
Collect metrics realtime:
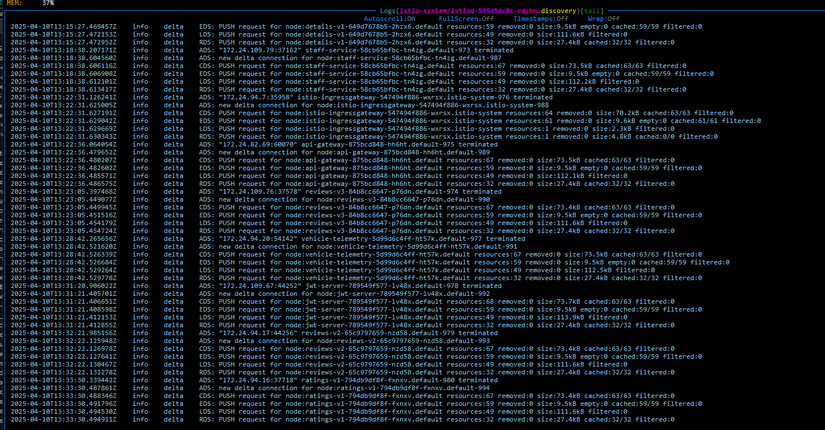
6. Application:
Read/write nhiều nhất là 2 pods : position-simulator và tracker
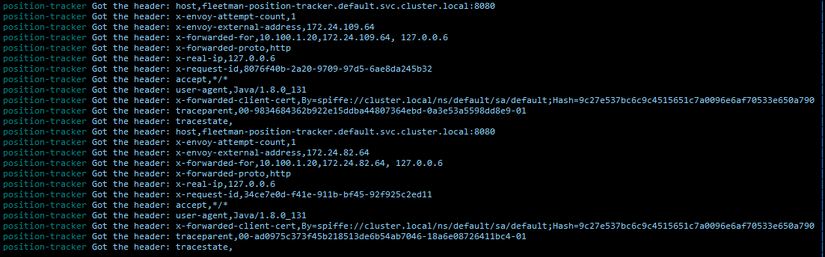
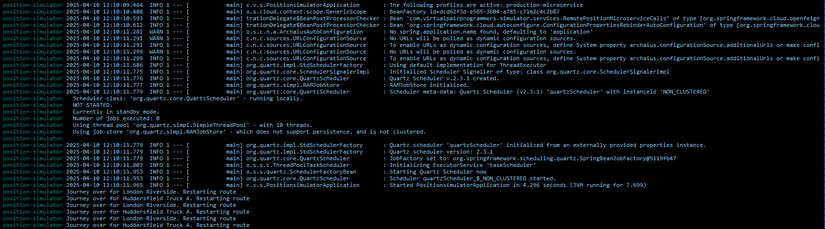 Vì đây là 2 pods làm nhiệm vụ định vị, truyền tải liên tục vị trí của các xe, để hiện thị trên giao diện, 1 dạng của stream data.
Vì đây là 2 pods làm nhiệm vụ định vị, truyền tải liên tục vị trí của các xe, để hiện thị trên giao diện, 1 dạng của stream data.
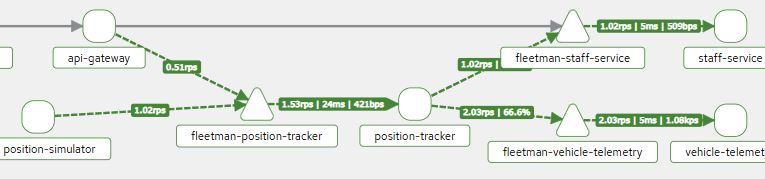
Nhưng 6 thành phần trên đều đang được chạy bởi CRIO
Về bản chất hoạt động khi khởi tạo container: Mỗi container mới thường cần:
- Tạo một tầng overlay
- Mount upperdir, workdir, merged
- Tạo vùng shared memory tmpfs
- Tạo thư mục userdata, runtime, etc.
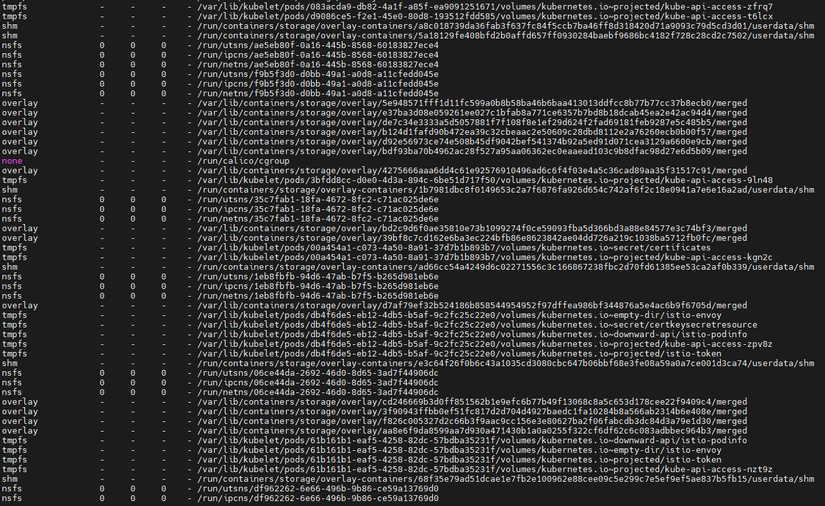 Và :
overlay
Đây là thành phần quan trọng nhất!
Và :
overlay
Đây là thành phần quan trọng nhất!
- Đây là filesystem ảo dùng để tạo ra filesystem cho container.
- Đọc từ image gốc (read-only) → mount làm lowerdir
- Ghi vào tầng mới (upperdir) → mỗi container có 1 tầng riêng
- Tầng merged là nơi container thực sự nhìn thấy
Để đi tiếp, chúng ta cần quay lại 1 kiến thức basic trong LPI, đó là INODE.
Vậy Inodes là gì?
Inode là một cấu trúc dữ liệu. Nó xác định một file hoặc một thư mục trên hệ thống file và được lưu trữ trong directory entry. Inodes trỏ đến các block tạo nên một file. Chúng chứa tất cả dữ liệu quản trị cần thiết để đọc một file. Metadata của mọi file được lưu trữ trong các inodes trong cấu trúc bảng.
Ví dụ, ta tạo 1 file mới có tên là file-4.txt, chuyện gì sẽ xảy ra?
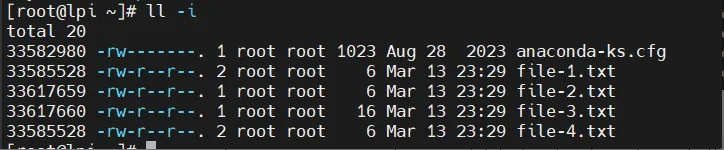
- Hệ thống tập tin cấp phát một inode mới:
-
Inode này lưu metadata của file (kích thước, quyền, UID, GID, thời gian truy cập...).
-
Inode không chứa nội dung file, cũng không chứa tên file.
b. Thêm một entry vào thư mục chứa file (
directory entry): -
Entry này gồm:
- Tên file (
file-4.txt). - Số inode của file (ví dụ:
33585528).
- Tên file (
-
Directory Entry chỉ là ánh xạ giữa tên file và inode.
c. Nếu file có dữ liệu, hệ thống cấp phát các block trên disk để lưu nội dung:
-
Inode chứa danh sách các block nơi dữ liệu được lưu.
-
Nếu file quá lớn, hệ thống sẽ dùng Indirect Blocks để quản lý danh sách block.
Vậy thì log lỗi ở trên của mình có đoạn :
[ 2.748233] RAS: Correctable Errors collector initialized.
[394910.148256] blk_update_request: I/O error, dev sda, sector 23133184 op 0x1:(WRITE) flags 0x0 phys_seg 128 prio class 0
[394910.148624] EXT4-fs warning (device sda4): ext4_end_bio:344: I/O error 10 writing to inode 1451959 starting block 2891776)
[394910.149015] Buffer I/O error on device sda4, logical block 1686016
...
Điều đó có nghĩa là : số lượng bản ghi sinh ra càng lớn, tương đương với lượng INODE sinh ra theo cũng lớn theo. Đến đây, mình mới nhớ ra, lúc mình triển khai cụm, mình đều để các disk của mình ở định dạng EXT4. Chủ quan thật. Biết nguyên nhân, giờ là lúc fix lỗi.
Sửa sai :
Trên từng VMs, mình thêm 1 disk (Sau khi đã tắt hết cả cụm):
Mình sẽ fix trên những worker node trước. Bước 1: Check disk xem đã được add thành công chưa?
lsblk
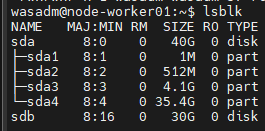
Bước 2 : Format ổ đĩa với XFS
sudo mkfs.xfs -f /dev/sdb
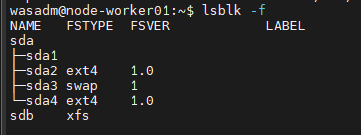
Bước 3 : Mount ổ mới vào thư mục tạm
sudo mkdir -p /mnt/container-storage
sudo mount /dev/sdb /mnt/container-storage
Bước 4 : Stop CRIO
sudo systemctl stop crio
Bước 5 : Di chuyển dữ liệu CRI-O
sudo rsync -aHAXx /var/lib/containers/ /mnt/container-storage/
Bước 6 : Backup và mount lại dữ liệu về đúng thư mục
sudo mv /var/lib/containers /var/lib/containers.bak
sudo mkdir /var/lib/containers
# Thêm vào /etc/fstab để auto-mount
echo "/dev/sdb /var/lib/containers ext4 defaults 0 2" | sudo tee -a /etc/fstab
# Mount lại
sudo mount -a
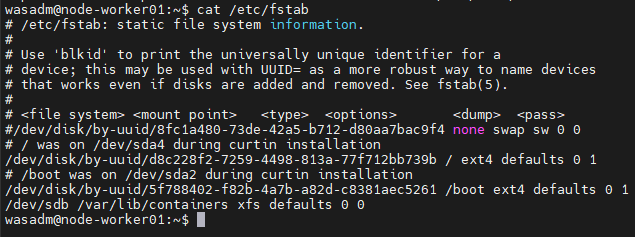
Bước 7 : Start lại CRI-O
sudo systemctl restart crio
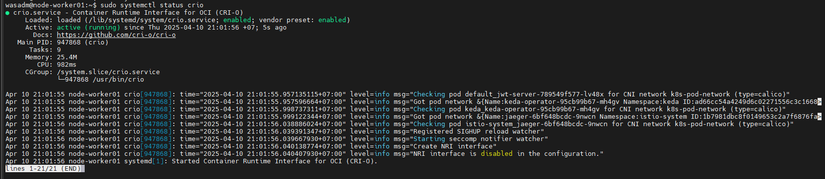
Thực hiện tương tự với 2 worker node còn lại.
Sau đó join chúng vào master.
 Cho đến khi mình viết bài này, mình đã theo dõi trong 2 tuần, cụm chạy mượt, khởi tạo lại pods nhanh, k còn chậm như trước.
Cho đến khi mình viết bài này, mình đã theo dõi trong 2 tuần, cụm chạy mượt, khởi tạo lại pods nhanh, k còn chậm như trước.

 Mọi người có thể thấy là thời gian để pods up là 17s.
Mình thử lại với con grafana, trước đó con này mất phải 15p mới 1/1 running
Mọi người có thể thấy là thời gian để pods up là 17s.
Mình thử lại với con grafana, trước đó con này mất phải 15p mới 1/1 running

 Và bây giờ nó mất có hơn 1p.
Và bây giờ nó mất có hơn 1p.
MongoDB cũng đã khuyến nghị dùng XFS thay vì là EXT4 : https://www.mongodb.com/docs/manual/administration/production-notes/#kernel-and-file-systems

Viết cũng đã dài, hi vọng là kiến thức này sẽ giúp ích cho mọi người.
All rights reserved
