KV Cache: Phương án tối ưu bộ nhớ trong Transformers
Trong những năm gần đây, Transformer đã trở thành một trụ cột vũng chãi trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) và trí tuệ nhân tạo (AI) như một mô hình địa cốt cho các tác vụ như dịch máy, sinh văn bản, và họi đáp tương tác. Đặc biệt, khả năng xử lý dữ liệu dài hơn và tăng hiệu quả tính toán đã trở thành động lực quan trọng trong quá trình phát triển Transformer. Trong bối cảnh này, cơ chế KV Cache (“Key-Value Cache”) xuất hiện như một kỹ thuật quan trọng giúp tối ưu hoá hiệu suất và giảm tác độ xử lý trong môi trường suy diễn (inference).
KV Cache trong kiến trúc Transformer được thiết kế như một cách lưu trữ các tensor đã được tính toán trong các bước truy vấn trước đó. Bằng việc tái sử dụng các điểm truy vấn đã tính, mô hình có thể tăng tốc độ suy diễn mà không cần phải xử lý lại dữ liệu từ đầu. Ngoài ra, KV Cache cung cấp khả năng giúp giảm tác độ bộ nhớ và duy trì hiệu quả tính toán cao trong các bải toán xử lý ngôn ngữ dài hơn.
Trong phần giới thiệu này, chúng ta sẽ tìm hiểu vì sao KV Cache trở thành một bộ phận cốt lễ trong việc đảm bảo hiệu suất và khả năng xử lý linh hoạt của Transformer, đồng thời xem xét những ứng dụng thực tế trong các hệ thống AI hiện đại.
Recap: Cơ chế sinh chữ trong Transformer
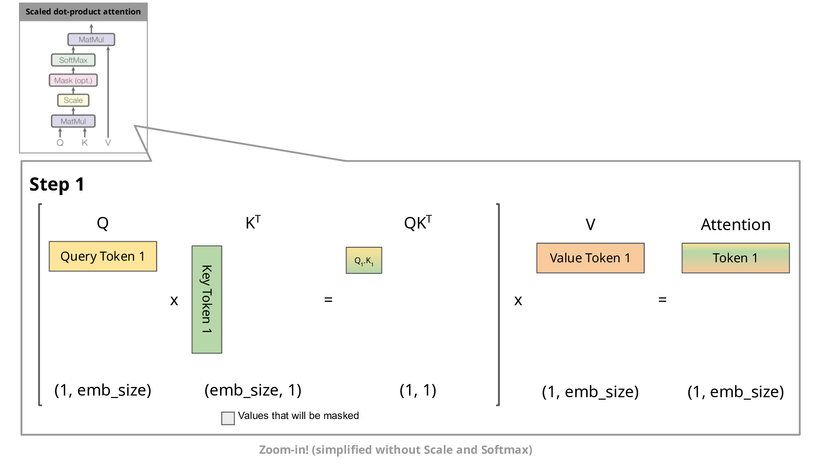
Kiến trúc Attention được giới thiệu như là thành phần trung tâm trong Transformer, với tên gọc là "Scaled Dot-Product Attention". Đồng góp chính của Attention này là giúp mô hình học được mối quan hệ giữa các từ hoặc token trong cùng một dãy dữ liệu.
Các bước chính trong Attention gồm:
- Tính toán Query, Key và Value:
- Mỗi từ được biểu diễn dưới dạng vector, sau đó chuyển thành Query (Q), Key (K), và Value (V) bằng các ma trận tỉ tuyến.
- Tính điểm Attention:
-
Sử dụng phép tính dot product giữa Query và Key để đo mức độ tương đương giữa các từ.
-
Chia kết quả cho căn bậc hai kích thước Key để đảm bảo độ ổn định số hạng.
- Sử dụng Softmax:
- Biến đổi các điểm Attention thành xác suất, giúp chọn lọc thông tin quan trọng nhất.
- Kết hợp với Value:
- Nhân các xác suất Attention với Value tương ứng để tạo thành đầu ra của Attention.
Bằng việc kết hợp nhiều hạnh Attention song song (Multi-Head Attention), Transformer có thể học được các mối quan hệ đa chiều trong dữ liệu, tăng tính biểu đạt và độ chính xác trong các tác vụ NLP.
Bên trên là minh họa quy trình tính toán attention. Ta thấy có một vấn đề là mỗi bước tạo ra token mới, chúng ta đang tính toán lại attention cho các token trước đó, nhưng trong thức tế chúng ta chỉ cần tính attention cho token mới.
KV Cache
Ở đây thì KV Cache sẽ lưu lại Keys và Values ở phía trước và chúng ta có thể tập trung vào việc tính toán attention cho token mới.
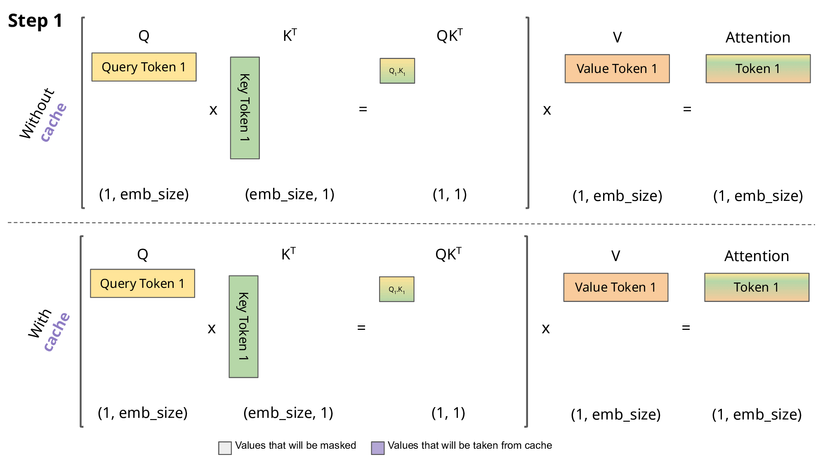
Tại sao chúng ta lưu ý hai điều chính mà có thể thực hiện được điều này trong Transformer:
- Trong quá trình sinh chuỗi, một token tại một thời điểm, hai ma trận key và value không thay đổi nhiều.
- Khi chúng ta đã tính toán được embedding cho token mới, nó sẽ không thay đổi, bất kể chúng ta tạo ra bao nhiêu token nữa.
Đó là lý do tại sao các vector key và value của các token đã có thường được lưu trữ lại để sử dụng cho việc tạo ra các token tương lai. Phương pháp này dẫn đến cái gọi là KV cache. Lưu ý rằng KV cache của một token phụ thuộc vào tất cả các token trước đó của nó, vì vậy nếu cùng một token xuất hiện ở hai vị trí khác nhau trong chuỗi, các KV cache tương ứng sẽ khác nhau.
Ngoài ra thì chúng ta có thể test với transformer. Một lưu ý khá thú vị đó là KV Cache hỗ trợ khá nhiều về tốc độ suy luận nhưng về vấn đề sử dụng VRAM của GPU gần như không thay đổi đáng kể, bạn có thể xem sâu ở đây.
References
All rights reserved
