Large Concept Models (LCMs) by Meta: Kỷ nguyên mới sau LLMs ?
1. Giới thiệu
Kể từ khi ChatGPT ra mắt vào cuối năm 2022, chúng ta đã bước vào kỷ nguyên của Trí tuệ nhân tạo tạo sinh (Generative AI), nơi các Mô hình Ngôn ngữ Lớn (LLM) đã trở thành trung tâm của cuộc sống số. Kiến trúc cốt lõi của các mô hình này dựa trên nền tảng Transformer quy mô lớn. Tuy nhiên, để xử lý các câu lệnh đầu vào, LLMs cần đến một thành phần quan trọng không kém là bộ token hóa (tokenizer). Bộ token hóa này đảm nhiệm việc chuyển đổi câu lệnh thành các token - những đơn vị thuộc về từ vựng của mô hình.

Quá trình token hóa thường phân tách câu thành các đơn vị nhỏ hơn, trong đó phần lớn các từ đơn được biểu diễn bằng một token duy nhất, trong khi các từ phức tạp hơn có thể được chia thành nhiều token. Mô hình sau đó sẽ xử lý chuỗi token này để tạo ra phản hồi, sử dụng cùng một bộ từ vựng token.
Tuy nhiên, phương pháp xử lý này có sự khác biệt đáng kể so với cách thức con người tiếp nhận và xử lý thông tin. Trong khi mô hình hoạt động dựa trên các token rời rạc, tư duy của con người vận hành ở nhiều tầng trừu tượng khác nhau, vượt xa khỏi giới hạn của các đơn vị từ đơn lẻ. Điều này phản ánh khoảng cách còn tồn tại giữa trí tuệ nhân tạo và khả năng nhận thức của con người. Gần đây, nhiều chuyên gia công nghệ hàng đầu đã chỉ ra rằng sự phát triển của LLM đang dần đạt đến điểm bão hòa. Trong bối cảnh đó, Meta đã giới thiệu một ý tưởng đột phá và ngày 11 tháng 12, 2024 về Mô hình Khái niệm Quy mô Lớn (Large Concept Models - LCM), hứa hẹn mở ra một chương mới trong lĩnh vực xử lý ngôn ngữ tự nhiên và trí tuệ nhân tạo nói chung.

2. Bản chất và nguyên lý của Large Concept Models (LCMs)
Một nghiên cứu gần đây từ Meta đã đề xuất giải pháp để thu hẹp khoảng giữa trí tuệ nhân tạo và khả năng nhận thức của con người. Nghiên cứu có tựa đề "Large Concept Models: Language Modeling in a Sentence Representation Space" đã giới thiệu một kiến trúc mới được gọi là Mô hình Khái niệm Quy mô Lớn (Large Concept Models - LCMs). Mô hình Khái niệm Quy mô Lớn là một phương pháp tiếp cận đột phá trong việc mô hình hóa ngôn ngữ, vượt xa khỏi giới hạn của các mô hình ngôn ngữ truyền thống. Thay vì xử lý văn bản ở cấp độ token như các LLM, LCM làm việc với "concept" - những biểu diễn trừu tượng độc lập với ngôn ngữ và phương thức thể hiện.
2.1 Concept trong LCMs
Trong khuôn khổ LCM của Meta, một concept được định nghĩa như một đơn vị ý tưởng trừu tượng, không thể chia nhỏ hơn. Trong thực tế, một concept thường tương ứng với:
- Một câu hoàn chỉnh trong văn bản.
- Một đoạn phát biểu có ý nghĩa trong câu nói.
- Một ý tưởng hoặc hành động có thể nhận biết được.
2.2 So sánh với cách tiếp cận truyền thống
2.2.1 Sự khác biệt giữa Concept và Token
Các khái niệm (concepts) biểu diễn ngữ nghĩa của những ý tưởng hoặc hành động ở cấp độ cao hơn và không bị ràng buộc vào các từ đơn lẻ cụ thể. Hơn nữa, khái niệm không chỉ giới hạn trong phạm vi ngôn ngữ mà có thể được rút ra từ nhiều phương thức biểu đạt khác nhau. Chẳng hạn, khái niệm cốt lõi của một câu vẫn được bảo toàn dù câu đó được diễn đạt bằng tiếng Anh, ngôn ngữ khác, hay thông qua văn bản hoặc giọng nói. Mình sẽ lấy ví dụ để cho dễ trực quan ở đoạn này:
- Mô hình Ngôn ngữ Truyền thống (LLM): => Quá trình dự đoán từng từ của LLM hoạt động bằng cách dự đoán từ tiếp theo ("token") dựa trên những từ bạn đã viết ví dụ:
- Input: "Chiếc ô tô đang đi trên..."
- LLM dự đoán: "đường"
- Quá trình này diễn ra tuần tự, từng từ một
- Tập trung vào ngữ cảnh cục bộ và cấu trúc ngữ pháp Nó giống như điền vào chỗ trống từng từ một. Cách này hoạt động tốt nhưng nó rất tập trung vào từng từ riêng lẻ và không phải lúc nào cũng nghĩ về bức tranh tổng thể hoặc ý nghĩa tổng thể của câu.
- Mô hình Khái niệm Quy mô Lớn (LCM): => LCM hoạt động ở cấp độ cao hơn thay vì dự đoán từ tiếp theo, mô hình sẽ dự đoán "concept" hoặc "next ideal". Một "concept" giống như một ý nghĩ hoặc một câu hoàn chỉnh, không chỉ là một từ đơn lẻ ví dụ:
- Input: "Con mèo đang ngồi nằm trên ghế. Tôi đang chuẩn bị lấy thức ăn cho nó ăn. Bỗng nhiên..."
- LCM dự đoán: "Một tiếng động lớn vang lên từ nhà bếp"
- Dự đoán theo đơn vị ý tưởng hoàn chỉnh
- Tập trung vào mạch logic và ngữ cảnh tổng thể Ở đây, mô hình không chỉ đoán từ tiếp theo mà đó là suy nghĩ về toàn bộ ý tưởng sẽ xảy ra tiếp theo. Nó giống như việc lên kế hoạch cho phần tiếp theo của câu chuyện theo từng đoạn chứ không phải từng chữ một.
2.2.2 Tại sao cách tiếp cận này lại hiệu quả ?
Do tính Độc lập với các ngôn ngữ: Mô hình không quan tâm liệu đầu vào bằng tiếng Anh, tiếng Pháp hay bất kỳ ngôn ngữ nào khác. Nó hoạt động dựa trên ý nghĩa của câu chứ không phải các từ cụ thể. Ví dụ: Nhập bằng tiếng Anh: "Con mèo đang đói". Đầu vào bằng tiếng Pháp: "Le chat a faim." Cả hai câu đều có nghĩa giống nhau, vì vậy mô hình coi chúng như cùng một khái niệm.
Tính Đa phương thức (Hoạt động với Văn bản, Lời nói, v.v.): Mô hình cũng có thể hoạt động với lời nói hoặc thậm chí cả hình ảnh. Ví dụ: Nếu bạn nói "Con mèo đang đói" hoặc hiển thị hình ảnh một con mèo đang đói, thì người mẫu sẽ hiểu khái niệm tương tự: "Một con mèo cần thức ăn". Tốt hơn cho nội dung dài: Khi viết một câu chuyện hoặc bài luận dài, người mẫu có thể lập kế hoạch cho luồng ý tưởng thay vì mắc kẹt ở từng từ riêng lẻ. Ví dụ: Nếu bạn đang viết một bài nghiên cứu, mô hình có thể giúp bạn phác thảo những điểm chính (khái niệm) và sau đó mở rộng chúng.
Xử lý tốt hơn với các đoạn văn bản với nội dung dài: Một lợi thế đáng kể của các khái niệm xử lý là khả năng xử lý tốt hơn các đầu vào ngữ cảnh dài. Do chuỗi khái niệm ngắn hơn nhiều so với chuỗi mã thông báo cho cùng một đầu vào nên phương pháp này giảm đáng kể thách thức quản lý chuỗi dài. Như khi viết một câu chuyện hoặc bài luận dài, mô hình có thể lập kế hoạch cho "flow ideal" (luồng ý tưởng) thay vì mắc kẹt trong từng từ riêng lẻ. Ví dụ nếu bạn đang viết một bài nghiên cứu, mô hình có thể giúp bạn phác thảo những điểm chính (concepts) và sau đó mở rộng chúng.
Lập luận Phân cấp: Một nhận xét quan trọng là việc xử lý khái niệm thay vì các token con tạo điều kiện thuận lợi cho quá trình lập luận phân cấp. Ví dụ Khi chuẩn bị một bài thuyết trình 15 phút. Thông thường, mọi thầy cô sẽ không chuẩn bị bài phát biểu chi tiết bằng cách viết ra từng từ một. Thay vào đó, họ sẽ phác thảo một luồng các ý tưởng chính để truyền đạt trong bài thuyết trình. Nếu thầy cô trình bày cùng một bài thuyết trình nhiều lần, các từ ngữ cụ thể được sử dụng có thể khác nhau, thậm chí bài thuyết trình có thể được trình bày bằng các ngôn ngữ khác nhau, nhưng luồng các ý tưởng chính vẫn sẽ giữ nguyên.
2.2.3 Ví dụ về Lập luận Dựa trên Khái niệm
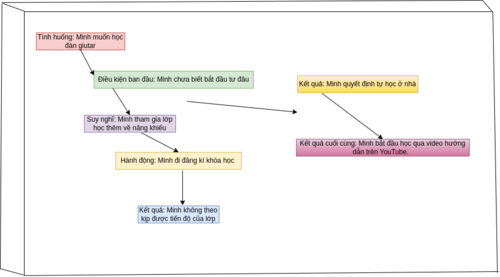
Hình minh họa dưới đây mô tả trực quan về quá trình lập luận trong không gian embedding các khái niệm cho tác vụ tóm tắt. Ở phía bên trái, ta có các embedding của năm câu. Những vector này đại diện cho các khái niệm ban đầu.Ở phía bên phải, Các khái niệm ban đầu được ánh xạ (mapped) thành hai vector embedding mới. Những vector này đại diện cho khái niệm rút gọn, tức là bản tóm tắt. Mục đích mô tả cơ chế ánh xạ từ không gian của các câu gốc (đầy đủ thông tin) sang không gian của các câu tóm tắt (cô đọng thông tin), để thể hiện cách mô hình hoạt động trong tác vụ tóm tắt.
2.3 Kiến trúc tổng quát của LCMs
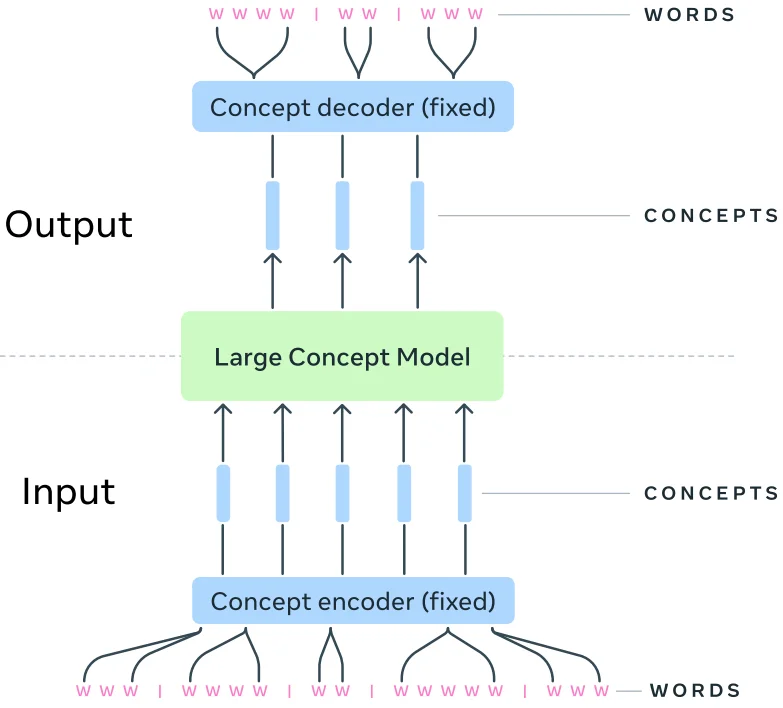
2.3.1 Concept Encoder (SONAR)
Các câu đầu tiên được truyền qua một bộ mã hóa khái niệm được gọi là concept encoder, chuyển đổi các câu thành các concept embedding. Ở đó bộ mã hóa khái niệm được sử dụng là một thành phần mã hóa và giải mã có tên SONAR. SONAR hỗ trợ 200 ngôn ngữ cho đầu vào và đầu ra văn bản - gấp hơn hai lần số lượng ngôn ngữ được hỗ trợ bởi hầu hết các LLM hiện nay. Ngoài ra, nó còn có khả năng tiếp nhận đầu vào giọng nói từ 76 ngôn ngữ.
2.3.2 Large Concept Model (LCM)
Tiếp theo, chuỗi khái niệm được xử lý bởi LCM để tạo ra một chuỗi khái niệm mới ở đầu ra. Chúng hoạt động hoàn toàn trong không gian embedding, khiến nó độc lập với bất kỳ ngôn ngữ hay phương thức biểu đạt cụ thể nào. Phương pháp này có thể mở rộng ra ngoài phạm vi văn bản và giọng nói.
2.3.3 Concept Decoder (SONAR)
Cuối cùng, các khái niệm được tạo ra được giải mã trở lại thành ngôn ngữ thông qua SONAR. Bộ giải mã có khả năng chuyển đổi đầu ra của LCM thành nhiều hơn một ngôn ngữ hoặc thậm chí nhiều hơn một phương thức biểu đạt.
2.4 Quy trình hoạt động của LCMs
2.4.1 Step 1: Input Processing
Đầu tiên, hệ thống thực hiện quá trình phân đoạn văn bản thành các đơn vị câu riêng biệt. Mỗi đơn vị câu sau đó được chuyển đổi thành vector embedding có kích thước cố định (fixed-size embedding) thông qua bộ mã hóa câu SONAR đã được huấn luyện trước. Điểm đột phá của SONAR nằm ở khả năng xử lý đa dạng nguồn đầu vào, bao gồm cả văn bản và giọng nói, trên phạm vi 200 ngôn ngữ khác nhau. Các vector embedding này đóng vai trò như những đại diện trừu tượng cho các khái niệm trong chuỗi đầu vào.
2.4.2 Step 2: Large Concept Model (LCM)
Phần cốt lõi của hệ thống là mô hình LCM, được thiết kế để thao tác trực tiếp trên các vector concept embedding. Mô hình được huấn luyện theo phương pháp dự đoán tự hồi quy trong không gian embedding, nghĩa là nó học cách dự đoán khái niệm tiếp theo dựa trên chuỗi các concept đã cho. Đầu ra của LCM là một chuỗi các vector embedding mới, có thể được chuyển đổi ngược về dạng văn bản hoặc giọng nói thông qua bộ giải mã SONAR.
2.4.3 Step 3: Output Generation
Giai đoạn cuối cùng của quy trình là việc chuyển đổi các vector embedding được tạo ra thành dạng đầu ra cuối cùng. Đặc biệt, do LCM hoạt động ở cấp độ khái niệm trừu tượng, quá trình lập luận có thể được áp dụng cho nhiều ngôn ngữ và phương thức biểu đạt khác nhau mà không cần huấn luyện lại mô hình. Khả năng tổng quát hóa zero-shot của mô hình cho phép nó xử lý các ngôn ngữ hoặc phương thức biểu đạt mới, miễn là chúng nằm trong phạm vi hỗ trợ của bộ mã hóa và giải mã SONAR.
Một vài key point để hiểu rõ hơn về quy trình của LCM là :
- SONAR Embedding Space: SONAR xây dựng một không gian embedding đa ngôn ngữ và đa phương thức với độ phủ rộng, hỗ trợ 200 ngôn ngữ cho văn bản và 76 ngôn ngữ cho giọng nói như đã nói ở trên. Vector embedding của SONAR có kích thước cố định và được thiết kế để nắm bắt đầy đủ ngữ nghĩa của câu, tạo nền tảng vững chắc cho quá trình lập luận ở cấp độ khái niệm.
- Diffusion & Quantized Based Generation: Nghiên cứu của Meta đã thử nghiệm nhiều phương pháp khác nhau trong việc huấn luyện LCM. Một hướng tiếp cận đột phá là sử dụng mô hình khuếch tán (diffusion model) để dự đoán embedding khái niệm tiếp theo thông qua việc học phân phối xác suất có điều kiện trên không gian embedding liên tục. Song song với đó, nhóm nghiên cứu cũng phát triển phương pháp lượng tử hóa (quantization) các embedding SONAR thành các đơn vị rời rạc, cho phép LCM thực hiện dự đoán khái niệm một cách có kiểm soát hơn, tương tự như cách các LLM lấy mẫu token từ từ vựng.
3. Kiến trúc nội tại của Large Concept Models (LCMs)
3.1 Base-LCM: Large Concept Model Naive Architecture
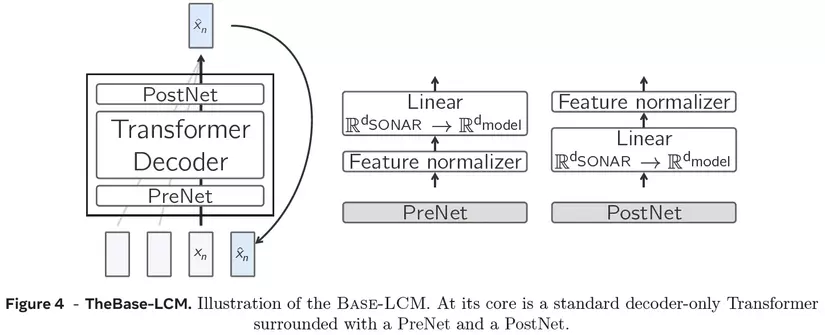 Trong hình trên chúng ta thấy kiến trúc của Base-LCM. Ở dưới cùng bên trái, chúng ta có một chuỗi các khái niệm (sequence concepts). Các chuỗi này không bao gồm khái niệm cuối cùng, được đưa vào mô hình để dự đoán khái niệm tiếp theo. Đầu ra sau đó được so sánh với "actual next concept" không bao gồm trong đầu vào mô hình. Mình sẽ diễn giải đoạn này theo ý bên dưới:
Trong hình trên chúng ta thấy kiến trúc của Base-LCM. Ở dưới cùng bên trái, chúng ta có một chuỗi các khái niệm (sequence concepts). Các chuỗi này không bao gồm khái niệm cuối cùng, được đưa vào mô hình để dự đoán khái niệm tiếp theo. Đầu ra sau đó được so sánh với "actual next concept" không bao gồm trong đầu vào mô hình. Mình sẽ diễn giải đoạn này theo ý bên dưới:
Base-LCM thực hiện quá trình dự đoán concepts theo cơ chế sau:
-Đầu vào của mô hình:
- Một chuỗi các khái niệm được biểu diễn dưới dạng embedding (giả sử là chuỗi n khái niệm).
- Mô hình chỉ nhận n-1 khái niệm đầu tiên làm đầu vào, tức là bỏ qua khái niệm cuối cùng.
-Quá trình dự đoán:
- Từ n-1 khái niệm đầu vào, mô hình sẽ dự đoán khái niệm thứ n (khái niệm tiếp theo)
- Đầu ra của mô hình là một vector embedding biểu diễn khái niệm được dự đoán này
-Quá trình huấn luyện: Vector embedding dự đoán được so sánh với vector embedding của khái niệm thực tế thứ n, sự khác biệt giữa hai vector này được đo lường bằng hàm mất mát Mean Squared Error (MSE)
Base-LCM đại diện cho nỗ lực đầu tiên trong việc xây dựng mô hình khái niệm quy mô lớn. Cơ chế hoạt động của nó tương đồng với quá trình huấn luyện mô hình ngôn ngữ lớn để dự đoán token tiếp theo, nhưng thay vì thao tác trên token, mô hình được huấn luyện để dự đoán khái niệm tiếp theo trong không gian embedding khái niệm, nhìn vào hình ta thấy ở phía bên trái . Về mặt kiến trúc, Base-LCM bao gồm ba thành phần chính:
- Bộ giải mã Transformer đóng vai trò backbone của mô hình
- Mạng PreNet: Thực hiện chuẩn hóa embedding khái niệm nhận từ SONAR và ánh xạ chúng vào không gian chiều của Transformer
- Mạng PostNet: Đảm nhiệm việc chiếu kết quả đầu ra về chiều của SONAR Quá trình huấn luyện sử dụng hàm mất mát sai số bình phương trung bình (MSE) để so sánh khái niệm được dự đoán với khái niệm thực tế tiếp theo.
3.2 Hạn chế của Base-LCM
Điểm yếu chính của Base-LCM nằm ở việc nó được huấn luyện để tạo ra một khái niệm cụ thể, trong khi thực tế có thể tồn tại nhiều khái niệm hợp lý trong một ngữ cảnh cho trước. Vấn đề này tương tự như trong lĩnh vực sinh ảnh, nơi có thể có nhiều kết quả hợp lệ cho cùng một yêu cầu. Điều này dẫn đến sự phát triển của kiến trúc dựa trên Diffusion Model.
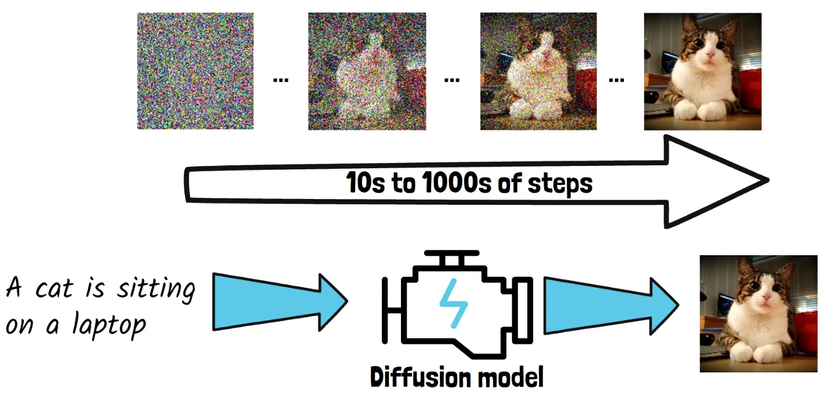
Mô hình khuếch tán (diffusion models) hoạt động bằng cách tạo ra hình ảnh từng bước, bắt đầu từ một hình ảnh nhiễu hoàn toàn và dần dần làm sạch nhiễu để tạo ra một bức tranh rõ ràng. Ví dụ, nếu bạn nhập một câu lệnh như “Một con mèo đang ngồi trên laptop,” mô hình sẽ sử dụng câu lệnh này để định hướng quá trình loại bỏ nhiễu khỏi hình ảnh. Ban đầu, hình ảnh chỉ là nhiễu ngẫu nhiên. Qua từng bước, mô hình dần dần loại bỏ nhiễu, và cuối cùng tạo ra bức ảnh rõ ràng của một con mèo trên laptop.
Trong quá trình huấn luyện, để dạy mô hình cách loại bỏ nhiễu, người ta sẽ làm ngược lại: thêm dần nhiễu vào một bức ảnh rõ ràng – đây chính là quá trình khuếch tán.
3.3 Diffusion-based LCMs: Improved Large Concept Model
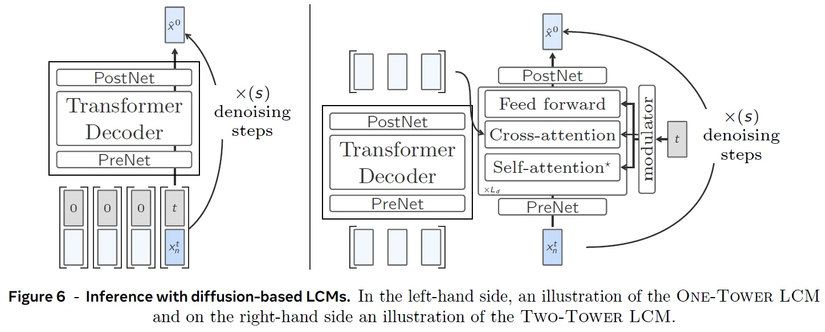 Để khắc phục hạn chế của Base-LCM, Meta đề xuất hai biến thể kiến trúc dựa trên khuếch tán:
Để khắc phục hạn chế của Base-LCM, Meta đề xuất hai biến thể kiến trúc dựa trên khuếch tán:
3.3.1 One-Tower Large Concept Model
Ở phía bên trái hình Diffusion-based LCMs architechture đó là One-Tower LCM. Ở dưới cùng, có một chuỗi đầu vào gồm các khái niệm và một số đại diện cho thời điểm bổ sung nhiễu (noisening timestamp). Các khái niệm có giá trị bằng 0 trong embedding là những "clean concept", và chỉ có concept cuối cùng bị nhiễu, được đánh dấu với một thời điểm t, cần được "làm sạch" (cleaned) để dự đoán khái niệm tiếp theo ở trạng thái sạch. Mô hình này được xây dựng tương tự như Base-LCM nhưng được chạy lặp lại nhiều lần. Ở mỗi bước, nó loại bỏ một phần nhiễu khỏi khái niệm tiếp theo bị nhiễu, xử lý đầu ra của nó như khái niệm nhiễu mới trong một số bước nhất định.
3.3.2 Two-Tower Large Concept Model
Ở phía bên phải, chúng ta thấy phiên bản khác được gọi là Two-Tower LCM. Sự khác biệt chính so với phiên bản One-Tower là nó tách riêng quá trình mã hóa ngữ cảnh trước đó và quá trình khuếch tán của các next concept embedding. Các embedding khái niệm sạch trước tiên được mã hóa bằng một Transformer chỉ có decoder. Kết quả sau đó được truyền vào một mô hình thứ hai, gọi là bộ khử nhiễu (denoiser), mô hình này cũng nhận khái niệm bị nhiễu tiếp theo và dần dần khử nhiễu nó để dự đoán khái niệm tiếp theo ở trạng thái sạch. Bộ khử nhiễu bao gồm các lớp Transformer, với một khối cross-attention để tập trung vào các khái niệm trước đó đã được mã hóa.
3.3.3 Đánh giá và Ý nghĩa
Kiến trúc dựa trên khuếch tán cho thấy nhiều ưu điểm so với Base-LCM:
- Khả năng tạo ra nhiều khái niệm hợp lý trong cùng một ngữ cảnh
- Tính linh hoạt cao hơn trong việc xử lý các trường hợp đa nghĩa
- Khả năng mở rộng tốt hơn cho các ứng dụng thực tế
4. Kết quả
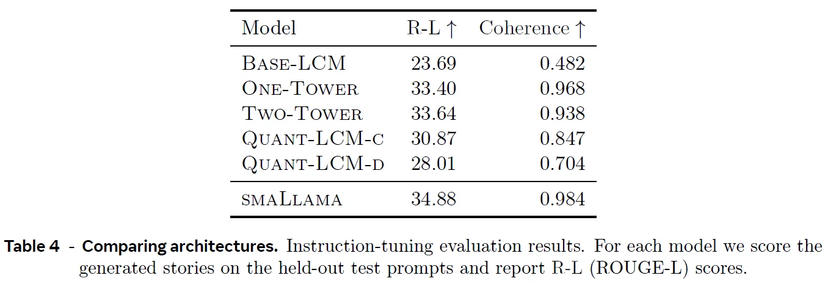 Trong bảng từ bài báo, ta thấy kết quả đánh giá quá trình tinh chỉnh chỉ dẫn cho các mô hình khác nhau. Các phiên bản dựa trên khuếch tán (diffusion-based) thể hiện hiệu suất vượt trội hơn đáng kể so với các phiên bản khác ở hai chỉ số được báo cáo:
Trong bảng từ bài báo, ta thấy kết quả đánh giá quá trình tinh chỉnh chỉ dẫn cho các mô hình khác nhau. Các phiên bản dựa trên khuếch tán (diffusion-based) thể hiện hiệu suất vượt trội hơn đáng kể so với các phiên bản khác ở hai chỉ số được báo cáo:
- ROUGE-L: Đánh giá chất lượng của các bản tóm tắt được tạo ra bằng cách đo độ dài của chuỗi con chung dài nhất giữa văn bản được tạo và văn bản tham chiếu.
- Coherence: Đánh giá mức độ logic và sự mạch lạc của văn bản được tạo ra, đảm bảo rằng các ý được kết nối một cách tự nhiên và trôi chảy.
5. Kết luận
Large Concept Models (LCMs) đánh dấu một bước tiến đáng kể trong việc mô phỏng quá trình tư duy của con người thông qua xử lý khái niệm cấp cao. Nghiên cứu của Meta đã chứng minh hiệu quả vượt trội của LCMs trong nhiều khía cạnh:
-
Hiệu năng Tổng hợp: LCMs thể hiện khả năng tóm tắt vượt trội so với các mô hình ngôn ngữ lớn truyền thống (LLMs).
-
Xử lý Ngữ cảnh: Kiến trúc dựa trên khái niệm cho phép xử lý hiệu quả hơn các đầu vào có ngữ cảnh dài.
-
Suy luận Phân cấp: Khả năng suy luận phân cấp được cải thiện đáng kể nhờ vào việc xử lý ở cấp độ khái niệm.
-
Tối ưu hóa Dự đoán: Việc tích hợp mô hình khuếch tán đã nâng cao đáng kể chất lượng dự đoán khái niệm thông qua quá trình tinh chỉnh lặp đi lặp lại. => LCMs mở ra một hướng nghiên cứu đầy hứa hẹn trong lĩnh vực xử lý ngôn ngữ tự nhiên. Mặc dù còn tồn tại một số thách thức, những hướng phát triển đề xuất có tiềm năng đáng kể trong việc nâng cao hiệu quả của mô hình. Việc tiếp tục nghiên cứu và phát triển các khía cạnh nêu trên sẽ góp phần quan trọng trong việc cải thiện khả năng của LCMs trong tương lai.
6. Tham khảo
All rights reserved
