[LLM 101 - Paper reading] RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
Đóng góp của bài báo
Các bạn làm LLM hẳn đều biết đến Retrieval Augmented Generation (RAG). Phương pháp này lấy cảm hứng từ cách con người sử dụng thông tin bên ngoài để hỗ trợ quá trình suy luận.
Trong bài báo, nhóm tác giả thực hiện nghiên cứu cách chúng ta có thể kết hợp RAG với quá trình suy luận (reasoning) dài và phức tạp của LLM. Ý tưởng cơ bản là, ta có thể sử dụng RAG để giảm thiểu sự sai sót trong các bước suy luận trung gian của mô hình, từ đó đưa ra phản hồi cuối cùng chính xác hơn.
Cách tiếp cận này, được đặt tên là retrieval-augmented thoughts (RAT), gồm 2 hoạt động chính:
- Đầu tiên, sử dụng các suy luận trung gian trong Chain-of-Thoughts của LLM và task prompt ban đầu làm các truy vấn (query) để truy xuất các thông tin liên quan giúp sửa lại những suy luận trung gian có thể bị sai trước đó.
- Thay vì truy xuất và sửa lại suy luận trung gian trong 1 lần, phương pháp này sẽ từng bước sửa các suy luận trung gian dựa trên các suy luận trước đó (có thể đã chỉnh sửa thông qua RAG), suy luận hiện tại và task prompt.
Phương pháp này cải thiện kết quả so với CoT prompting và RAG thông thường ở nhiều task như: Code generation, mathematical reasoning, embodied task planning và creative writing.
Phương pháp
Nhắc lại CoT và RAG
Retrieval-Augmented Generation (RAG) là kĩ thuật giúp giảm thiểu việc tạo ra các thông tin sai lệch trong LLMs bằng cách cung cấp cho chúng các văn bản liên quan được trích xuất từ các nguồn đáng tin cậy. Cụ thể, RAG sẽ tìm kiếm các tài liệu ứng viên phù hợp nhất từ một tập hợp các tài liệu dựa vào một truy vấn. Truy vấn này có thể là câu hỏi/nhiệm vụ được đưa ra hoặc thông tin liên quan do LLMs tạo ra.
Đầu tiên, RAG tạo ra embedding của các tài liệu và truy vấn, sau đó sử dụng độ tương đồng cosine để đánh giá mức độ liên quan giữa truy vấn và từng tài liệu. Các tài liệu được xếp hạng cao nhất sau đó được đưa vào làm dữ liệu đầu vào của LLMs để sinh ra câu trả lời cuối cùng. Bằng cách cung cấp ngữ cảnh phong phú và thông tin chính xác, RAG giảm bớt hallucination của LLMs.
Tuy nhiên, RAG có thể gặp khó khăn trong việc áp dụng cho các nhiệm vụ suy luận phức tạp, bởi vì việc chuyển đổi nhiệm vụ này thành các truy vấn tìm kiếm hiệu quả là không dễ dàng, dẫn đến thách thức trong việc tìm kiếm tài liệu liên quan. Theo cách truyền thống, RAG trích xuất tất cả thông tin liên quan cùng một lúc, nhưng điểm hạn chế của cách này là khó có thể biết được thông tin cụ thể nào là cần thiết cho bước suy luận nào để tiếp tục sinh ra kết quả tiếp theo.
Chain of Thoughts (CoT) prompting là kĩ thuật viết prompt sao cho LLM thực hiện từng bước suy luận trước khi đưa ra kết quả cuối cùng thay vì đưa ra câu trả lời trực tiếp ngay lần đầu. Cách làm này tỏ ra hiệu quả trong các task cần suy luận phức tạp như mathematical reasoning. Tuy nhiên, do không có sự giám sát trực tiếp đối với những suy nghĩ trung gian nên LLM có thể mắc lỗi do thiếu kiến thức về lĩnh vực liên quan hoặc bị sai lệch do hallucination.
RAT
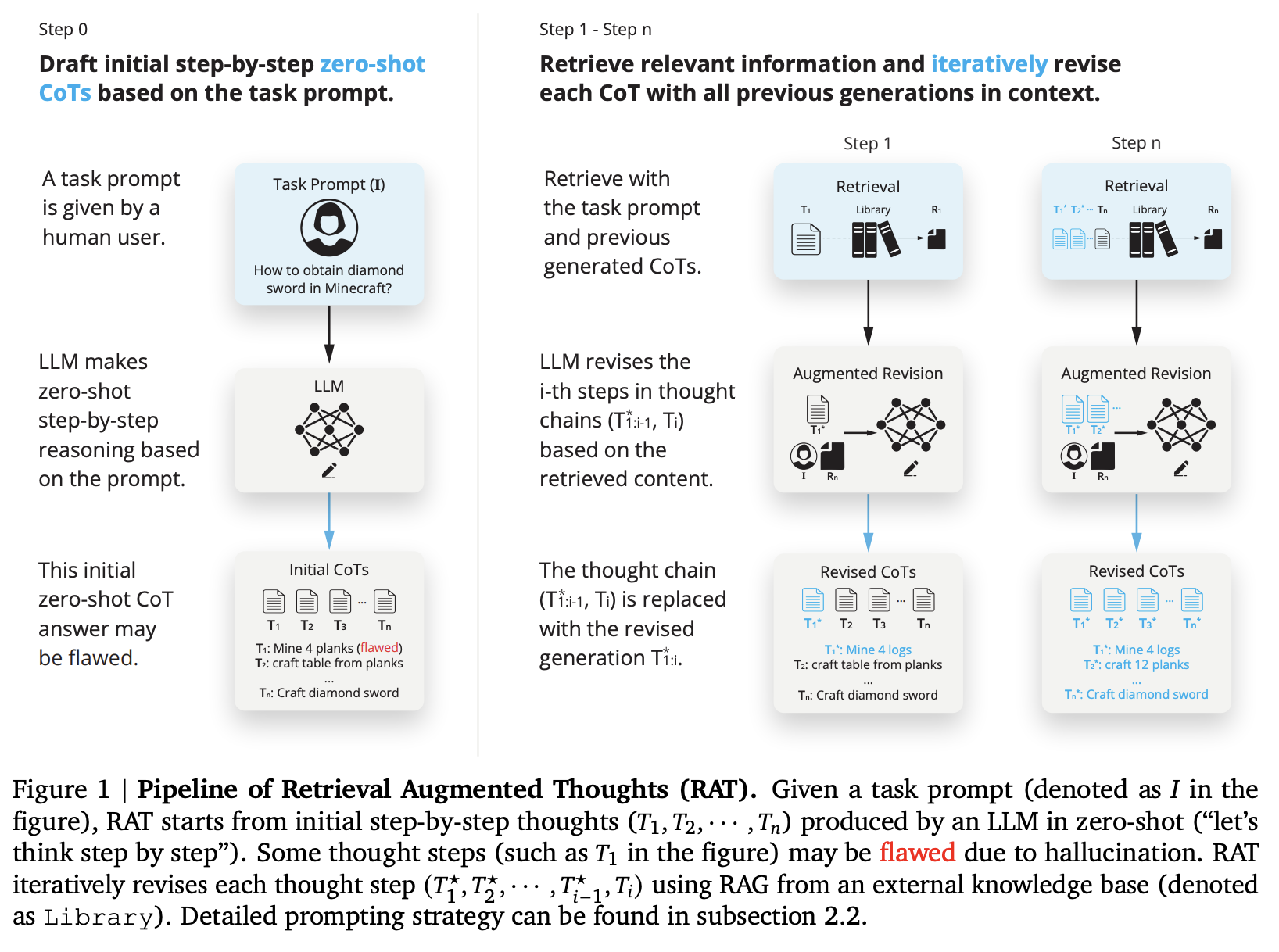
Bài báo đề xuất một cách tiếp cận để giảm thiểu các hạn chế liên quan đến CoT và RAG (đã trình bày ở phần trước) bằng cách áp dụng RAG để chỉnh sửa từng bước suy nghĩ được sinh ra bởi CoT. Cụ thể, khi có một yêu cầu nhiệm vụ , đầu tiên ta yêu cầu LLM tạo ra "chain-of-thoughts" từng bước, trong đó mỗi bước suy nghĩ được đại diện bởi , với là bước suy nghĩ thứ . Trong các nhiệm vụ tạo ra nội dung dài, có thể là các bước suy luận trung gian, ví dụ như pseudo code kèm theo chú thích trong bài toán code generation, dàn bài trong creative writing, hoặc thậm chí là dạng phác thảo câu trả lời,... Ý tưởng của RAT được mô tả trong hình trên.
Vì các bước suy nghĩ có thể không chính xác, ta sẽ sử dụng RAG để chỉnh sửa từng bước suy nghĩ trước khi tạo ra phản hồi cuối cùng từ những suy nghĩ này. Cụ thể, giả sử ta đã xác định các bước suy nghĩ trước đó và bây giờ chuẩn bị chỉnh sửa , ta sẽ bắt đầu bằng cách chuyển đổi văn bản thành một truy vấn :
trong đó có thể là một text encoder hoặc LLM dịch yêu cầu nhiệm vụ , các bước suy nghĩ hiện tại và trước đó thành một truy vấn mà hệ thống truy xuất có thể xử lý.
Tiếp theo, ta sẽ sử dụng RAG để truy xuất các tài liệu liên quan sử dụng , sau đó được thêm vào prompt để tạo ra một bước suy nghĩ đã được sửa đổi .
Tùy thuộc vào nhiệm vụ cụ thể, các bước suy nghĩ đã sửa đổi có thể được sử dụng trực tiếp làm phản hồi cuối cùng của mô hình. Đối với các nhiệm vụ như code generation hoặc creative writing, LLM sẽ được yêu cầu tạo ra phản hồi hoàn chỉnh (code, đoạn văn) từ mỗi bước suy nghĩ đã được chỉnh sửa một cách tuần tự.
Khi chỉnh sửa bước suy nghĩ thứ , thay vì chỉ sử dụng bước hiện tại hoặc toàn bộ chuỗi suy nghĩ để tạo ra truy vấn cho RAG, ta cần đảm bảo rằng truy vấn được tạo ra từ bước suy nghĩ hiện tại và các bước suy nghĩ đã được sửa đổi trước đó . Điều này có nghĩa là, ta sẽ áp dụng một phương pháp suy luận tuần tự để chỉnh sửa các suy nghĩ bằng RAG:
Cách làm này cho phép sửa chữa các lỗi trong những suy nghĩ ban đầu bằng cách liên tục tham khảo các thông tin khác nhau và đảm bảo rằng mỗi bước suy luận sử dụng thông tin chính xác và liên quan nhất, từ đó cải thiện đáng kể chất lượng và độ tin cậy của kết quả sinh ra.
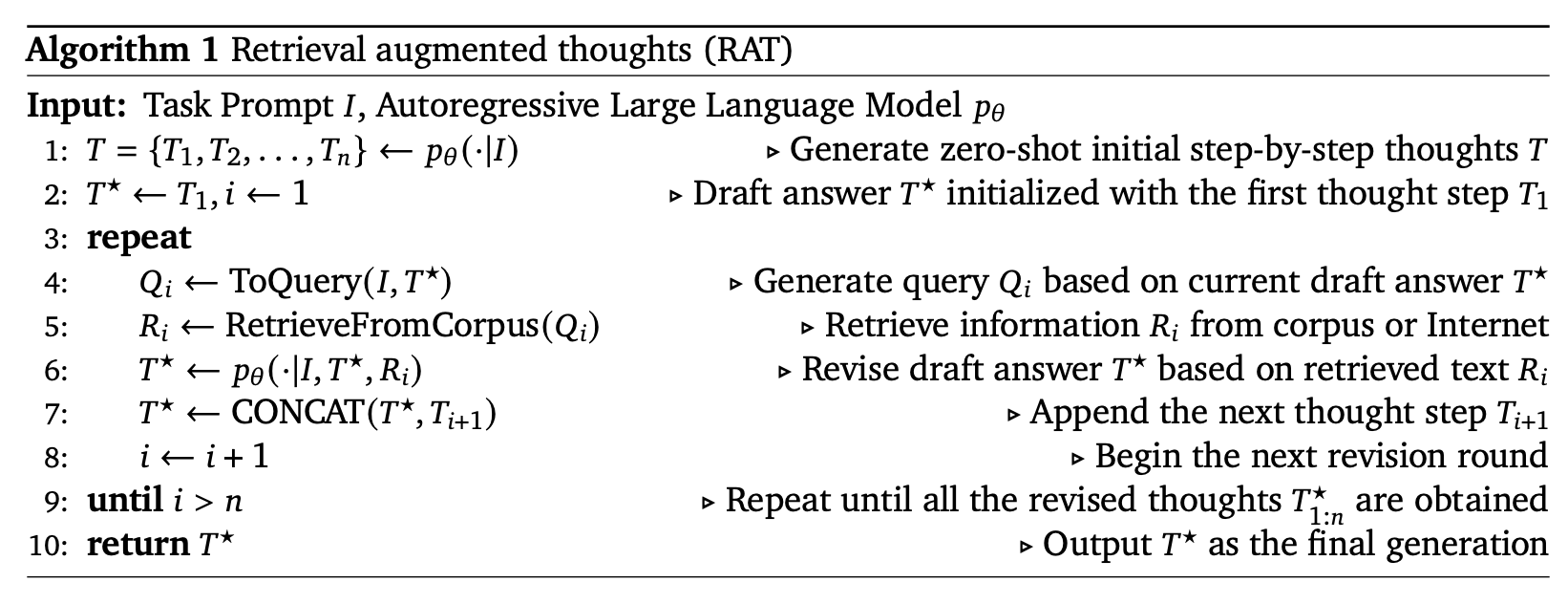
Cuối cùng, ta có một thuật toán hoàn chỉnh như sau:
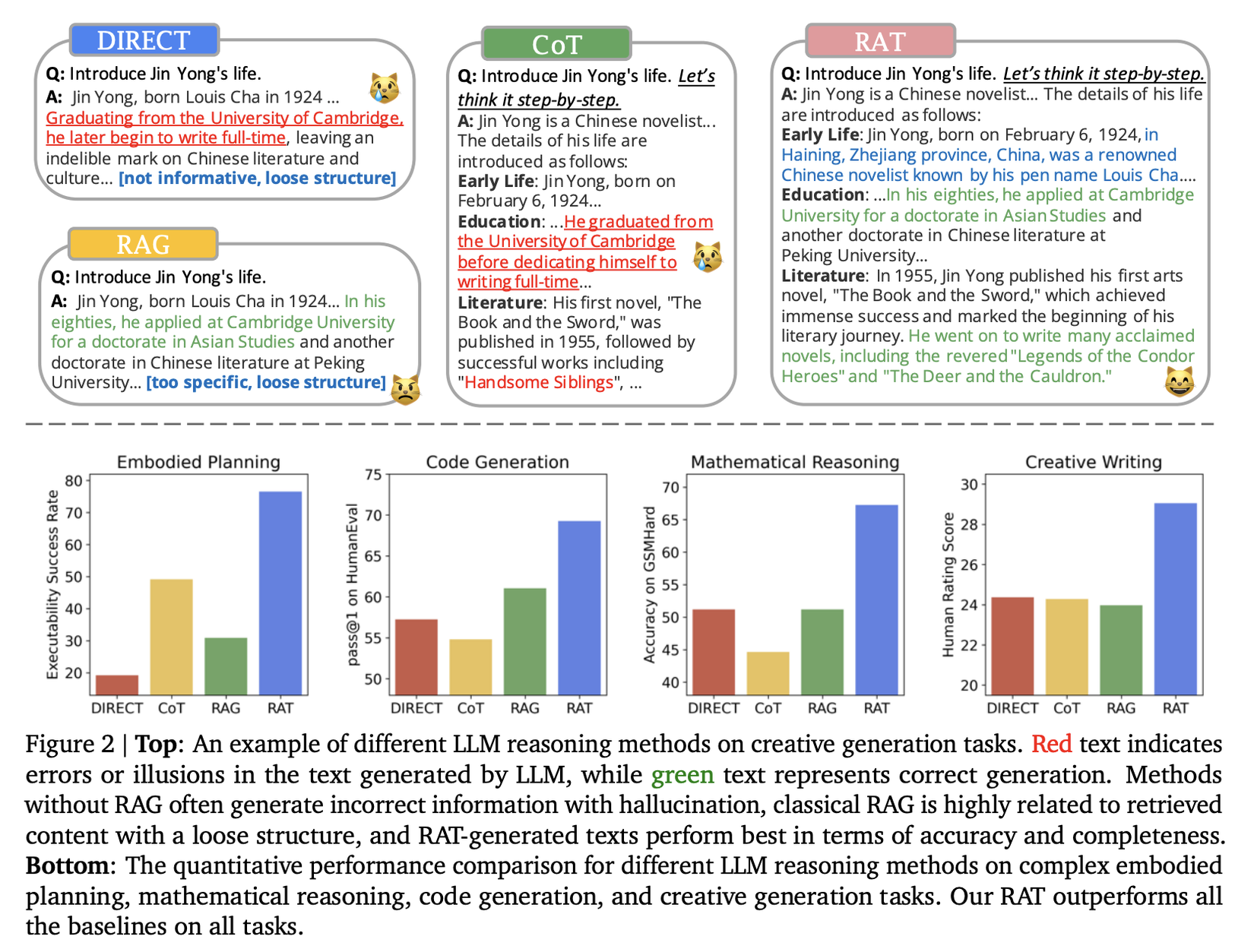
Kết quả khi so sánh RAT với các phương pháp khác:
Kết luận
Qua bài viết hi vọng các bạn sẽ có thêm một ý tưởng triển khai mới để cải thiện chất lượng phản hồi của LLM Agent của mình. RAT thể hiện sự hiệu quả với các tác vụ yêu cầu luồng suy luận nhiều bước và mỗi bước cần đảm bảo sự chuẩn chỉ vì chúng có liên quan tới nhau 
Tài liệu tham khảo
[1] RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
All rights reserved
