Machine Learning Lifecycle: Từ thu thập dữ liệu đến triển khai
1. Giới thiệu
Machine Learning (ML) không chỉ là xây dựng một mô hình, mà còn là một quy trình gồm nhiều bước từ thu thập dữ liệu, xử lý, huấn luyện mô hình đến triển khai và giám sát. Machine Learning Lifecycle giúp chúng ta hiểu rõ các giai đoạn cần thiết để đưa một mô hình ML vào ứng dụng thực tế một cách hiệu quả.
Ví dụ thực tế
Giả sử bạn đang xây dựng một hệ thống nhận diện biển số xe để tự động kiểm soát bãi đỗ xe. Bạn sẽ cần:
- Thu thập dữ liệu hình ảnh biển số từ camera.
- Xử lý hình ảnh để làm sạch dữ liệu.
- Huấn luyện mô hình để nhận diện số trên biển xe.
- Triển khai mô hình vào hệ thống.
- Giám sát và cập nhật mô hình theo thời gian.
Một ví dụ khác là phát hiện gian lận giao dịch thẻ tín dụng:
- Thu thập dữ liệu giao dịch từ ngân hàng.
- Xử lý dữ liệu để loại bỏ giá trị bất thường.
- Huấn luyện mô hình để phân loại giao dịch gian lận.
- Triển khai mô hình vào hệ thống ngân hàng.
- Giám sát và cập nhật mô hình khi hành vi gian lận thay đổi.
Trong bài viết này, chúng ta sẽ đi qua từng bước của vòng đời ML và cách thực hiện chúng một cách hiệu quả.
2. Các giai đoạn trong Machine Learning Lifecycle
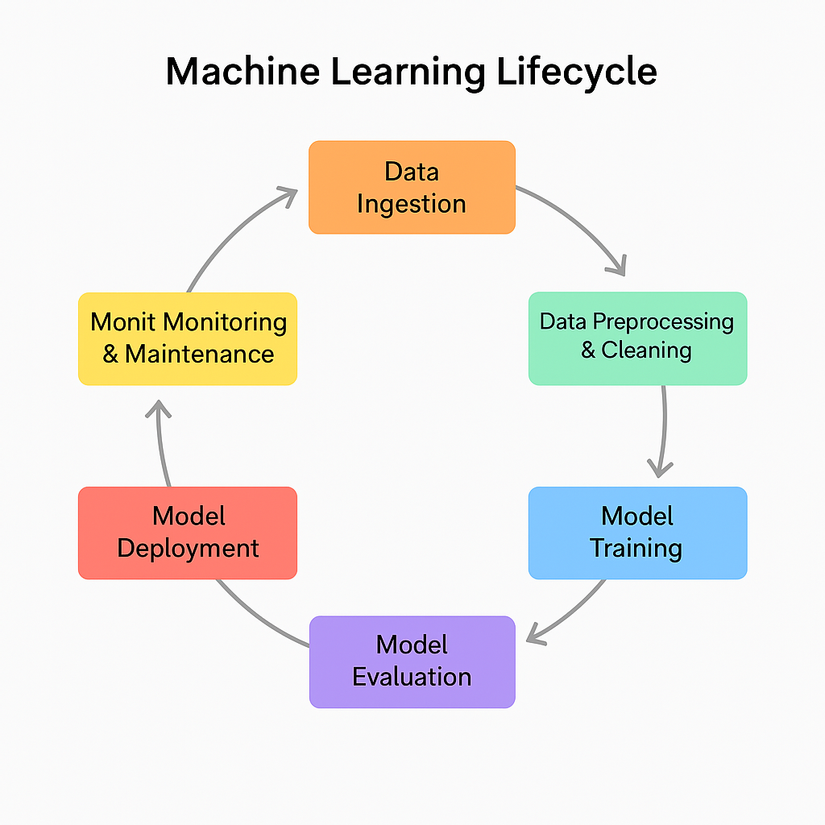
2.1. Thu thập dữ liệu (Data Ingestion)
Dữ liệu là yếu tố quan trọng nhất của bất kỳ dự án ML nào. Chất lượng dữ liệu ảnh hưởng trực tiếp đến hiệu suất mô hình.
Các công cụ sử dụng:
- Web Scraping: BeautifulSoup, Scrapy
- API & Streaming: Apache Kafka, AWS Kinesis
- Cơ sở dữ liệu: PostgreSQL, MongoDB
- Dữ liệu mở: Kaggle, Google Dataset Search
Ví dụ thực tế
- Nhận diện biển số xe: Thu thập hình ảnh biển số từ camera giao thông.
- Phát hiện gian lận giao dịch: Thu thập dữ liệu giao dịch ngân hàng, bao gồm số tiền, vị trí giao dịch, thời gian giao dịch.
2.2. Xử lý và làm sạch dữ liệu (Data Preprocessing & Cleaning)
Dữ liệu thu thập thường có lỗi, nhiễu hoặc thiếu thông tin. Việc tiền xử lý giúp cải thiện chất lượng dữ liệu đầu vào.
Các công cụ sử dụng:
- Xử lý dữ liệu: Pandas, NumPy
- Làm sạch dữ liệu: OpenRefine, Dask
- Chuẩn hóa & Biến đổi: Scikit-learn, TensorFlow Transform
Ví dụ thực tế
- Nhận diện biển số xe: Loại bỏ ảnh bị mờ hoặc có biển số không rõ ràng.
- Phát hiện gian lận giao dịch: Chuẩn hóa số tiền giao dịch, loại bỏ giao dịch trùng lặp.
2.3. Huấn luyện mô hình (Model Training)
Sau khi có dữ liệu sạch, bước tiếp theo là chọn thuật toán ML phù hợp và huấn luyện mô hình.
Các công cụ sử dụng:
- Học có giám sát: Scikit-learn, XGBoost, TensorFlow, PyTorch
- Học không giám sát: K-Means, PCA
- Học tăng cường: OpenAI Gym, Stable Baselines3
Ví dụ thực tế
- Nhận diện biển số xe: Huấn luyện CNN để nhận diện số trên biển số.
- Phát hiện gian lận giao dịch: Huấn luyện mô hình Random Forest hoặc XGBoost để phân loại giao dịch hợp lệ và gian lận.
2.4. Đánh giá mô hình (Model Evaluation)
Trước khi triển khai, cần kiểm tra hiệu suất mô hình bằng các chỉ số đánh giá.
Các công cụ sử dụng:
- Đánh giá mô hình: Scikit-learn Metrics, TensorBoard
- Phân tích lỗi: SHAP, LIME
Ví dụ thực tế
- Nhận diện biển số xe: Kiểm tra độ chính xác nhận diện biển số so với dữ liệu thực tế.
- Phát hiện gian lận giao dịch: Đánh giá Recall cao để giảm thiểu bỏ sót giao dịch gian lận.
2.5. Triển khai mô hình (Model Deployment)
Mô hình sau khi huấn luyện cần được triển khai để phục vụ người dùng.
Các công cụ sử dụng:
- Tạo API: Flask, FastAPI
- Đóng gói mô hình: Docker
- Triển khai trên Cloud: AWS SageMaker, GCP AI Platform, Kubernetes
Ví dụ thực tế
- Nhận diện biển số xe: Triển khai API nhận diện biển số bằng FastAPI.
- Phát hiện gian lận giao dịch: Tích hợp mô hình vào hệ thống ngân hàng để kiểm tra giao dịch theo thời gian thực.
2.6. Giám sát và cải thiện mô hình (Model Monitoring & Maintenance)
Sau khi triển khai, cần giám sát mô hình để phát hiện lỗi và cải thiện chất lượng.
Các công cụ sử dụng:
- Giám sát mô hình: MLflow, Prometheus, Grafana
- Phát hiện model drift: Evidently AI, WhyLabs
- Cập nhật mô hình: Kubeflow, Airflow
Ví dụ thực tế
- Nhận diện biển số xe: Cập nhật mô hình khi có biển số kiểu mới.
- Phát hiện gian lận giao dịch: Điều chỉnh mô hình theo xu hướng gian lận mới xuất hiện.
3. Kết luận
- Machine Learning Lifecycle là một quy trình gồm nhiều bước quan trọng từ thu thập dữ liệu đến triển khai và giám sát mô hình.
- Mỗi giai đoạn đều cần được thực hiện cẩn thận để đảm bảo mô hình hoạt động chính xác và hiệu quả.
- Trong bài tiếp theo, chúng ta sẽ đi sâu vào tổng quan các công cụ MLOps: MLflow, Kubeflow, DVC, TFX, giúp tự động hóa và nâng cao hiệu suất triển khai ML!
4. Nguồn tham khảo
- Aurélien Géron - Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
- Andrew Ng - Machine Learning Specialization (Coursera)
- Google Cloud - MLOps: Continuous delivery and automation pipelines in machine learning
- O'Reilly - Practical MLOps
Bạn có câu hỏi hoặc muốn tìm hiểu thêm về chủ đề này? Hãy để lại bình luận bên dưới!
All rights reserved
