Mì hảo hảo ăn liền - USING INDEX trong DATABASE
Hi các bạn, mình là Minh. Đnag làm việc tại team Core Payment Engine của Zalopay. Mục đích bài này chỉ là mong đem đến cho các bạn có cái nhìn tổng quan và chi tiết về INDEX trong database.
Feel free to comment, any idea always welcome !! 🤔🤔🤔

INDEX - Mục đích sinh ra để làm gì ? 🤔
có bao giờ trải nghiệm những câu query hàng chục giây chưa. hay những câu query ngốn tới tận trăm GB ram bộ nhớ. Thế thì bài viết này dành cho bạn đó. Let’s start
Mục đích index sinh ra để làm gì ?
Indexes are used to find rows with specific column values quickly.
Nếu không có index, mysql sẽ sử dụng chiến lược bắt đầu từ dòng đầu tiên và đọc toàn bộ bảng để tìm kiếm các dòng liên quan . Bảng càng lớn, chi phí bỏ ra càng lớn. Nhờ vào index mà mysql có thể nhanh chóng xác định vị trí dữ liệu cần tìm. Hãy tưởng tượng nó là cái mục lục khi chỉ cần dựa và key, bạn có thể xác định value mik cần tìm nhanh chóng với chi phí gần như là O(1).
Nhìn chung cách index hoạt động 👩🎨
Một index thông thường gồm 2 thành phần chính:
- 1 là khoá tìm kiếm (search key): Là giá trị cột hoặc tập hợp( composite) các cột được dùng để tìm kiếm
- 2 là con trỏ ( pointer) : Trỏ đến giá trị thực tế của dữ liệu
Khi được lưu trữ, index được tổ chức theo cấu trúc đã được sắp xếp, cho phép các thuật toán tìm kiếm hiệu quả như tìm kiếm nhị phân.
Đi sâu vào quá trình database hoạt động trên index 🤞
1. Quá trình tạo index 🧱
- Hệ quản trị CSDL như MYSQL quét qua tất cả các hàng trong bảng.
- Trích xuất giá trị của các cột được đánh index và kèm theo con trỏ đến bản ghi gốc
- Sắp xếp các cặp (giá trị, con trỏ) theo cấu trúc dữ liệu được chọn (thường là B-Tree hoặc B+Tree)
- Lưu trữ cấu trúc này như một đối tượng riêng biệt trong CSDL.
2. Quá trình tìm kiếm và sử dụng index 💂♂️
Khi một truy vấn được sử dụng trên cột đã đánh index thì chuyện gì sẽ xảy ra:
- Query optimizer xác định sẽ sử dụng index nào
- Hệ thống duyệt qua cấu trúc của index (mục 1)
- Ví dụ B-Tree, quá trình duyệt bắt đầu từ nút gốc, sau đó đi xuống các nút con cần tìm.
- Khi tìm thấy giá trị phù hợp trong index, lấy giá trị từ con trỏ tới giá trị gốc
3. Khi cập nhật index: 💂♂️
- Nếu thêm bản ghi mới, một mục mới được chèn vào index
- Nếu cập nhật bản ghi, mục index tương ứng được cập nhật hoặc di chuyển nếu giá trị key thay đổi
- Nếu xóa bản ghi, mục index tương ứng cũng bị xóa
Cấu trúc dữ liệu phổ biến cho Index 🐣
1. B-Tree và B+Tree
- Là 1 dạng cây tự cân bằng đa phương (balanced multiway tree). Để dễ hình dung, hãy nghĩ nó là tổng quát hoá của cây tìm kiếm nhị phân nhưng trong đó một nút có thể chứa nhiều hơn một khoá và có thể có nhiều hơn 2 nút con.
⇒. Cho những bạn chưa biết thì cây tìm kiếm nhị phân ( binary search tree) là 1 dạng đặc biệt của B-Tree.
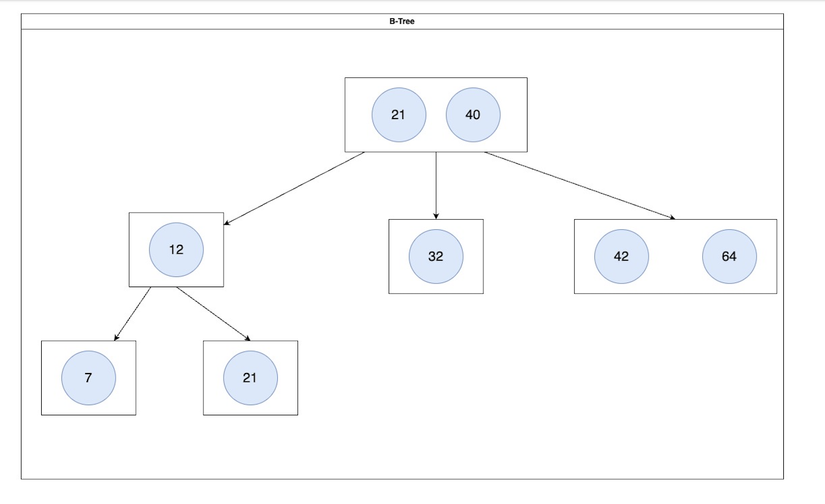
- B-Tree có những cặp key/value được chứa trong các node( hình bên dưới). Đặc biệt, trong database, key lúc này có thể là primary key hoặc indexed cột và dữ liệu là dòng đó hoặc con trỏ tới.
- Các node trong B-Tree ngoài việc chứa dữ liệu ra thì còn phải chứa con trỏ đến các dữ liệu khác. Vì các node thường chiếm 1 phần dung lượng của ổ đĩa nên là các con trỏ tới ID các các dữ liệu con nằm ở ổ đĩa khác ( mục đích là để không cần nạp toàn bộ cây vào RAM).
Để một cây được phân loại là B-tree, nó phải thỏa mãn các điều kiện sau:
- Các nút trong B-tree bậc
mcó thể có tối đamnút con và m-1 khoá. - Mỗi nút bên trong (tức là không phải nút lá và không phải nút gốc) phải có ít nhất
⌈m/2⌉nút con (làm tròn lên). - Nút gốc phải có ít nhất hai nút con – trừ khi nó là một nút lá.
- Một nút không phải lá với
knút con sẽ cók - 1khóa (key). - Tất cả các nút lá phải nằm trên cùng một tầng (cùng độ sâu).
-
B-Tree thì như trên đó, vậy B+Tree nó khác cái gì ? 🤔
-
Có 2 yếu tố mang B+Tree thành 1 dạng phổ biến ngay sau B-Tree.
- Tất cả các nút lá ( không có nút con) được lkieen kế với nhau - điều này tạo ra 1 double - linked list.
- Dữ liệu thực sự chỉ được lưu trữ ở nút lá - còn các nút con như 1 cái keeper giữ key thôi
2. Hash index
Hash index sử dụng hàm băm để ánh xạ giá trị khóa đến vị trí lưu trữ:
- Thời gian tìm kiếm lý tưởng là O(1) - không phụ thuộc vào kích thước dữ liệu
- Chỉ hiệu quả cho các truy vấn bằng (=) chính xác, không hỗ trợ truy vấn phạm vi hoặc so sánh lớn/nhỏ hơn
- Cơ chế xử lý collision rất phức tạp
3. Bitmap Index
Phù hợp cho cột có số lượng giá trị phân biệt thấp:
- Sử dụng ma trận bit, mỗi giá trị phân biệt tương ứng với một bitmap
- Mỗi bit trong bitmap đại diện cho một hàng trong bảng
- Rất hiệu quả cho các phép toán logic (AND, OR) giữa nhiều điều kiện
Chiến lược đọc dữ liệu từ Index mà database sử dụng tuỳ vào ngữ cảnh
1. Index Scan
- Duyệt qua các mục trong index theo thứ tự
- Phù hợp cho truy vấn phạm vi (range query)
⇒ Hiệu quả hơn so với table scan khi số lượng bản ghi cần truy xuất chiếm tỷ lệ nhỏ trong bảng
2. Index Seek
- Nhảy trực tiếp đến vị trí cụ thể trong index
- Phù hợp cho truy vấn điểm (point query)
⇒ Hiệu quả cao nhất khi tìm kiếm một hoặc số lượng nhỏ bản ghi
3. Index-Only Scan (Covering Index)
Này postgresql viết khá kĩ, bạn có thể đọc thử: https://www.postgresql.org/docs/current/indexes-index-only-scans.html
- Truy vấn được thực hiện hoàn toàn từ index mà không cần truy cập đến bảng dữ liệu
- Yêu cầu index chứa tất cả các cột cần thiết cho truy vấn
⇒ Hiệu suất cao nhất vì tránh được quá trình tìm kiếm thêm trong bảng dữ liệu nhưng kéo theo chi phí cao vì bạn phải đánh index tất cả, tưởng tượng có n cái cấu trúc dữ liệu cho việc query thì chán lắm rồi
Tác động của Index đến hiệu suất hệ thống
1. Lợi ích
- Giảm đáng kể thời gian truy vấn, đặc biệt với các bảng lớn
- Hỗ trợ các ràng buộc như UNIQUE, PRIMARY KEY
- Tối ưu hóa các phép JOIN và ORDER BY
- Đặc biệt hữu ích khi JOIN trên cột khoá chính (primary key) hoặc khoá ngoại (foreign key).
- Cột được sắp xếp có index phù hợp (như B-Tree đã nói ở trên)
2. Chi phí
- Tăng không gian lưu trữ - này cực kì phải để ý, thay vì 100% thì nay có thể lên tới 120% storage.
- Làm chậm các thao tác INSERT, UPDATE, DELETE vì phải cập nhật cả index
- Tăng thời gian xử lý cho các hoạt động bảo trì như backup, restore - phải cẩn thận vì database trên PROD ví dụ như 30 triệu mà bạn đánh index 1 cục thì có thể down system trong 1 thời gian đấy nhé.
Testing cái nhẹ nè
Chúng ta sẽ tạo 1 bảng customers với khoảng 7k datas
SQL create table:
CREATE TABLE IF NOT EXISTS customers (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
email VARCHAR(100),
phone VARCHAR(20),
city VARCHAR(50),
registration_date DATE,
income DECIMAL(12,2),
age INT,
status ENUM('active', 'inactive', 'pending') DEFAULT 'active'
);
SQL insert sử dụng with recursive as:
WITH RECURSIVE generate_data AS (
SELECT 1 as n
UNION ALL
SELECT n + 1 FROM generate_data WHERE n < 7000 # feel free to edit this
)
SELECT
CONCAT('Customer ', n),
CONCAT('customer', n, '@example.com'),
CONCAT('0', FLOOR(900000000 + RAND() * 99999999)),
ELT(1 + FLOOR(RAND() * 10), 'Hanoi', 'Ho Chi Minh', 'Da Nang', 'Hai Phong', 'Can Tho', 'Nha Trang', 'Hue', 'Vung Tau', 'Quy Nhon', 'Phan Thiet'),
DATE_SUB(CURRENT_DATE, INTERVAL FLOOR(RAND() * 1825) DAY),
5000000 + RAND() * 45000000,
18 + FLOOR(RAND() * 53),
ELT(1 + FLOOR(RAND() * 3), 'active', 'inactive', 'pending')
FROM generate_data;
Tìm các khách hàng tiềm năng ở khu vực Hà Nội 😊:
CREATE INDEX idx_customers_city
on customers (city);
EXPLAIN ANALYZE SELECT * FROM customers WHERE city = 'Hanoi';
Trước khi index:
-> Filter: (customers.city = 'Hanoi') (cost=603.75 rows=580) (actual time=0.190..8.521 rows=600 loops=1)
-> Table scan on customers (cost=603.75 rows=5795) (actual time=0.177..7.131 rows=6002 loops=1)
Sau khi index:
-> Index lookup on customers using idx_customers_city (city='Hanoi') (cost=132.75 rows=600) (actual time=0.506..4.431 rows=600 loops=1)
So sánh
- Cost: giảm từ 603 → 132
- Actual time: giảm từ 7.131 → 4.431
- Loạt scan: table scan → index look up
Kết luận
Index là "chìa khóa" giúp tăng tốc độ tìm kiếm dữ liệu trong cơ sở dữ liệu. Tùy vào mục đích sử dụng, bạn có thể chọn các loại index khác nhau như B-Tree, Hash hay Bitmap. Mỗi loại có những ưu điểm và nhược điểm riêng, ảnh hưởng đến tốc độ và hiệu quả của hệ thống. Điều quan trọng là phải hiểu rõ cách hoạt động của chúng để sử dụng đúng cách, giúp hệ thống hoạt động mượt mà mà không bị chậm lại.
Đối với các bài toán lớn ,data rơi vào vài chục triệu. Việc đánh index là không đủ, ta cần phải tìm hiểu thêm 1 khái niệm partition (TODO).
N
All rights reserved
