[MLOps] Model PVC Provisioning (MPP) - A way to ship large AI image to K8s
Một ngày đẹp trời, duyên phận đưa đẩy bạn và một project AI gặp nhau. Bạn sẽ phải CI/CD cho project đó lên K8s. Mọi thứ chẳng có gì để nói cho đến khi bạn nhìn thấy image size của các service.
Hai con số!. Bạn cảm thấy ngạc nhiên vì hiếm khi thấy image nào được tối ưu về 2 con số như vậy. Nhưng hết bất ngờ này đến bất ngờ khác, đơn vị kích thước là GB chứ không phải MB 🤯.

Cái này 10GB, cái kia 27GB . Bạn là một chuyên gia, luôn luôn tìm cách tối ưu container image một cách hoàn hảo, bạn sẽ không để vụ này chìm 👿.
Lời giới thiệu
Xin chào các bạn, mình là ThienNam, một DevOps thích chia sẻ và giao lưu kiến thức. Và đây là bài đầu tiên của mình, hi vọng bạn thích!
Lần đầu chưa biết nói gì, thôi thì mình hãy vào bài luôn nha!
Những cách triển khai AI service trên K8s hiện tại
Mình đã thấy ở nhiều nơi triển khai AI service và mình xin tổng hợp 2 cách triển khai phổ biến.
1. Code + Model = Image
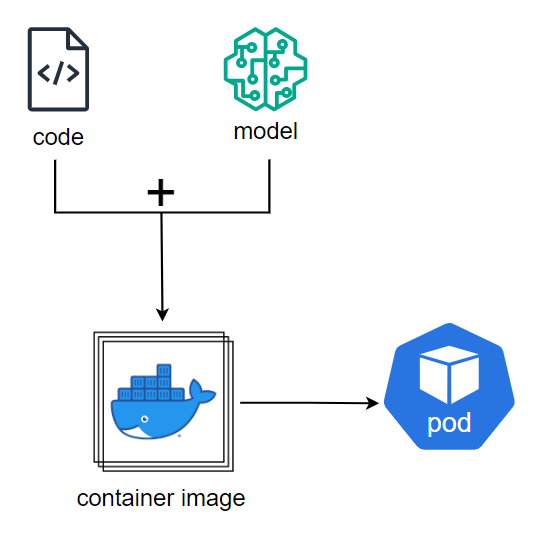
Cho tất cả vào image? Nghe thì đơn giản nhưng chi phí rất tốn kém.
Ưu điểm:
- Nhàn.
- Theo luồng, quy trình của các service thông thường.
Nhược điểm:
- Kích thước image lớn: Đặt gánh nặng lên Container Registry, nơi thường xuyên lưu trữ những image lightweight.
- Thời gian build lâu: Dù model có được đặt tại Git Repository hay Model Registry, thời gian CI pipeline cũng bị tăng thêm do runner phải download model về workspace rồi mới thực hiện build.
- Tần suất build lớn: Ràng buộc code và model trong cùng một phạm vi là image khiến cho việc chỉ update code hay model cũng dẫn tới phải build lại toàn bộ image.
- Quá khổ, quá tải: Việc transfer image qua lại giữa nhiều môi trường trở nên cồng kềnh, tốn thời gian và các tài nguyên hệ thống.
2. Download model in startup time
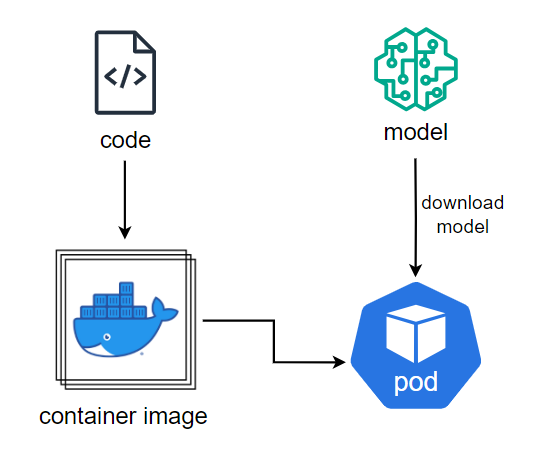
Service sẽ pull model khi Pod được tạo.
Ưu điểm:
- Image size được tối ưu.
- Service và model được ràng buộc chặt chẽ.
Nhược điểm:
- Thời gian khởi động lâu: Thời gian khởi động của service có thể kéo dài hàng phút do phải download model ngay khi tạo xong container.
- Tiêu tốn tài nguyên network của cụm: Khi download service có thể chiếm dụng băng thông của cụm K8s gây ra ảnh hưởng tới các service khác.
- Dễ bị lỗi không khởi động được: Model lớn, thời gian download lâu dễ dàng bị gián đoạn khiến cho pod không thể chạy được và có thể gây ra infinity loop nếu pod bị restart.
- Logic cồng kềnh: Source code phải implement bổ sung phần download.
Giải quyết vấn đề
Cách này không được, cách kia cũng không vậy thì làm thế nào để triển khai AI service lớn lên K8s?
Không triển khai nữa là xong! - mình không nói thế 🤐🫣.
Như tiêu đề bài viết, chúng ta có thể đặt model trong PVC. Không dài dòng nữa, mình sẽ show từng bước cách làm rất đơn giản.
Kiến trúc triển khai
Dưới đây là kiến trúc của mô hình MPP.
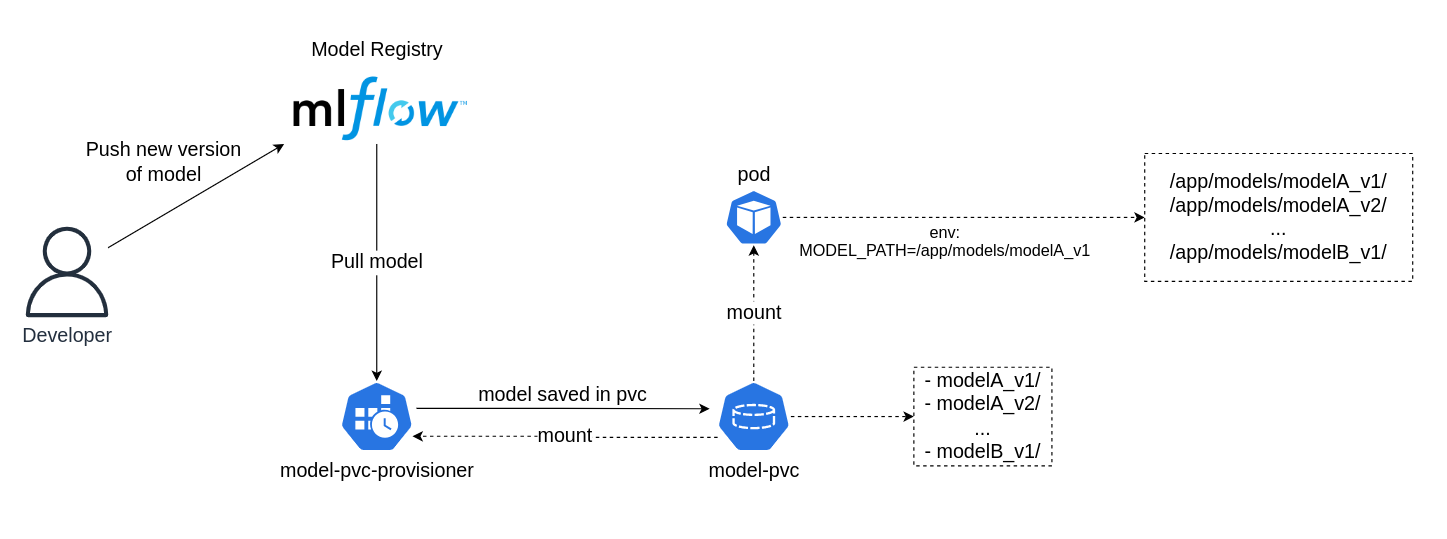
1. Model Registry
Tương tự như container image, model cũng có nơi lưu trữ gọi là Model Registry. Developer sau khi training xong sẽ push model lên Model Registry để lưu trữ, đánh version và tag.
2. MPP Tool
MPP tool sẽ pull model về và lưu trữ trong PVC. Nếu model đã pull rồi thì bỏ qua.
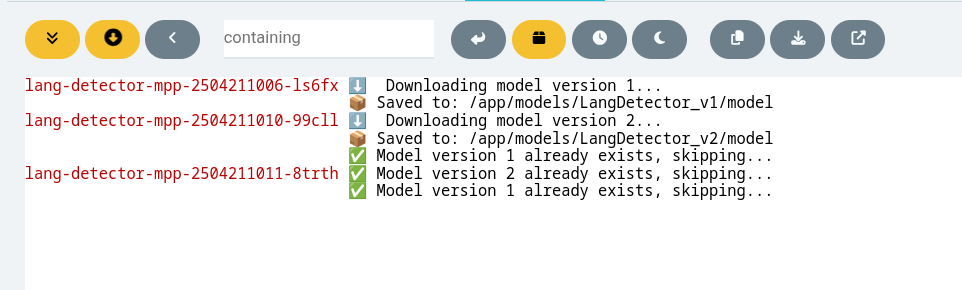
3. Model PVC Provisioning
PVC được mount vào pod
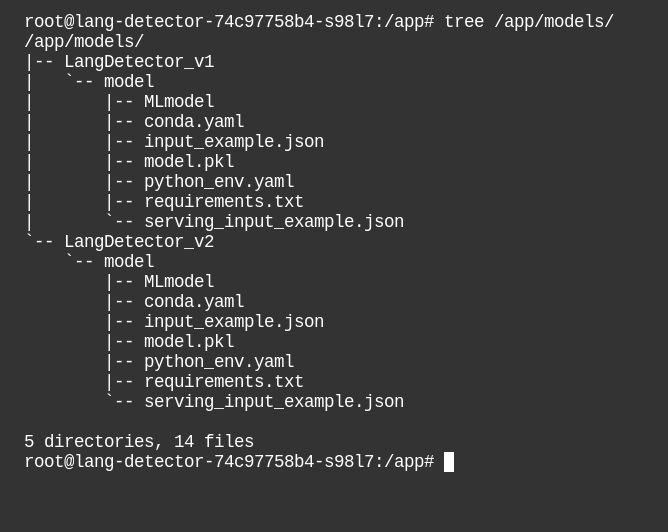
AI service sẽ sử dụng các model trong PVC đó thông qua biến môi trường MODEL_PATH.

4. Final
Và đây là tổng hợp những gì chúng ta sẽ có, đầy đủ mọi thứ cho 1 AI service ready.
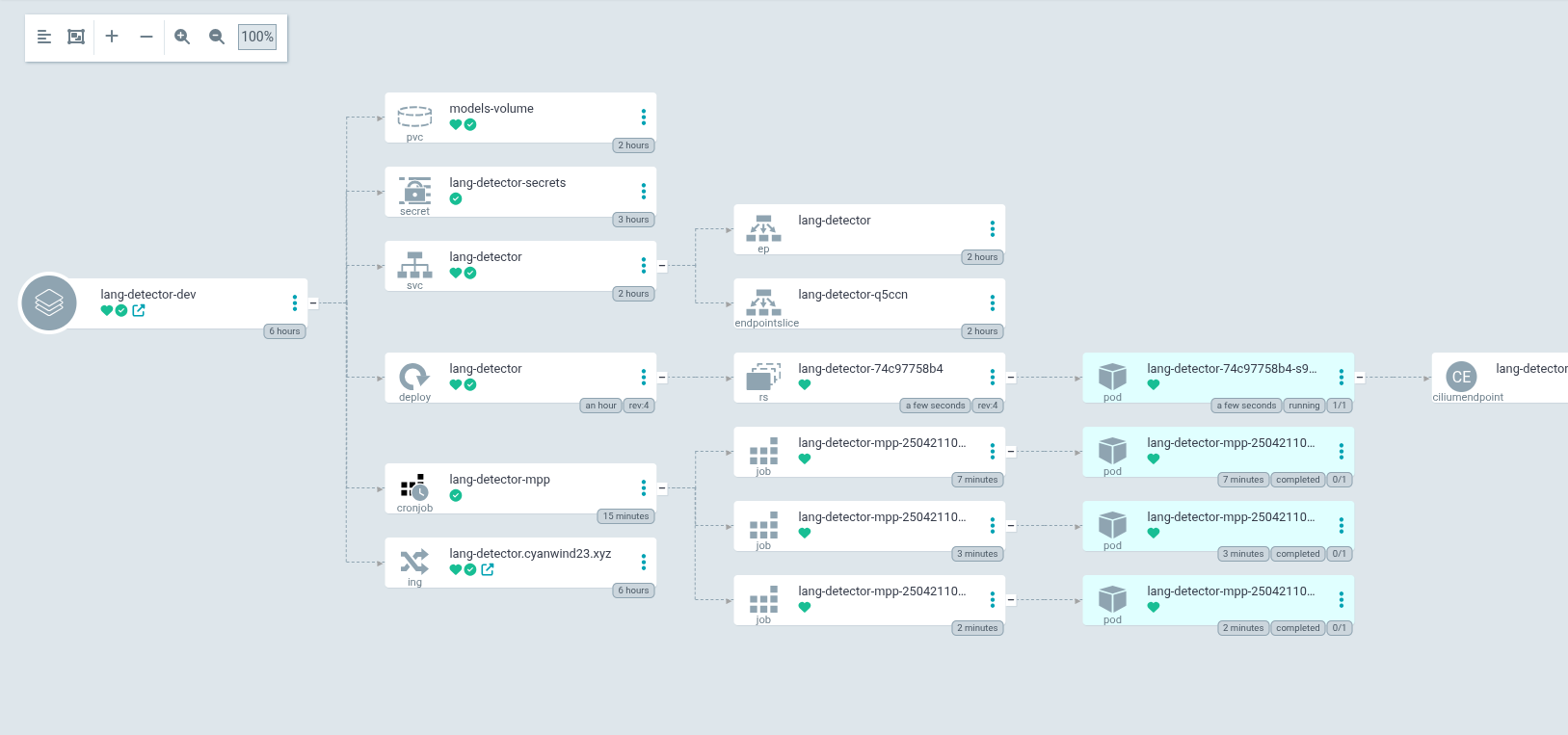
Đánh giá ưu nhược điểm
1. Ưu điểm
- Giải quyết các vấn đề của 2 phương pháp trên.
- Tối thiểu hóa việc transfer model qua lại giữa các môi trường trong hạ tầng.
- Có thể chia sẻ model giữa nhiều service AI trong cùng một namespace (mount chung PVC).
- Có thể dễ dàng thay đổi model qua lại bằng cách đổi env MODEL_PATH.
2. Nhược điểm
- Phase CD sẽ phức tạp hơn so với những service thông thường. Ví dụ: cần chuẩn bị StorageClass cho PVC, implement MPP tool, v.v...
- Yêu cầu nhiều nỗ lực của các team để thay đổi.
FAQ
Bây giờ mình xin đến tiết mục trả lời một số câu hỏi có thể bạn thắc mắc.
Q: MPP tool được thiết kế như thế nào?
A: MPP tool không có một cách thức implement cụ thể nào. MPP tool được thiết kế dựa trên nhiều yếu tố, nhu cầu của tổ chức của bạn như:
- Model Registry: mlflow, MinIO/S3, Google Drive, v.v...
- Cách tổ chức model: Những service nào dùng những model nào và những version nào. Ví dụ 1 model có thể được đánh tag, mỗi tag mang tên service sẽ sử dụng model đó. Như vậy MPP tool sẽ pull những model có tag của service đang được deploy.
- Cách serving AI service: Ví dụ như Triton Server, mình thấy có nhiều tổ chức sử dụng nhưng thời điểm hiện tại mình vẫn chưa biết nó như nào nên cũng chưa rõ mô hình MPP có phù hợp hay không, cần phải thay đổi như nào để có thể tích hợp.
- ...
Tuy nhiên nếu để tham khảo thì MPP tool về cơ bản sẽ có những đặc điểm sau:
- Pull đầy đủ các model và version cho service đang được deploy.
- Tối ưu action pull bằng cách kiểm soát trạng thái model đã pull, skip khi không cần thiết.
Bạn có thể phát triển nó thành một Operator để maintain Model PVC cho toàn cụm, cũng có thể phát triển thêm các cấu hình để tùy biến hành vi của tool.
Q: Tại sao trong hình MPP tool là CronJob mà không phải Deployment, Pod hay gì khác?
A: Theo mình nghĩ CronJob là hợp lý bởi nhu cầu:
- Cần một container có thể chạy lệnh pull xong và
Completed-> Job,initContainerskhông hợp lý vì nó sẽ tương tự như việc download model khi Pod start. - Cần linh hoạt giữa việc pull tự động và pull thủ công. -> CronJob vừa schedule hoặc manual create Job bằng
kubectl create job --from=cronjob/<name>. - Cần update model mới sớm nhất có thể -> CronJob (interval)
- Retry nếu pull bị gián đoạn -> Job
==> CronJob
Tuy nhiên bạn có thể tùy ý triển khai như câu trả lời bên trên, thậm chí có thể phát triển nó thành Operator.
Q: Trường hợp service đó sử dụng nhiều model với nhiều version khác nhau thì sao?
A: Khi service sử dụng nhiều model thì trong source code cần phải có nhiều env MODEL_PATH như MODEL_A_PATH, MODEL_B_PATH và việc triển khai sẽ chỉ cần đảm bảo MPP tool pull đủ model và env trong manifest được khai báo đầy đủ cho source code chạy.
Lưu ý:
- PVC Access Modes là
ReadWriteManyđể có thể share giữa MPP tool và các AI service.
Tổng kết
Hết rồi á! Nếu còn câu hỏi hay đóng góp ý vui lòng feedback đến mình nha. Lần đầu viết bài có thể không được mượt lắm mong mọi người thông cảm.
Và trên hết, xin cảm ơn các bạn đã đọc!!!
References
- Blog: IBM - Serving AI Models from Kubernetes Persistent Volumes with KServe ModelMesh - Link
Sau khi mình có được idea và vọc vạch PoC một hồi mới đi search gg thì tìm được blog này cũng chung idea. Các bạn có thể tham khảo.
All rights reserved
