Những vấn đề trong hệ thống phân tán (phần 2)
(rely on Designing Data-Intensive Applications)
Nối tiếp phần 1: Những vấn đề trong hệ thống phân tán (part 1)
3.Đồng hồ không đáng tin cậy
- Has this request timed out yet?
- What’s the 99th percentile response time of this service?
- How many queries per second did this service handle on average in the last five minutes?
- How long did the user spend on our site?
- When was this article published?
- At what date and time should the reminder email be sent?
- When does this cache entry expire?
- What is the timestamp on this error message in the log file?
Câu hỏi 1-4 nói về khoảng thời gian, trong khi đó câu hỏi 5-8 nói về thời điểm. Trong hệ thống phân tán, quản lý thời gian rất khó khăn vì việc truyền dữ liệu qua mạng không tức thời. Một tin nhắn luôn được nhận muộn hơn thời điểm gửi, nhưng do độ trễ mạng biến đổi, ta không thể biết chính xác khoảng cách thời gian này. Điều này khiến việc xác định thứ tự thực sự của các sự kiện trên nhiều máy trở nên phức tạp.
Ngoài ra, mỗi máy có một đồng hồ riêng, thường dựa trên bộ dao động tinh thể thạch anh, có thể chạy nhanh hoặc chậm hơn so với máy khác. Để giảm sai lệch thời gian (clock drift), hệ thống sử dụng Network Time Protocol (NTP) để đồng bộ với các máy chủ thời gian. Những máy chủ này thường lấy thời gian từ các nguồn cực kỳ chính xác như GPS receivers.
3.1 Monotonic Versus Time-of-Day Clocks
Monotonic clocks
Thích hợp đo duration, VD timeout hay thời gian response của 1 service.
Tiêu biểu: clock_gettime(CLOCK_MONOTONIC) trên Linux hoặc System.nanoTime() trong Java. Thời gian này luôn tăng và sẽ không nhảy ngược chưa time-of-day clock
Đối với monotonic clock, điều quan trọng là difference giữa hai thời điểm. Giá trị thực sự của đồng hồ là vô nghĩa. Việc lấy khoảng thời gian monotonic giữa 2 thời điểm khác nhau trên 2 máy khác nhau cũng vô nghĩa luôn, bởi lẽ ý nghĩa thời gian trên 2 máy là khác nhau
Trên hệ thống nhiều CPU, mỗi CPU có timer riêng, hệ điều hành cố gắng đồng bộ nhưng vẫn có sai số nhỏ. NTP có thể điều chỉnh tốc độ chạy (slewing) nhưng không làm monotonic clock nhảy lùi hoặc tiến đột ngột. Độ phân giải cao (microsecond hoặc tốt hơn), phù hợp để đo timeouts, latency, nhưng không thể dùng để đồng bộ thời gian giữa nhiều máy
Time of day clocks
Giống như cách chúng ta expect ở 1 cái đồng hồ, dùng để lấy thời gian hiện tại
Tiêu biểu: clock_gettime(CLOCK_REALTIME) trên Linux và System.currentTimeMillis() trong Java trả về số seconds/milliseconds từ lúc epoch
Thời gian này thường được đồng bộ với NTP
Nhược điểm:
- Có thể nhảy lùi nếu đồng hồ hệ thống bị đặt quá xa so với NTP server
- Không chính xác để đo thời gian trôi qua vì có thể bỏ qua giây nhuận
- Độ phân giải thấp trên hệ thống cũ (Windows trước đây cập nhật mỗi 10ms)
Với đồng hồ chạy bằng thạch anh, thời gian ban đầu set giống nhau và mọi thiết lập ban đầu đều giống nhau, thì 2 máy khác nhau tại 1 thời điểm trong tương lai sẽ có thời gian giống nhau không? Câu trả lời là không, vì tần số dao động thạch anh khác nhau do sai số vật lý, nhiệt độ dao động của thạch anh cũng ảnh hưởng bởi nhiệt độ
NTP
NTP sử dụng cấu trúc phân tầng (stratum) để đồng bộ thời gian:
| Stratum | Mô tả |
|---|---|
| Stratum 0 | Đồng hồ tham chiếu (Reference Clocks) như GPS, đồng hồ nguyên tử. |
| Stratum 1 | Máy chủ NTP lấy thời gian trực tiếp từ Stratum 0. |
| Stratum 2 | Máy chủ NTP đồng bộ với Stratum 1, sau đó cung cấp thời gian cho các máy khác. |
| Stratum 3+ | Các tầng tiếp theo lấy thời gian từ tầng trên, có thể sai lệch nhiều hơn. |
🔹 Máy tính của bạn thường đồng bộ với NTP Server Stratum 2 hoặc 3 để tránh quá tải lên Stratum 1.
Một số NTP Server phổ biến:
✅ Công khai:
- pool.ntp.org (Cộng đồng, nhiều máy chủ trên toàn cầu).
- time.google.com (Google cung cấp, có "leap smearing").
- time.apple.com (Dành cho thiết bị Apple). ✅ Riêng tư:
- Doanh nghiệp lớn có thể tự dựng NTP Server nội bộ, đồng bộ với nguồn chính xác như GPS hoặc đồng hồ nguyên tử.
Clock Synchronization và Độ chính xác
Time-of-day clocks cần được đồng bộ theo NTP hoặc theo 1 chuẩn time nào đó khác. Xu cà na ở chỗ, phương pháp lấy giờ không gần với việc đáng tin cậy hay chính xác như cách you chờ mong. Đồng hồ phần cứng và NTP khó lường:
1️⃣ Clock Drift: Đồng hồ thạch anh không chính xác, bị ảnh hưởng bởi nhiệt độ. Google giả định độ trôi 200 ppm, gây lệch 6ms mỗi 30 giây hoặc 17 giây mỗi ngày.
2️⃣ Lỗi đồng bộ với NTP: Nếu đồng hồ máy lệch quá nhiều so với NTP server, có thể bị từ chối đồng bộ hoặc reset đột ngột, làm thời gian nhảy lùi hoặc tiến.
3️⃣ Bị chặn bởi tường lửa: Nếu node bị firewall chặn truy cập NTP, lỗi có thể không được phát hiện ngay.
4️⃣ Độ trễ mạng ảnh hưởng đến độ chính xác: Trên mạng tắc nghẽn, đồng bộ NTP có thể sai ít nhất 35ms, đôi khi lệch đến 1 giây.
5️⃣ NTP server sai lệch hoặc bị cấu hình sai: Một số NTP server báo thời gian sai lệch đến vài giờ, dù hầu hết client có cơ chế bỏ qua giá trị bất thường.
6️⃣ Giây nhuận (Leap Second) gây lỗi: Một phút có thể dài 59 hoặc 61 giây, làm sập hệ thống nếu không được thiết kế để xử lý. Một số NTP server áp dụng smearing (điều chỉnh dần) thay vì cập nhật đột ngột.
7️⃣ Máy ảo gặp vấn đề với đồng hồ hệ thống: Khi CPU bị chia sẻ giữa các VM, mỗi VM có thể bị pause trong vài chục ms, làm thời gian nhảy đột ngột.
8️⃣ Người dùng cố ý đặt sai giờ: Trên thiết bị di động hoặc nhúng, người dùng có thể đặt thời gian sai để lách giới hạn thời gian trong ứng dụng.
Độ chính xác có thể đạt được qua nhận dữ liệu từ GPS, Precision Time Protocol(PTP), deployement và monitoring cẩn thận. Tuy nhiên sẽ đánh đổi nhiều công sức và cần chuyên môn cao. PTP yêu cầu cầu phần cứng chuyên biệt, được thiết kế cho mạng LAN hoặc mạng riêng.
Đồng bộ đồng hồ và độ chính xác
Đồng hồ hệ thống không đơn giản như vẻ ngoài – nó có thể nhảy lùi, trôi lệch theo thời gian và không đồng bộ giữa các máy, gây lỗi tinh vi trong hệ thống phân tán. Giống như lỗi mạng, dù hiếm gặp nhưng phần mềm phải sẵn sàng xử lý. Sai lệch thời gian khó phát hiện vì máy vẫn hoạt động bình thường dù clock drift ngày càng lớn, có thể dẫn đến mất dữ liệu âm thầm thay vì lỗi rõ ràng. Giám sát clock offset giữa các máy và loại bỏ node bị lệch quá xa là cách tốt nhất để tránh lỗi nghiêm trọng.
Timestamps cho event tuần tự
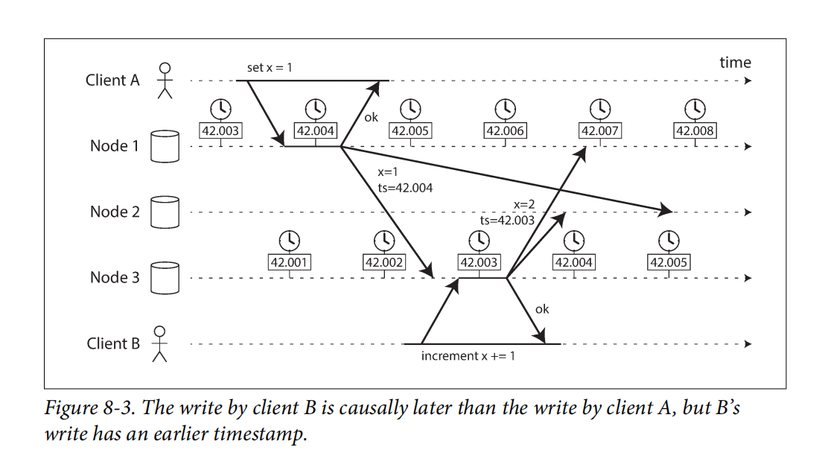
Hình 8.3 mô tả: Client A write x = 1 vào node 1, sau đó nó replicate sang node 3 và 2. Tại node 3, nó thực hiện x+=1 sau đó replicate lại sang node 2. Do thời gian trên hai node 1 và node 3 đang lệch nhau -> update trên node 3 bị ghi đè (Last Write Wins strategy).
So-called logical clocks [56, 57], which are based on incrementing counters rather than an oscillating quartz crystal, are a safer alternative for ordering events (see “Detecting Concurrent Writes” on page 184). Logical clocks do not measure the time of day or the number of seconds elapsed, only the relative ordering of events (whether one event happened before or after another). In contrast, time-of-day and monotonic clocks, which measure actual elapsed time, are also known as physical clocks. We’ll look at ordering a bit more in “Ordering Guarantees” on page 339.
Giới hạn độ chính xác cho đồng hồ
Time-of-day clock có thể đọc với độ phân giải microsecond hoặc nanosecond, nhưng không đảm bảo độ chính xác cao do clock drift và độ trễ mạng. Với NTP trên Internet, sai số thường vài chục ms, có thể vượt 100ms khi mạng tắc nghẽn. Vì vậy, thời gian nên được xem là một khoảng (confidence interval) thay vì một giá trị cố định. Tuy nhiên, hầu hết hệ thống không hiển thị sai số này, khiến timestamp có thể kém tin cậy. Google Spanner TrueTime API khắc phục bằng cách trả về [earliest, latest], giúp xác định khoảng thời gian chính xác hơn.
Đồng bộ đồng hồ cho global snapshot
Snapshot Isolation (SI) giúp giao dịch chỉ đọc thấy dữ liệu nhất quán mà không ảnh hưởng đến giao dịch đọc-ghi. Trong hệ thống phân tán, việc tạo transaction ID đơn điệu tăng dần gặp khó khăn vì cần phản ánh quan hệ nhân quả giữa các giao dịch, tránh nghẽn hệ thống.
🔹 Giải pháp của Google Spanner:
- Dùng time-of-day clock đồng bộ làm transaction ID thông qua TrueTime API, trả về confidence interval [earliest, latest].
- Nếu hai transaction không trùng khoảng thời gian, có thể chắc chắn transaction sau diễn ra muộn hơn.
- Nếu trùng, Spanner buộc transaction sau phải chờ một khoảng thời gian bằng độ lệch đồng hồ trước khi commit.
- Google sử dụng GPS hoặc đồng hồ nguyên tử tại mỗi datacenter, giúp giảm sai số xuống ≈7ms, rút ngắn thời gian chờ.
Việc đồng bộ đồng hồ để đảm bảo thứ tự giao dịch vẫn đang được nghiên cứu và hiện chỉ Google Spanner triển khai, chưa phổ biến ở các CSDL khác.
Process Pauses
4. Knowledge, Truth and Lie
Cho đến nay, chúng ta đã thấy những điểm khác biệt giữa hệ thống phân tán và chương trình chạy trên một máy đơn. Trong hệ thống phân tán:
-
Không có bộ nhớ chung, các node chỉ có thể giao tiếp với nhau qua mạng không đáng tin cậy, với độ trễ thay đổi.
-
Hệ thống có thể gặp lỗi một phần (partial failures), đồng hồ có thể không chính xác, và tiến trình có thể bị tạm dừng bất chợt.
Những vấn đề này có hệ quả khá phức tạp. Một node trong mạng không thể biết chắc chắn điều gì, nó chỉ có thể đưa ra phỏng đoán dựa trên các thông điệp nhận được hoặc không nhận được. Node chỉ có thể xác định trạng thái của một node khác (dữ liệu nó lưu trữ, liệu nó có hoạt động bình thường không, v.v.) bằng cách gửi tin nhắn và chờ phản hồi. Nếu một node không phản hồi, không có cách nào biết được nguyên nhân là do lỗi mạng hay do node đó thực sự đã chết.
Vấn đề này đôi khi mang tính triết học:
-
Làm sao chúng ta có thể biết chắc điều gì về hệ thống?
-
Nếu cơ chế quan sát và đo lường (mạng, đồng hồ, tiến trình) không đáng tin cậy, làm sao có thể đảm bảo sự thật?
-
Phần mềm có cần tuân theo các quy luật vật lý như nhân quả (cause and effect) không?
Tuy nhiên, thay vì đi quá xa vào những câu hỏi triết học, ta có thể tiếp cận vấn đề theo hướng thực tế hơn. Ta có thể xác định các giả định về hành vi của hệ thống (mô hình hệ thống - system model) và thiết kế thuật toán để đảm bảo hoạt động chính xác trong mô hình đó. Một số thuật toán có thể được chứng minh là đúng trong một mô hình hệ thống cụ thể, ngay cả khi hệ thống thực tế có nhiều điểm không đáng tin cậy.
Dù vậy, việc làm cho phần mềm hoạt động chính xác trong môi trường phân tán không hề đơn giản. Trong phần tiếp theo, chúng ta sẽ đi sâu vào khái niệm "kiến thức và sự thật" trong hệ thống phân tán, giúp ta hiểu rõ hơn những giả định có thể đặt ra và các đảm bảo có thể cung cấp. Bài viết tiếp theo sẽ tiếp tục với các thuật toán phân tán quan trọng, giúp giải quyết những vấn đề thực tế dựa trên các giả định cụ thể.
Số đông quyết định truth
Hãy tưởng tượng một mạng gặp lỗi bất đối xứng: một node có thể nhận tất cả tin nhắn gửi đến, nhưng mọi tin nhắn nó gửi đi đều bị mất hoặc trì hoãn.
Mặc dù node này vẫn hoạt động bình thường và nhận được yêu cầu từ các node khác, nhưng không ai nghe thấy phản hồi của nó. Sau một khoảng thời gian chờ đợi, các node khác tuyên bố nó đã chết vì không nhận được bất kỳ phản hồi nào.
Tình huống diễn ra như một cơn ác mộng: node bị cô lập một phần cố gắng kêu cứu "Tôi vẫn còn sống!", nhưng vì không ai nghe thấy, nó vẫn bị kéo vào "nghĩa địa", bất lực chống cự, trong khi các node khác kiên quyết tiếp tục "đám tang" của nó.
Ở một kịch bản ít kinh hoàng hơn, node bị cô lập một phần có thể nhận ra rằng tin nhắn nó gửi đi không được xác nhận, nên nó hiểu rằng có vấn đề với mạng. Tuy nhiên, nó vẫn bị các node khác coi là đã chết mà không thể làm gì để ngăn chặn tình huống này.
Giờ hãy tưởng tượng một kịch bản khác: một node gặp GC pause kéo dài. Tất cả các luồng bị dừng hoàn toàn trong một phút để thực hiện garbage collection, khiến:
-
Không có yêu cầu nào được xử lý.
-
Không có phản hồi nào được gửi đi.
-
Các node khác chờ đợi, thử gửi lại yêu cầu, rồi mất kiên nhẫn và tuyên bố node này đã chết.
Sau một phút, GC hoàn thành, các luồng tiếp tục chạy như thể không có gì xảy ra. Nhưng lúc này, các node khác đã loại bỏ node này khỏi hệ thống.
Tình huống này giống như một bộ phim kinh dị: node "đã chết" bất ngờ bật dậy từ quan tài, khỏe mạnh như chưa có chuyện gì xảy ra, và vui vẻ trò chuyện với các node khác, trong khi những node này vẫn còn sốc nặng vì nghĩ rằng nó đã biến mất mãi mãi.
Điều thú vị là từ góc nhìn của node bị GC pause, dường như thời gian không hề trôi qua. Nó không nhận ra rằng đã bị coi là "chết", bởi vì với nó, chỉ mới một khoảnh khắc ngắn trôi qua từ lần cuối nó giao tiếp với các node khác
Trong hệ thống phân tán, một node không thể tự tin vào đánh giá của chính nó, vì có thể gặp lỗi mà không nhận ra. Để tránh phụ thuộc vào một node duy nhất, hệ thống sử dụng quorum (biểu quyết giữa nhiều node), trong đó một quyết định chỉ hợp lệ khi có đa số node đồng ý (>50%).
Điều này áp dụng cả khi xác định một node đã chết: nếu quorum bỏ phiếu rằng node đã chết, nó phải chấp nhận kết quả, dù vẫn hoạt động. Quorum đảm bảo hệ thống vẫn hoạt động khi một số node hỏng và tránh xung đột giữa các quyết định mâu thuẫn.
Leader và lock
HBase từng gặp case này: (giống với đoạn code ta bàn trong phần process pauses)
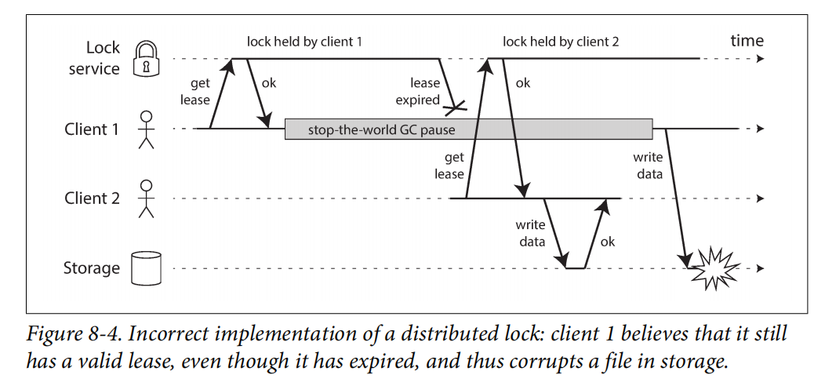
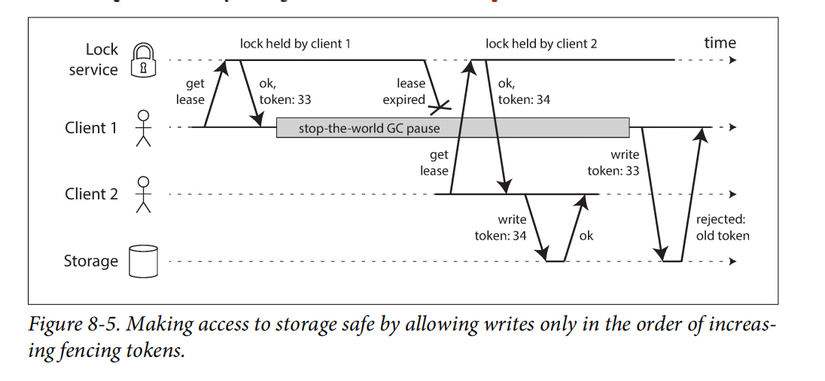
Fencing tokens
Token được lock service cấp tăng dần, trong trường hợp ở trên, do token nhỏ hơn nên lệnh ghi invalid bị chặn lại kịp thời
Byzantine Faults
Vấn đề Byzantine Generals:
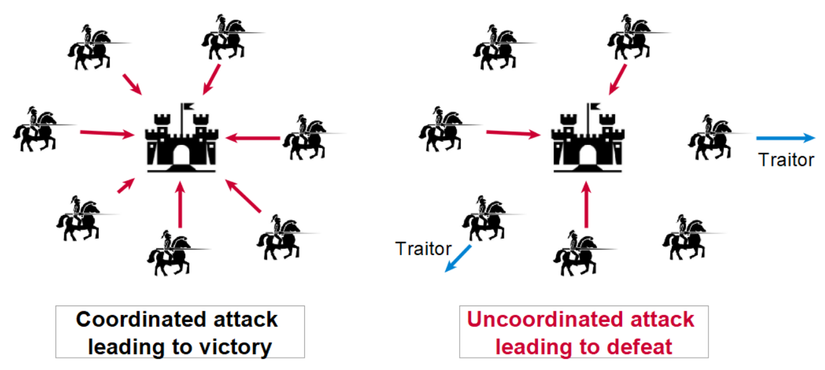 Byzantine Fault đề cập đến loại lỗi trong hệ thống phân tán khi một hoặc nhiều thành phần có thể hành xử không thể đoán trước, thậm chí có thể gửi thông tin sai lệch hoặc xung đột với những gì chúng thực sự làm. Điều này làm cho hệ thống khó đạt được đồng thuận.
Byzantine Fault đề cập đến loại lỗi trong hệ thống phân tán khi một hoặc nhiều thành phần có thể hành xử không thể đoán trước, thậm chí có thể gửi thông tin sai lệch hoặc xung đột với những gì chúng thực sự làm. Điều này làm cho hệ thống khó đạt được đồng thuận.
👉 Đây là một trong những lỗi nghiêm trọng nhất trong distributed systems, vì nó có thể do:
- Phần cứng bị lỗi (trả về kết quả sai lệch)
- Tấn công mạng (một node bị tấn công và gửi dữ liệu giả mạo)
- Lỗi phần mềm (một node thực hiện các thao tác không đúng do bug)
Weak forms of lying
Thêm vài cơ chế để đảm bảo "lying" yếu cũng bõ công sức, những trường hợp invalid message do vấn đề về hardware, bug phần mềm hay config sai. Gói tin mạng có thể bị lỗi do sự cố ở phần cứng, hệ điều hành hoặc router, nên ngoài checksums của TCP/UDP, ứng dụng cũng nên có checksums riêng để kiểm tra dữ liệu. Dữ liệu đầu vào từ người dùng phải được kiểm tra và giới hạn kích thước để tránh lỗi hoặc tấn công chiếm dụng bộ nhớ. NTP client có thể dùng nhiều server thay vì chỉ một, so sánh thời gian giữa các server để phát hiện và loại bỏ server báo thời gian sai.
Dù không đạt mức Byzantine fault tolerance, các biện pháp này vẫn giúp hệ thống đáng tin cậy hơn và giảm rủi ro từ lỗi không mong muốn
System Model và Tính tin cậy
System model, abstraction mô tả những gì 1 giải thuật có thể giả định. Dựa trên giả định về thời gian, có 3 system model phổ biến.
Mô hình đồng bộ (Synchronous model):
- Giả định rằng độ trễ mạng, thời gian dừng tiến trình và sai số đồng hồ đều có giới hạn tối đa.
- Không có nghĩa là đồng hồ phải hoàn toàn đồng bộ hay độ trễ mạng bằng 0, chỉ cần đảm bảo chúng không vượt quá một mức nhất định.
- Không thực tế, vì trong thực tế độ trễ không giới hạn và tiến trình có thể bị pause bất ngờ.
Mô hình bán đồng bộ (Partially synchronous model):
- Hệ thống hoạt động như đồng bộ hầu hết thời gian, nhưng đôi khi có thể vượt quá giới hạn về độ trễ mạng, tiến trình bị pause hoặc sai số đồng hồ.
- Đây là mô hình thực tế nhất, vì thông thường hệ thống hoạt động ổn định, nhưng vẫn có lúc bị gián đoạn bất thường.
- Khi sự cố xảy ra, độ trễ và lỗi thời gian có thể tăng không giới hạn.
Mô hình bất đồng bộ (Asynchronous model):
- Không có bất kỳ giả định nào về thời gian, nghĩa là thuật toán không được phép sử dụng đồng hồ hoặc timeout.
- Rất hạn chế, nhưng một số thuật toán vẫn có thể hoạt động mà không cần đồng hồ.
3 System model phổ biến nhất cho node:
- Crash-top faults: Crash và không bao giờ hồi phục
- Crash-recovery faults: 1 node có thể khôi phục vào 1 thời điểm không xác định, có stable storage được duy trì trong suốt thời gian crash, in memory bị mất đi (Thực tế nhất)
- Byzantine (arbitrary) faults: Node có thể làm bất kỳ điều gì, bao gồm cả đi trick và đánh lừa các node khác.
All rights reserved
