[Papers Notes] MHA vs MQA vs GQA vs MLA: Các cơ chế chiến thuật khác nhau trong quá trình tính toán Attention trong Transformer
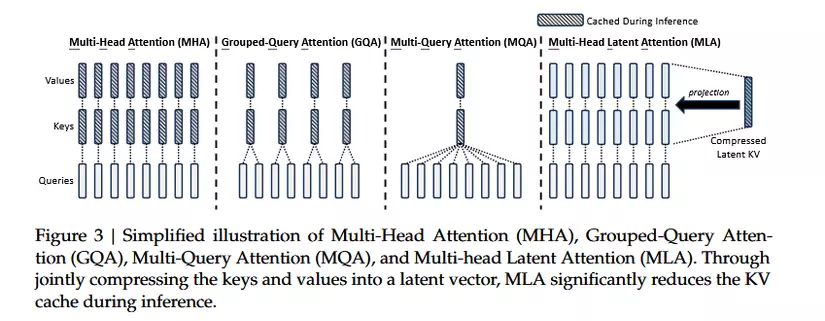
Trong các mô hình Transformer, cơ chế Attention đóng vai trò cốt lõi trong việc xử lý và học tập ngữ cảnh chuỗi dữ liệu. Để tối ưu hóa hiệu suất tính toán và quản lý bộ nhớ, nhiều chiến thuật chú ý đã được phát triển, mỗi cơ chế mang đến các cách tiếp cận khác nhau nhằm cải thiện tốc độ suy luận và hiệu quả xử lý. Trong bài viết này chúng ta sẽ cùng tìm hiểu một số phương án:
- Multi-Head Attention
- Multi-Query Attention
- Grouped-Query Attention
- Multi-Head Latent Attention
Multi-Head Attention (MHA)
Chúng ta đi lại một chút về kiến trúc cơ bản nhất được giới thiệu trong kiến trúc Transformers được giới thiệu vào năm 2017.
Công thức trên khá quen thuộc với chúng ta, đó là cách triển khai ý tưởng Multi-Head Attention (MHA) trong Transformers.
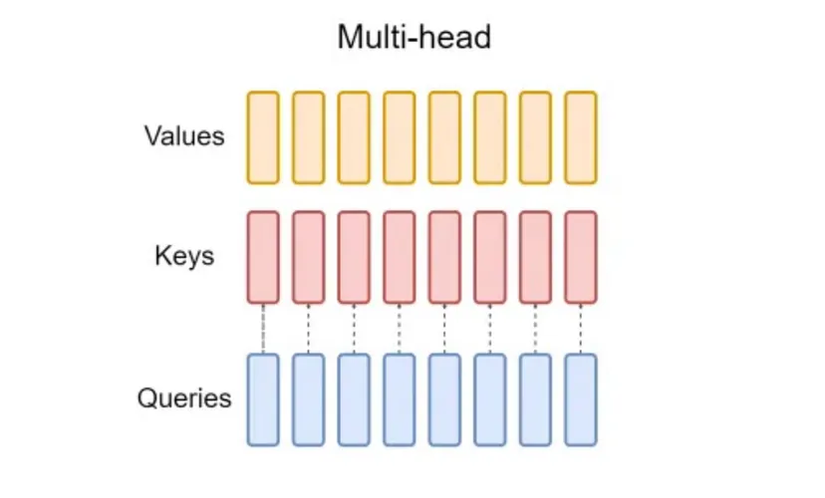
Ý tưởng chính vẫn là với mỗi Queries chúng ta sẽ có cặp Keys và Values riêng.
Nhưng chúng ta dễ nhận thấy điểm yếu của nó là cần khá nhiều tài nguyên để tính toán và xử lý trong quá trình suy luận.
Multi-Query Attention (MQA)
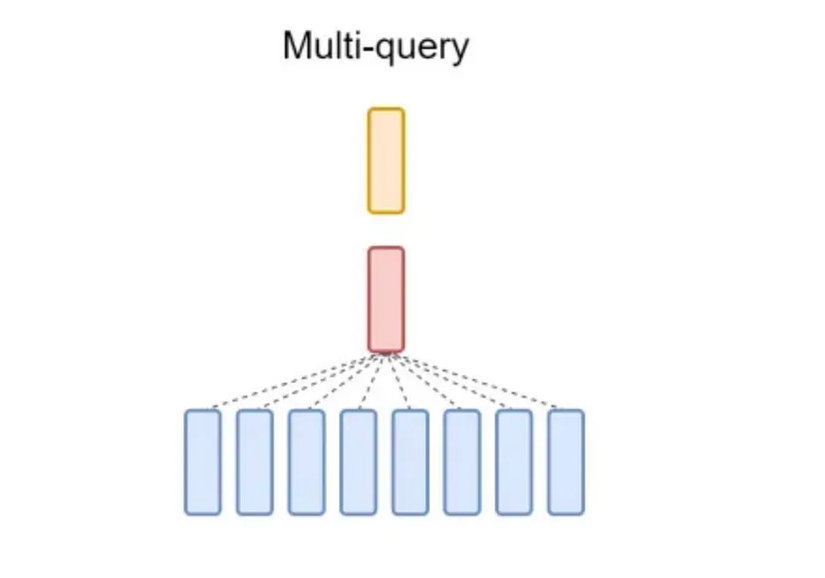
Dựa trên minh họa ở trên chúng ta cũng nắm được ý tưởng chính của MQA. Cách tiếp cận của MQA (Multi-Query Attention) là giữ nguyên số lượng head cho Query và sẽ dùng chung bộ head Key và Values. Với cách tiếp cận trên thì MQA giúp giảm bộ nhớ KV-cache, tăng tốc quá trình suy luận (inference), tiết kiệm tài nguyên tính toán. Trái lại, điều này cũng đem đến sự suy giảm chất lượng và sự không ổn định trong quá trình huấn luyện.
Đi sâu hơn chút về sự xuất hiện của việc bất ổn định trong quá trình huấn luyện. Điều này diễn ra do sự giảm tính đa dạng trong việc diễn Key và Value do sự giảm sút về số lượng của các header Keys và Values, đặc biệt là với dữ liệu phức tạp. Đặc biệt là điều này gây áp lực cho đầu Keys và Values trong quá trình cập nhật gradient.
Nhìn chung lại nó đem đến sự hiệu quả trong quá trình inferences, nhưng sẽ gây nhiều khó khăn hơn trong quá trình training, yêu cầu nhiều kỹ thuật điều chỉnh và tinh chỉnh phức tạp hơn.
Grouped Query Attention (GQA)
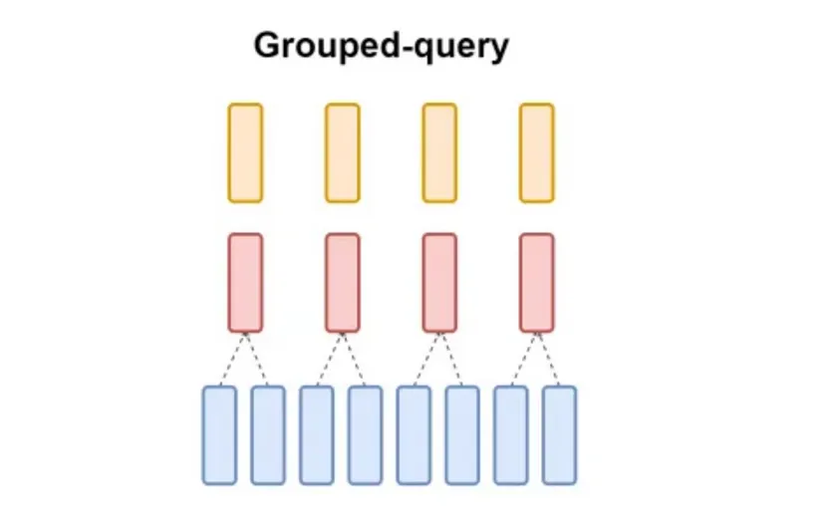
Grouped Query Attention (GQA) là một phương pháp trung gian giữa Multi-Head Attention (MHA) và Multi-Query Attention (MQA). Trong GQA, các head Query (Q) được chia thành các nhóm nhỏ hơn tổng số head chú ý, và mỗi nhóm chia sẻ chung một bộ Key (K) và Value (V) riêng. Điều này giúp GQA duy trì sự cân bằng giữa chất lượng mô hình và hiệu suất: nó giảm bộ nhớ và băng thông cần thiết so với MHA, đồng thời cải thiện chất lượng so với MQA. Khi số nhóm bằng 1, GQA trở thành MQA, và khi số nhóm bằng số head chú ý, nó tương đương với MHA. GQA là một giải pháp linh hoạt, phù hợp cho các mô hình lớn yêu cầu cả tốc độ và độ chính xác cao hơn so với phương án trước.
Multi-Head Latent Attention (MLA)
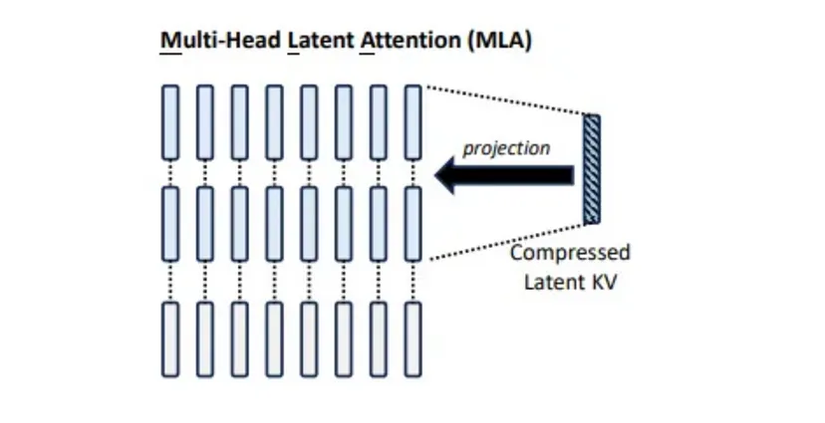
Đến đây thì sẽ ứng dụng với những kỹ thuật mới hơn một chút, tổng quan về mặt ý tưởng thì chúng ta sử dụng Low-Rank Compression vào Keys và Values. Công thức tổng quan ở phía dưới:
Với tổng quan ở trên, MLA sử dụng một ma trận chiếu phân rã hạng thấp (low-rank factorized projection matrix), hoạt động hơi giống với MHA, trong đó thay vì lặp đi lặp lại một đầu duy nhất, ta sẽ nén một vector tiềm ẩn để tạo ra một đầu K và V tương ứng, phù hợp với mỗi đầu Q. Ý tưởng chi tiết hơn như sau:
- Thay thế phép tính QKV bằng cách sử dụng phân rã hạng thấp để chuyển một ma trận có kích thước (in, out) thành hai ma trận có kích thước (in, rank) và (rank, out).
- Dựng lại vector KV tiềm ẩn đã nén cho mỗi đầu để có được đầu K và V đầy đủ tương ứng với mỗi đầu Q.
- Lưu trữ vector KV tiềm ẩn đã nén thay vì lưu trữ mỗi đầu KV, và tính toán các đầu KV trực tiếp từ vector tiềm ẩn.
Đi thêm một chút nữa thì việc sử dụng low-rank factorization thì giúp ma trận nén sử dụng ít tham số hơn và có khả năng biểu diễn mạnh mẽ hơn và có khả năng biểu diễn mạnh mẽ hơn (nhờ việc có hai lớp, đôi khi được phân cách bởi một hàm phi tuyến tính như layernorm hoặc activation). Các ma trận này có thể xấp xỉ hoặc tương đương với một ma trận lớn hơn, vì vậy lý thuyết là bạn có thể nhân các trọng số của các ma trận này lại với nhau để tái tạo một xấp xỉ của ma trận ban đầu.
Điểm yếu của việc làm này là giờ đây chúng ta phải thực hiện hai phép toán mỗi khi sử dụng phương pháp này (tức là chúng ta sẽ tăng gấp đôi số phép nhân ma trận cho mỗi lớp chúng ta nén và giải nén, để đổi lấy việc giảm kích thước ma trận), và sẽ rõ ràng làm giảm sức mạnh biểu diễn của ma trận ban đầu, vì chúng bị giới hạn chỉ có thể có hạng là r hoặc thấp hơn. Bạn có thể coi phân rã hạng thấp như một sự đánh đổi giữa chi phí bộ nhớ và chi phí tính toán – các biến thể của phương pháp này rất phổ biến trong các trường hợp như tinh chỉnh (finetuning) và giảm kích thước kv-cache, vì những thứ này bị giới hạn bởi chi phí bộ nhớ tổng thể thay vì chi phí tính toán hay tốc độ suy luận. Không chỉ thế thì phương án này sẽ đem lại một số vấn đề về độ chính xác do việc sử dụng Low-Rank Factorization tái tạo lại ma trận gần đúng với ma trận gốc.
Ngoài ra, trong paper Deepseekv2, tác giả ở phiên bản đầu tiên có sử dụng RoPE để giải quyết vấn đề liên quan đến thông tin vị trí. Nhưng có một vấn đề nhỏ khi triển khai RoPE trong MLA, ma trận không có tính chất giao hoán mà lại là phương án nhúng trực tiếp trong quá trình tính trong attention. Và đến đây họ đề xuất phương án là decouple RoPE để có thể sử dụng RoPE trong Multi-Head Latent Attention. Ý tưởng chính thì là nhúng RoPE vào trong từng lúc tính toán trở ra. Công thức chi tiết thì nằm ở dưới:
References
All rights reserved
