[Papers Notes] NaViT: Thuật toán Transformer với Tầm nhìn Đa phân giải - Cải thiện khả năng nhìn của Transformer trong xử lý hình ảnh
Transformer, ban đầu được thiết kế cho xử lý ngôn ngữ tự nhiên (NLP), đã nhanh chóng trở thành một kiến trúc quan trọng trong thị giác máy tính. Các mô hình như Vision Transformer (ViT) đã chứng minh hiệu quả vượt trội so với mạng tích chập (CNN) truyền thống bằng cách xử lý hình ảnh thành các patch và áp dụng cơ chế self-attention. Tuy nhiên, Transformer vẫn gặp phải những hạn chế khi xử lý hình ảnh, đặc biệt là khả năng mở rộng với hình ảnh độ phân giải cao và kích thước đa dạng, dẫn đến chi phí tính toán lớn và thiếu linh hoạt.
Để giải quyết những vấn đề này, NaViT (Native Vision Transformer) ra đời như một giải pháp cải tiến. NaViT cho phép xử lý hình ảnh đa phân giải một cách tự nhiên, loại bỏ yêu cầu tiền xử lý phức tạp và giảm thiểu chi phí tính toán. Với khả năng này, NaViT không chỉ cải thiện hiệu suất của Transformer trong thị giác máy tính mà còn mở ra nhiều ứng dụng tiềm năng trong nhận dạng hình ảnh, phân đoạn và phân tích dữ liệu thị giác.
Trong bài viết này, chúng ta sẽ khám phá kiến trúc độc đáo của NaViT, những ưu điểm vượt trội và tiềm năng của NaViT.
1. Đặt vấn đề
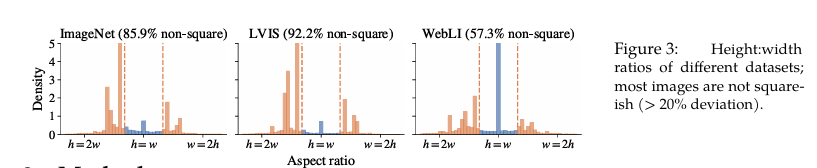
Đi lại một chút về những kỹ thuật trước trong xử lý hình ảnh, thường là sẽ có xu hướng đưa hình ảnh thành dạng cố định (sử dụng resize, padding, ...) từ đó xử lý xuyên suốt quá trình. Thường là sẽ đưa về ảnh có kích thước hình vuông. Nhưng dựa trên thông tin ở bên trên thì rất ít dữ liệu ở dạng hình vuông mà thường sẽ bị biến đổi khá nhiều làm ảnh hưởng đến vấn đề thông tin. Sau đó có sự phát triển việc sử dụng Transformer trong việc xử lý hình ảnh, Vision Transformer, vấn đề của ViT là việc biểu diễn vị trí của các patch ảnh.
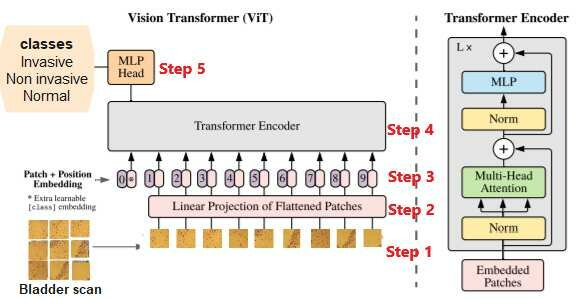
Ở ảnh trên, ta thấy vị trí của các patch ảnh sẽ không bao giờ cố định. Như ảnh trên, vị trí số 3 thì sẽ nằm cạnh số 2 và bên trên số 4, nhưng vấn đề với những size ảnh khác nhau thì vị trí như vậy không còn chính xác nữa. Vậy thông tin về vị trí rất khó được bảo toàn.
Tổng hợp lại thì chúng ta có một số hạn chế sau:
- Xử lý hình ảnh có kích thước cố định:: ViT yêu cầu hình ảnh đầu vào phải được resize về một kích thước cố định (thường là hình vuông) trước khi chia thành các patch. Điều này làm mất thông tin quan trọng từ tỷ lệ khung hình (aspect ratio) gốc, đặc biệt ảnh hưởng đến các tác vụ như hiểu biểu đồ hoặc tài liệu.
- Chi phí tính toán cao:: Khi xử lý hình ảnh độ phân giải cao, số lượng patch tăng lên đáng kể, dẫn đến chi phí tính toán và bộ nhớ lớn. Điều này làm giảm khả năng mở rộng của mô hình.
- Thiếu linh hoạt trong huấn luyện và suy luận: Việc sử dụng kích thước patch cố định và hình ảnh đầu vào cố định khiến mô hình kém linh hoạt trong việc thích ứng với các tác vụ và dữ liệu đa dạng.
- Hạn chế về việc học vị trí của ảnh: Hạn chế về việc học vị trí trong các patch ảnh.
Từ đó ta có một số ý tưởng mà NaViT cải thiện những vấn đề trên.
2. Methods
2.1. Patch n’ Pack: Đóng gói nhiều hình ảnh vào một chuỗi
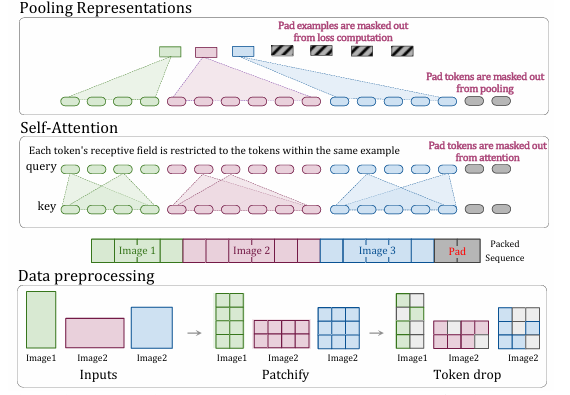
Trong lĩnh vực xử lý ngôn ngữ tự nhiên, để vượt qua giới hạn về độ dài chuỗi cố định, các nhà nghiên cứu sử dụng kỹ thuật là example packing.
- Kết hợp các chuỗi ngắn từ nhiều ví dụ khác nhau thành một chuỗi duy nhất
- Kỹ thuật này giúp tăng hiệu suất huấn luyện bằng cách tận dụng tốt hơn tài nguyên tính toán.
Example Packing
Example Packing là một kỹ thuật được sử dụng trong huấn luyện mô hình, đặc biệt là trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP), để tối ưu hóa việc sử dụng tài nguyên tính toán.
→ Kỹ thuật này tập trung vào việc kết hợp các ví dụ ngắn từ tập dữ liệu thành một chuỗi dài hơn, nhằm tận dụng tối đa dung lượng cố định của batch hoặc độ dài chuỗi đầu vào.
Cách hoạt động của Example Packing:
- Thay vì sử dụng padding, các ví dụ ngắn được ghép nối với nhau thành một chuỗi duy nhất để đạt được độ dài gần với giới hạn tối đa.
- Kỹ thuật này không thay đổi ý nghĩa của dữ liệu gốc, bởi mô hình vẫn có khả năng phân biệt các ví dụ khác nhau bằng cách sử dụng token đặc biệt (ví dụ như <SEP> hoặc <END> để đánh dấu điểm kết thúc của mỗi ví dụ).
Lợi ích:
- Tối ưu hóa bộ nhớ và tính toán: Bằng cách đóng gói nhiều hình ảnh vào một chuỗi, NaViT giảm thiểu chi phí tính toán và tận dụng tối đa tài nguyên phần cứng.
- Linh hoạt trong xử lý: Mô hình có thể xử lý hình ảnh với kích thước và tỷ lệ khung hình đa dạng một cách tự nhiên, phù hợp với nhiều tác vụ thị giác máy tính.
2.2. Masked Self-Attention và Masked Pooling
Masked Self-Attention:
-
Vấn đề: Khi đóng gói nhiều hình ảnh vào một chuỗi, các patch từ các hình ảnh khác nhau có thể tương tác với nhau, dẫn đến nhiễu thông tin.
-
Giải pháp: NaViT sử dụng masked self-attention để ngăn chặn sự tương tác giữa các patch thuộc các hình ảnh khác nhau. Các mask được thêm vào để kiểm soát vùng tiếp nhận (receptive field) của cơ chế self-attention, đảm bảo rằng mỗi hình ảnh chỉ tập trung vào các patch của chính nó.
-
Lợi ích: Duy trì tính toàn vẹn của thông tin trong từng hình ảnh, đồng thời tăng hiệu quả của quá trình học.
Masked Pooling:
- Cách thức hoạt động: Trên lớp encoder, NaViT áp dụng masked pooling để tổng hợp các token trong từng hình ảnh riêng biệt. Kết quả là mỗi hình ảnh được biểu diễn bằng một vector duy nhất.
- Lợi ích: Giúp mô hình dễ dàng xử lý và so sánh các hình ảnh trong chuỗi, đồng thời giảm độ phức tạp tính toán.
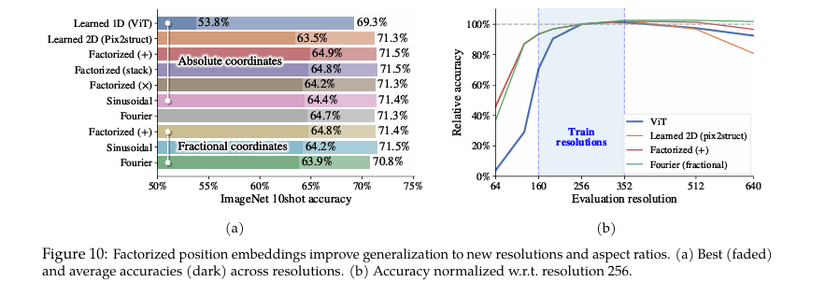
2.3. Factorized & Fractional Positional Embeddings
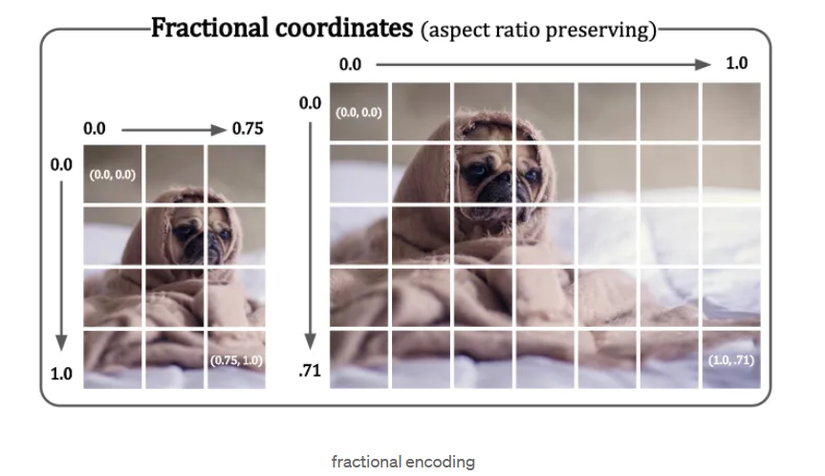
Vấn đề: Các mô hình ViT truyền thống sử dụng positional embeddings cố định, thường dựa trên tọa độ tuyệt đối của các patch. Điều này gây khó khăn khi xử lý hình ảnh với độ phân giải và tỷ lệ khung hình khác nhau.
Giải pháp: NaViT giới thiệu hai loại positional embeddings mới:
Factorized Positional Embeddings:
-
Tách biệt các embedding cho tọa độ x và y , sau đó kết hợp chúng bằng cách cộng hoặc các phương pháp khác.
-
Lợi ích: Cho phép mô hình xử lý hình ảnh với tỷ lệ khung hình đa dạng một cách linh hoạt.
Fractional Positional Embeddings:
-
Sử dụng tọa độ tương đối thay vì tọa độ tuyệt đối. Điều này giúp mô hình dễ dàng ngoại suy cho các độ phân giải chưa từng thấy trong quá trình huấn luyện.
-
Lợi ích: Giảm sự phụ thuộc vào kích thước hình ảnh cụ thể, tăng khả năng tổng quát hóa của mô hình.
2.4. Lấy mẫu độ phân giải ngẫu nhiên
Cách thức hoạt động: Trong quá trình huấn luyện, NaViT áp dụng kỹ thuật lấy mẫu độ phân giải ngẫu nhiên, cho phép mô hình tiếp xúc với nhiều độ phân giải khác nhau.
Lợi ích:
- Giảm chi phí huấn luyện: Bằng cách lấy mẫu ngẫu nhiên, NaViT giảm đáng kể chi phí tính toán mà vẫn đảm bảo hiệu suất cao.
- Tăng tính linh hoạt: Mô hình có thể thích ứng với nhiều tác vụ và dữ liệu đa dạng mà không cần thay đổi kiến trúc.
2.5. Resolution Sampling
NaViT giới thiệu Resolution Sampling, một kỹ thuật cho phép huấn luyện mô hình với độ phân giải linh hoạt, giữ nguyên tỷ lệ khung hình (aspect ratio) gốc của từng hình ảnh. Cụ thể:
Huấn luyện với độ phân giải gốc:
NaViT có thể huấn luyện trực tiếp trên hình ảnh với độ phân giải gốc mà không cần resize. Điều này giúp bảo toàn thông tin chi tiết trong hình ảnh.
Lợi ích: Tận dụng tối đa dữ liệu gốc, đặc biệt hữu ích cho các tác vụ yêu cầu độ chính xác cao.
Lấy mẫu độ phân giải ngẫu nhiên:
Trong quá trình huấn luyện, NaViT có thể lấy mẫu độ phân giải từ một phân phối kích thước hình ảnh khác nhau. Mỗi hình ảnh được resize ngẫu nhiên trong khi vẫn giữ nguyên tỷ lệ khung hình.
Lợi ích:
-
Tăng thông lượng: Hình ảnh nhỏ hơn giúp tăng tốc độ huấn luyện và giảm chi phí tính toán.
-
Tiếp xúc với hình ảnh lớn: Hình ảnh lớn hơn giúp mô hình học được các đặc trưng chi tiết, cải thiện hiệu suất khi đánh giá trên hình ảnh độ phân giải cao.
Linh hoạt trong tiền huấn luyện và fine-tuning:
NaViT cho phép huấn luyện hỗn hợp (mixed-resolution training), kết hợp cả hình ảnh nhỏ và lớn trong cùng một batch. Điều này giúp mô hình tiếp xúc với nhiều mức độ chi tiết khác nhau ngay từ giai đoạn tiền huấn luyện.
Lợi ích: Giảm nhu cầu fine-tuning trên hình ảnh độ phân giải cao, tiết kiệm thời gian và tài nguyên.
3. Kết quả
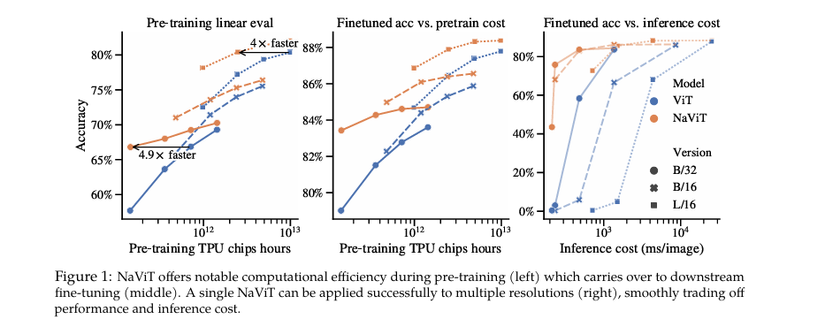 Một số điểm cải thiện trong kết quả với NaViT:
Một số điểm cải thiện trong kết quả với NaViT:
- NaViT đạt hiệu suất tương đương với các mô hình ViT hàng đầu nhưng chỉ sử dụng 1/4 chi phí tính toán.
- Trong quá trình huấn luyện, NaViT có thể xử lý nhiều hơn 5 lần số lượng hình ảnh so với ViT truyền thống.
- Khả năng xử lý đa phân giải và tỷ lệ khung hình linh hoạt mở ra nhiều hướng nghiên cứu mới, như lấy mẫu độ phân giải bảo toàn tỷ lệ khung hình và tỷ lệ bỏ token thay đổi.
Kết Luận
Với những cải tiến này, NaViT không chỉ vượt qua các hạn chế của ViT mà còn mở ra một hướng đi mới đầy hứa hẹn cho các hệ thống thị giác máy tính, giúp chúng trở nên linh hoạt, hiệu quả và dễ dàng thích ứng hơn.
Một phần implement nho nhỏ của mình: https://github.com/DngBack/NaViT_Implematation
References
All rights reserved
