🔄 RNN – Giải Mã Chi Tiết: Công Nghệ Mạng Nơ-ron Hồi Quy Xử Lý Chuỗi Dữ Liệu!!!
Ở bài trước, chúng ta đã cùng nhau khám phá chi tiết về Cross Entropy, một trong những hàm mất mát quan trọng bậc nhất trong Deep Learning (bạn có thể xem lại bài viết: 🔍 Khám Phá Cross Entropy: Bí Quyết Giải Mã Hàm Mất Mát Trong Deep Learning 🚀 ).
Hôm nay chúng ta sẽ cùng nhau khám phá về một kiến trúc cực kỳ thú vị và mạnh mẽ khác Recurrent Neural Networks (RNNs). Và đừng quên, bài viết tiếp theo sẽ giới thiệu chi tiết về Long Short Term Memory (LSTM), Clearly Explained!!! một cải tiến vượt bậc giúp khắc phục những hạn chế của RNNs. Cùng bắt đầu nhé! 🎉
Kiến Trúc của RNNs 🏗️
RNN được thiết kế để xử lý dữ liệu tuần tự (sequential data) như văn bản, chuỗi thời gian, hay giọng nói bằng cách duy trì "bộ nhớ" các đầu vào trước đó thông qua trạng thái ẩn (hidden state). Sau đây là cách chúng hoạt động:
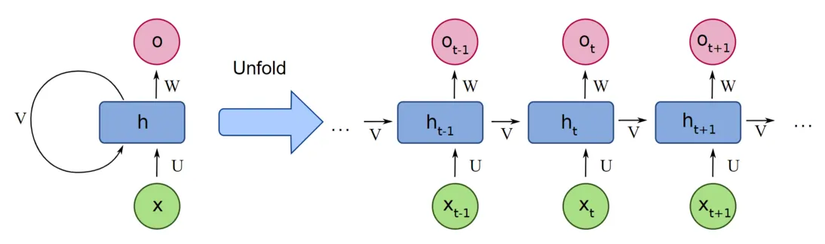
- Sequential Processing (Xử Lý Theo Chuỗi):
- Không giống như feedforward networks (xử lý đầu vào độc lập), RNN xử lý đầu vào theo từng bước theo trình tự. Ví dụ, khi xử lý câu "I love RNNs", mỗi từ được xử lý theo thứ tự từ đầu đến cuối.
- Tại mỗi bước thời gian , RNN nhận vào:
- Input (Ví dụ: một từ trong câu hoặc giá cổ phiếu vào ngày ).
- Previous Hidden State (một vector tóm tắt thông tin quá khứ).
- Loop Mechanism (Cơ Chế Lặp) 🔄:
- Tại mỗi bước, hidden state được cập nhật, đóng vai trò như một “context vector” tổng hợp thông tin của quá khứ.
- Nhờ vào cơ chế lặp, RNN có thể xử lý các chuỗi có độ dài khác nhau, từ những câu ngắn đến những đoạn văn dài.
- Output Generation:
- RNN có thể tạo ra đầu ra cho từng bước, chẳng hạn như dự đoán từ tiếp theo trong câu.
Biểu Diễn Hình Ảnh 📊
Để hình dung, hãy xem cách RNN hoạt động qua từng bước thời gian:
Time Step 1: [x₁] → [RNN Cell] → [h₁] → (Optional: y₁)
Time Step 2: [x₂ + h₁] → [RNN Cell] → [h₂] → (Optional: y₂)
...
Time Step T: [x_T + h_{T-1}] → [RNN Cell] → [h_T] → (Optional: y_T)
Lưu ý: Cùng một RNN Cell được sử dụng cho tất cả các bước, giúp giảm số lượng tham số và tăng khả năng tổng quát hoá.
Công Thức Toán Học của RNNs 🔢
-
Cập Nhật Hidden State:
- : Ma trận trọng số cho đầu vào
- : Ma trận trọng số cho hidden state trước đó
- : Hệ số bias.
- Activation Function: Thường sử dụng tanh hoặc ReLU để đưa giá trị vào khoảng phù hợp và tạo phi tuyến.
Trạng thái ẩn là biểu diễn nén của đầu vào hiện tại và thông tin trước đó .
-
Tính Toán Đầu Ra:
- : Ma trận trọng số cho đầu ra.
- : Hệ số bias cho đầu ra.
📌 Chi tiết quan trọng cần nhớ
-
Parameter Sharing (Chia sẻ tham số):
- Cùng một tập trọng số được tái sử dụng trên tất cả các bước thời gian.
- Điều này làm giảm đáng kể số lượng tham số và cho phép RNN tổng quát hóa trên các chuỗi có độ dài bất kỳ.
-
Unrolled RNN (RNN mở rộng):
- Khi được trực quan hóa theo thời gian, một RNN có thể được "mở rộng" thành một chuỗi các cell lặp lại (tương tự như các lớp trong mạng feedforward).
- Việc mở rộng này cho thấy cách thông tin được truyền từ to .
-
Activation Function:
- Hàm thường được sử dụng vì nó nén giá trị trong khoảng , giúp ngăn hidden states from tăng quá lớn.
- Example:
Ví Dụ Minh Họa: Xử Lý Một Câu Văn 📝
Giả sử chúng ta đưa câu "I love RNNs" vào RNN:
- Time Step 1:
- Input (được mã hóa thành vector).
- Tính (với khởi tạo bằng 0).
- Time Step 2:
- Input .
- Tính .
- Time Step 3:
- Input .
- Tính .
- Final Output:
-
Nếu mục tiêu là sentiment analysis, ta có thể sử dụng để dự đoán cảm xúc thông qua:
-
Những Thách Thức Khi Xử Lý Chuỗi Dài 🚧
Mặc dù RNNs rất mạnh mẽ, nhưng chúng cũng gặp một số vấn đề khi xử lý các chuỗi dài:
- Vanishing Gradients: Trong quá trình huấn luyện (backpropagation through time – BPTT), gradient có thể giảm dần theo cấp số nhân, gây khó khăn cho việc học các mối liên hệ xa trong chuỗi.
- Exploding Gradients: Ngược lại, gradient có thể tăng quá lớn, dẫn đến sự mất ổn định trong quá trình huấn luyện.
Giải pháp:
- Sử dụng các biến thể như LSTM hoặc GRU với cơ chế cửa (gating mechanism) để kiểm soát luồng thông tin.
- Áp dụng kỹ thuật gradient clipping để hạn chế sự bùng nổ của gradients.
Kết Luận & Lời Nhắn Nhủ 🎯
Hy vọng rằng bài viết "Recurrent Neural Networks (RNNs), Clearly Explained!!!" đã giúp bạn hiểu rõ hơn về cách thức hoạt động cũng như các đặc điểm nổi bật của RNNs.
Đừng bỏ lỡ bài viết sắp tới "Long Short Term Memory (LSTM), Clearly Explained!!!", nơi chúng ta sẽ đi sâu vào cách mà LSTM giải quyết các vấn đề của RNN truyền thống và cải thiện khả năng ghi nhớ của mô hình.
Cảm ơn bạn đã dành thời gian theo dõi và học hỏi cùng tôi! Hãy like, share và để lại comment nếu bạn có bất kỳ thắc mắc hoặc góp ý nào nhé! 😊👍
All rights reserved
