Seq2Seq Models & Encoder-Decoder: Dạy Máy Tính Dịch Thuật và Hơn Thế Nữa! 🌐
Bạn đã bao giờ trầm trồ trước khả năng dịch thuật gần như tức thời của Google Translate? Hay tự hỏi làm thế nào một con bot có thể tóm tắt một bài báo dài chỉ trong vài câu? Hoặc cách trợ lý ảo tạo ra câu trả lời hợp lý cho câu hỏi của bạn? Đằng sau nhiều kỳ công này là một kiến trúc mạng nơ-ron mạnh mẽ có tên là Sequence-to-Sequence (Seq2Seq), thường được triển khai dưới dạng Encoder-Decoder.
1. Giai Điệu Mở Đầu: Từ "Imagine" Đến "Imaginez" 🎵
Hãy quay lại với bài hát "Imagine". Nếu Word Embedding giúp máy tính hiểu "ý nghĩa" của từ "imagine", "peace", "world", thì làm thế nào để dạy nó dịch cả câu "Imagine all the people living life in peace" sang tiếng Pháp thành "Imaginez tous les gens vivant leur vie en paix"?
Đây là bài toán sequence-to-sequence: đầu vào là một chuỗi (câu tiếng Anh) và đầu ra là một chuỗi khác (câu tiếng Pháp). Độ dài hai chuỗi này có thể hoàn toàn khác nhau! Các mô hình trước đây (như RNN cơ bản) thường gặp khó khăn với loại tác vụ này vì chúng được thiết kế để ánh xạ một-một hoặc nhiều-một giữa đầu vào và đầu ra có cấu trúc cố định.
Kiến trúc Encoder-Decoder ra đời như một giải pháp thanh lịch. Hãy tưởng tượng một người phiên dịch:
- Encoder (Người Nghe): Người đó lắng nghe toàn bộ câu nói bằng ngôn ngữ gốc (ví dụ: tiếng Anh), cố gắng hiểu và ghi nhớ ý nghĩa cốt lõi của nó.
- Decoder (Người Nói): Dựa trên "ý nghĩa cốt lõi" đã nắm bắt được, người đó bắt đầu xây dựng và nói ra câu tương đương bằng ngôn ngữ đích (ví dụ: tiếng Pháp), từng từ một.
Kiến trúc Encoder-Decoder trong mạng nơ-ron hoạt động theo nguyên tắc tương tự.
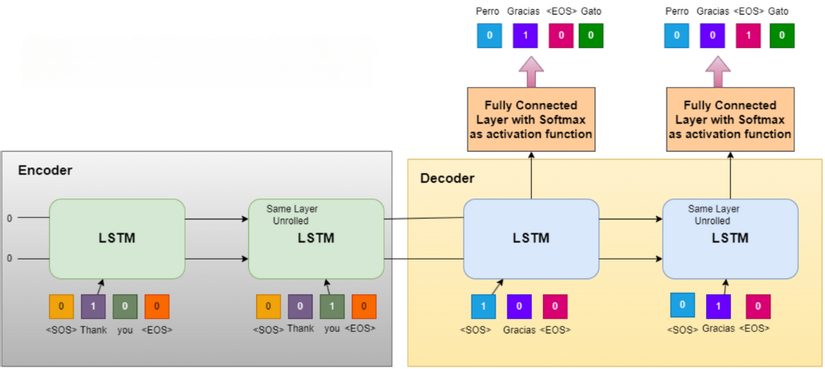
2. Xây Dựng Bộ Mã Hóa (Encoder): "Lắng Nghe" và Nén Thông Tin 🧠
Nhiệm vụ của Encoder là đọc chuỗi đầu vào (ví dụ: câu tiếng Anh "I love you") và nén toàn bộ thông tin của nó vào một vector ngữ cảnh (context vector) có kích thước cố định. Vector này đôi khi còn được gọi là "thought vector" (vector tư tưởng) - nó được kỳ vọng sẽ nắm bắt được "ý nghĩa" hay "bản chất" của chuỗi đầu vào.
- Kiến trúc: Encoder thường là một Mạng Nơ-ron Hồi quy (Recurrent Neural Network - RNN), hoặc các biến thể mạnh mẽ hơn của nó như LSTM (Long Short-Term Memory) hoặc GRU (Gated Recurrent Unit). Lý do sử dụng RNN là vì chúng có khả năng xử lý dữ liệu tuần tự, ghi nhớ thông tin từ các bước thời gian trước đó.
- Hoạt động:
- Encoder nhận đầu vào là các vector embedding của từng từ trong chuỗi đầu vào (ví dụ:
embedding('I'),embedding('love'),embedding('you')). - Nó xử lý từng từ một theo tuần tự. Tại mỗi bước, RNN cập nhật trạng thái ẩn (hidden state) của nó dựa trên từ đầu vào hiện tại và trạng thái ẩn của bước trước đó.
- Sau khi xử lý từ cuối cùng trong chuỗi đầu vào ("you"), trạng thái ẩn cuối cùng của Encoder được coi là vector ngữ cảnh (context vector). Vector này là bản tóm tắt, là "ý nghĩa" đã được mã hóa của toàn bộ câu "I love you".
- Encoder nhận đầu vào là các vector embedding của từng từ trong chuỗi đầu vào (ví dụ:
3. Xây Dựng Bộ Giải Mã (Decoder): "Nói" Ra Từ Ngữ Cảnh 🗣️
Nhiệm vụ của Decoder là lấy vector ngữ cảnh từ Encoder và tạo ra chuỗi đầu ra (ví dụ: câu tiếng Pháp "Je t'aime"), từng từ một.
- Kiến trúc: Decoder cũng thường là một RNN (LSTM/GRU), hoạt động như một mô hình ngôn ngữ có điều kiện (conditional language model) - nó tạo ra từ tiếp theo dựa trên những từ đã tạo ra trước đó và vector ngữ cảnh.
- Hoạt động:
- Khởi tạo: Trạng thái ẩn ban đầu của Decoder được khởi tạo bằng chính vector ngữ cảnh mà Encoder tạo ra. Đây là cách thông tin từ chuỗi đầu vào được "truyền" sang Decoder.
- Bước đầu tiên: Decoder nhận đầu vào là một token đặc biệt báo hiệu bắt đầu chuỗi (ví dụ:
<SOS>- Start Of Sequence) và trạng thái ẩn ban đầu (vector ngữ cảnh). Nó dự đoán từ đầu tiên của chuỗi đầu ra (ví dụ: "Je"). - Các bước tiếp theo (Auto-regressive):
- Từ vừa được dự đoán ở bước trước ("Je") sẽ trở thành đầu vào cho bước hiện tại.
- Decoder sử dụng từ đầu vào này và trạng thái ẩn trước đó của nó để cập nhật trạng thái ẩn mới và dự đoán từ tiếp theo ("t'").
- Quá trình này lặp lại: từ được dự đoán ở bước
tsẽ là đầu vào cho bướct+1.
- Kết thúc: Quá trình tạo chuỗi dừng lại khi Decoder dự đoán ra một token đặc biệt báo hiệu kết thúc chuỗi (ví dụ:
<EOS>- End Of Sequence) hoặc khi đạt đến độ dài tối đa cho phép.
Điểm kết nối then chốt: Chính vector ngữ cảnh là cầu nối duy nhất mang thông tin từ Encoder sang Decoder trong kiến trúc cơ bản này.
4. Huấn Luyện Mô Hình Encoder-Decoder: Học Cách Ánh Xạ Chuỗi 🧑🏫
Việc huấn luyện một mô hình Seq2Seq Encoder-Decoder đòi hỏi một tập dữ liệu lớn gồm các cặp chuỗi đầu vào - đầu ra song song (ví dụ: cặp câu tiếng Anh - tiếng Pháp).
- Quá trình (Forward Pass):
- Đưa chuỗi đầu vào (tiếng Anh) vào Encoder để tạo ra vector ngữ cảnh.
- Sử dụng vector ngữ cảnh để khởi tạo Decoder.
- Decoder tạo ra chuỗi đầu ra (tiếng Pháp) từng bước một.
- Tính toán Lỗi (Loss Calculation):
- Tại mỗi bước của Decoder, chúng ta so sánh từ mà nó dự đoán với từ thực tế trong chuỗi đầu ra mục tiêu (từ trong câu tiếng Pháp chuẩn).
- Hàm mất mát (thường là Cross-Entropy) được tính toán cho mỗi bước dự đoán.
- Tổng lỗi trên toàn bộ chuỗi đầu ra được tính toán (thường là trung bình lỗi của các bước).
- Lan truyền ngược (Backpropagation):
- Lỗi được lan truyền ngược qua cả Decoder và Encoder (thông qua vector ngữ cảnh) để cập nhật trọng số của cả hai mạng. Quá trình này thường được gọi là Backpropagation Through Time (BPTT) vì nó diễn ra qua các bước thời gian của RNN.
- Teacher Forcing:
- Trong quá trình huấn luyện, thay vì sử dụng từ dự đoán ở bước
tlàm đầu vào cho bướct+1của Decoder, người ta thường sử dụng từ thực tế (ground truth) trong chuỗi mục tiêu. Kỹ thuật này gọi là Teacher Forcing. - Tại sao? Nó giúp ổn định quá trình huấn luyện và hội tụ nhanh hơn, vì Decoder luôn nhận được đầu vào chính xác ở mỗi bước, tránh việc lỗi bị lan truyền và khuếch đại nếu nó dự đoán sai ở những bước đầu. Tuy nhiên, điều này cũng tạo ra sự khác biệt giữa lúc huấn luyện và lúc dự đoán (inference), khi mô hình phải tự dựa vào các dự đoán trước đó của chính nó.
- Trong quá trình huấn luyện, thay vì sử dụng từ dự đoán ở bước
5. Mô Hình Cơ Bản vs. Thực Tế: Nút Thắt Cổ Chai, Attention và Sự Trỗi Dậy Của Transformers 🚀
Mô hình Encoder-Decoder cơ bản sử dụng RNN/LSTM (như trong các bài báo tiên phong của Sutskever et al., 2014 và Cho et al., 2014) là một bước đột phá. Tuy nhiên, như đã đề cập, nó đối mặt với thách thức lớn:
- Nút thắt cổ chai (Bottleneck): Việc ép toàn bộ thông tin của chuỗi đầu vào vào một vector ngữ cảnh có kích thước cố định là một hạn chế nghiêm trọng, đặc biệt với các chuỗi dài. Giống như cố gắng tóm tắt cả một cuốn tiểu thuyết chỉ bằng một câu duy nhất, rất nhiều chi tiết quan trọng có thể bị mất mát.
Để phá vỡ "nút thắt" này, một ý tưởng mang tính cách mạng đã ra đời: Cơ chế Chú ý (Attention Mechanism) (Bahdanau et al., 2014).
- Ý tưởng của Attention: Thay vì chỉ dựa vào vector ngữ cảnh cuối cùng, Attention cho phép Decoder, tại mỗi bước tạo ra từ mới, có thể "nhìn lại" và tập trung (attend) vào các phần khác nhau và liên quan nhất của chuỗi đầu vào (thông qua các trạng thái ẩn của Encoder ở tất cả các bước). Giống như một người dịch thuật thỉnh thoảng liếc lại các phần khác nhau của câu gốc khi đang dịch từng từ.
- Lợi ích: Điều này cho phép mô hình xử lý hiệu quả hơn các chuỗi dài và nắm bắt tốt hơn các mối liên kết phức tạp giữa từ đầu vào và từ đầu ra tương ứng. Ví dụ, khi dịch một từ tiếng Pháp, mô hình có thể "chú ý" nhiều hơn đến từ tiếng Anh tương ứng trong câu gốc.
Cơ chế Attention không chỉ cải thiện đáng kể hiệu suất của các mô hình Seq2Seq dựa trên RNN mà còn đặt nền móng quan trọng cho sự ra đời của kiến trúc Transformer (Vaswani et al., 2017 - bài báo "Attention Is All You Need").
- Transformers: Kiến trúc này loại bỏ hoàn toàn RNN/LSTM và chỉ dựa vào cơ chế tự chú ý (self-attention) và chú ý chéo (cross-attention) để nắm bắt các phụ thuộc trong chuỗi đầu vào và giữa chuỗi đầu vào-đầu ra. Nhờ khả năng xử lý song song mạnh mẽ và hiệu quả trong việc mô hình hóa các phụ thuộc xa, Transformers đã nhanh chóng trở thành kiến trúc thống trị trong hầu hết các lĩnh vực của NLP hiện đại, từ dịch máy, tóm tắt văn bản đến các mô hình ngôn ngữ lớn (LLMs) như GPT hay BERT.
Như vậy, từ Encoder-Decoder RNN cơ bản, chúng ta đã chứng kiến sự tiến hóa mạnh mẽ với Attention và sau đó là sự thống trị của Transformers.
Kết Luận: Nền Tảng Vững Chắc và Tương Lai Rộng Mở
Kiến trúc Encoder-Decoder sử dụng RNN/LSTM/GRU là một cột mốc quan trọng, một ý tưởng nền tảng thanh lịch đã mở ra kỷ nguyên mới cho việc giải quyết các bài toán Sequence-to-Sequence trong NLP. Nó cung cấp một khung làm việc tổng quát, dễ hiểu để máy tính có thể "đọc" một chuỗi và "viết" ra một chuỗi khác.
Mặc dù phiên bản cơ bản có hạn chế về "nút thắt cổ chai", nó đã đặt nền móng vững chắc cho sự phát triển của các kiến trúc phức tạp và hiệu quả hơn. Đầu tiên là sự bổ sung Cơ chế Chú ý (Attention Mechanism), giúp khắc phục hạn chế của vector ngữ cảnh cố định và cải thiện đáng kể hiệu suất. Và tiếp sau đó là sự trỗi dậy của kiến trúc Transformer, vốn dựa trên Attention và đã trở thành lựa chọn hàng đầu cho hầu hết các tác vụ NLP hiện đại, thay thế phần lớn các mô hình dựa trên RNN trong nhiều ứng dụng tiên tiến.
Tuy nhiên, việc hiểu rõ cách Encoder mã hóa thông tin đầu vào và cách Decoder tuần tự tạo ra chuỗi đầu ra, cùng với vai trò của vector ngữ cảnh, vẫn là kiến thức cốt lõi. Nó không chỉ giúp chúng ta hiểu các mô hình Seq2Seq đời đầu mà còn cung cấp nền tảng để tiếp cận và đánh giá các kiến trúc phức tạp hơn như Transformers.
Hành trình khám phá thế giới AI và Xử lý ngôn ngữ tự nhiên (NLP) luôn tràn đầy điều bất ngờ và thú vị. Mỗi bước tiến là một lần mở rộng giới hạn hiểu biết, mỗi khám phá là một cơ hội để nhìn thế giới theo một cách hoàn toàn mới.
Nếu bạn thấy hứng thú với những chủ đề như NLP, Deep Learning hay các ứng dụng thực tiễn của AI, đừng quên theo dõi mình để cùng nhau tiếp tục hành trình này. Mình sẽ còn chia sẻ nhiều góc nhìn sâu sắc, ví dụ trực quan và các ứng dụng thực tế khác trong thời gian tới.
Cảm ơn bạn đã đồng hành cùng bài viết này – hẹn gặp lại trong những chặng tiếp theo trên con đường khám phá AI và NLP!
All rights reserved
