Setup Boilerplate cho dự án NestJS - Phần 13: Tìm hiểu về Elasticsearch và hệ thống Cluster 🔍️🔎?
Đây là bài viết nằm trong Series NestJS thực chiến, các bạn có thể xem toàn bộ bài viết ở link: https://viblo.asia/s/nestjs-thuc-chien-MkNLr3kaVgA

🌸🌼🐍 Xin chào mọi người 🫡, lâu rồi mới có thời gian ngồi lại chia sẻ và thảo luận với mọi người, năm vừa rồi mình bận quá 🫥. Chúc mọi người năm mới vui vẻ 🐍🌼🌸
Đặt vấn đề 📜
Chúng ta cùng đi thẳng vào vấn đề nối tiếp với bài viết trước bằng câu hỏi sau:
Elasticsearch là gì? Tại sao phải dùng Elasticsearch trong khi các database khác đã có hỗ trợ Full Text Search và chi phí để khởi chạy Elasticsearch cũng tiêu tốn không ít tài nguyên?
Đó một trong nhưng câu hỏi mà ban đầu mình nghĩ tới lúc xưa khi nghe sếp yêu cầu tích hợp Elasticsearch vào hệ thống. Chắc các bạn cũng còn nhớ ở bài viết trước về Full Text Search: Setup Boilerplate cho dự án NestJS - Phần 12: Full Text Search với MongoDB 📖 chúng ta đã biết được với các database hiện đại ngày nay thì việc tìm kiếm hiệu quả là điều chúng ta có thể đạt được.
Câu trả lời ngắn gọn nhất là: nhanh, dễ tích hợp và sử dụng, dễ scale theo chiều ngang và khả năng chịu lỗi tốt 💪.
Sau quá trình nghiên cứu và làm việc mình rút ra một số lợi ích sau ❇️:
- 1️⃣ Elasticsearch đơn giản là 1 search engine và có hỗ trợ RESTful API: giúp chúng ta dễ dàng tích hợp vào source code và linh hoạt hơn trong việc kiểm soát dữ liệu thay vì để toàn bộ cho database.
- 2️⃣ Elasticsearch có hỗ trợ kiến trúc multiple node: tự cân bằng multi-node clusters giúp khả năng scale trở nên dễ dàng. Mỗi khi chúng ta thêm 1 Node mới thì hệ thống sẽ tự lo việc kết nối mà không cần chúng ta phải thao tác gì thêm. Tương tự khi 1 Node bị xoá thì hệ thống ngay lập tức tự cân bằng lại.
- 3️⃣ Thời gian tìm kiếm giảm📉 nếu số Node tăng📈: nói cho dễ hiểu thì data sẽ chia đều cho các Node, do đó khi tìm kiếm tất cả các Node (chứa dữ liệu liên quan) sẽ tham gia vì thế giảm được thời gian tìm kiếm hơn nếu có nhiều node so với dồn lại 1 nơi như ở database. Tất nhiên phải đánh đổi việc nhiều Node thì sẽ tốn nhiều tài nguyên.
- 4️⃣ Tính chất High Availability cũng là thế mạnh của Elasticsearch với các Replica node. Khi có 1 node chết, ngay lập tức Cluster sẽ tái cấu trúc các Shard lại để đảm bảo toàn vẹn dữ liệu và đề phòng trước cho trường hợp Node tiếp theo có vấn đề.
- 5️⃣ Elasticsearch không chỉ về tìm kiếm mà còn hỗ trợ thống kê và phân tích dữ liệu rất hiệu quả: đặc biệt khi kết hợp với Kibana để thống kê dữ liệu. Ví dụ xem sản phẩm nào được quan tâm nhiều, dữ liệu thanh toán hoặc order của user. Chúng ta sẽ đi chi tiết về nội dung này ở bài viết sau.
- 6️⃣ Elasticsearch sử dụng Apache Lucene (AL) behind the scene: AL hỗ trợ FTS nên giúp trả về kết quả nhanh, các dữ liệu liên quan (relevant) tới từ khóa. Ngoài FTS ra thì AL còn hỗ trợ thêm nhiều công nghệ khác nữa, có cơ hội chúng ta sẽ tìm hiểu ở bài viết khác.
- 7️⃣ Đơn giản hơn trong việc index data: nếu đem so sánh với NoSQL chúng ta cũng thấy điểm tương đồng là đều lưu trữ dữ liệu dưới dạng document, tuy nhiên NoSQL bắt buộc chúng ta phải suy nghĩ về việc chọn các field như thế nào để index hiệu quả và phải query ra sao để tận dụng được các index đó. Với Elasticsearch thì tất cả các fields đều được index nên chúng ta có thể bỏ qua được những mối lo ngại đó.
- ...Còn rất nhiều lợi ích khác mà mình chưa tận dụng được hết, bạn nào biết thêm có thể bổ sung ở comment để chúng ta cùng hiểu hơn nhé 😉
⚠️ Đúng như các bạn vừa nghĩ tới, việc Elasticsearch index tất các các field chúng ta cung cấp cũng có thể coi là tác hại nếu chúng ta không quản lý hiệu quả
Ở bài viết này mình sẽ tập trung vào kiến trúc và cách Elasticsearch lưu trữ cũng như tìm kiếm dữ liệu (behind the scene) nên sẽ bỏ qua phần khái niệm và quá trình hình thành của Elasticsearch để tránh làm mất thời gian của mọi người. Bạn nào có hứng thú tìm hiểu thì có thể đọc bài viết của bạn Thanh Bình, mình thấy rất hay và chi tiết 👍️ https://viblo.asia/p/elasticsearch-zero-to-hero-1-elasticsearch-la-gi-cai-dat-the-nao-GyZJZxgbVjm. Bên cạnh đó chúng ta cũng sẽ thực hành vọc vạch một tí để xem cách Elasticsearch tìm kiếm dữ liệu từng bước một để có thể hiểu 1 cách sâu sắc nhất có thể. Chúng ta cùng bắt đầu nào 😎!
Kiến trúc Elasticsearch có gì?
Hình bên dưới là kiến trúc tổng thể của 1 Cluster mà Elasticsearch quản lý:
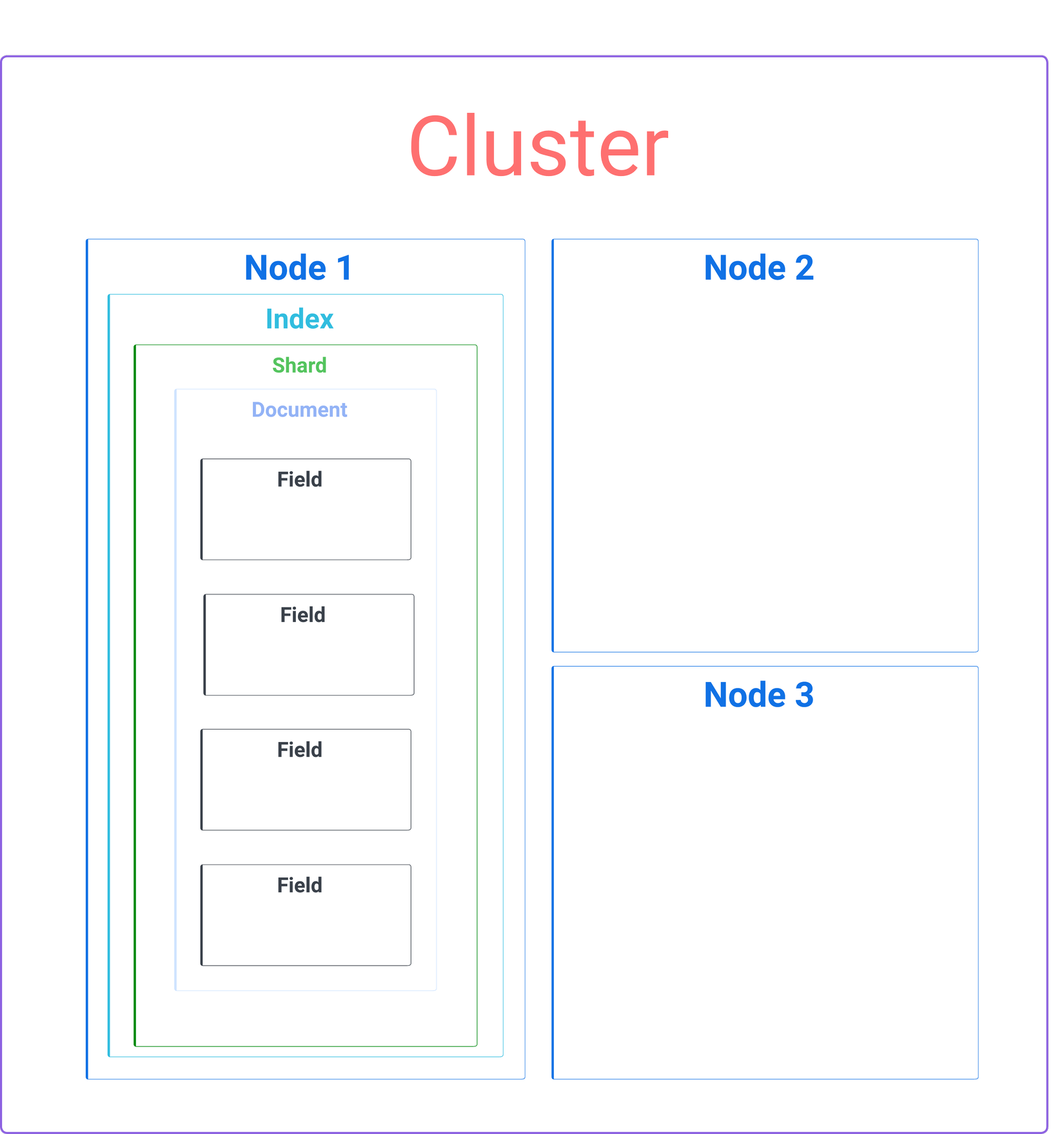
Để dễ hình dung chúng ta sẽ mapping nó với RDMBS và NoSQL thông qua table bên dưới:
| Elasticsearch Concept 🔎 | RDBMS Equivalent 🗄️ | NoSQL Equivalent 📖 |
|---|---|---|
| Cluster | Database instance | Database cluster |
| Index | Table / Schema | Collection |
| Shard | Table partition / shard | Shard / Partition |
| Document | Row | Document |
| Field | Column | Field |
Chúng ta sẽ cùng lần lượt tìm hiểu các thành phần trên:
1. Cluster
Cluster trong Elasticsearch là tập hợp các Node có cùng thuộc tính cluster.name. Khi chúng ta khởi chạy 1 instance của Elasticsearch thì 1 Node sẽ được tạo ra, do đó trên 1 máy chúng ta có thể cài đặt cùng lúc nhiều Node để mô phỏng Cluster.
⚠️ Lưu ý: chỉ nên dùng để dev và test thôi chứ không nên dùng ở môi trường Production vì lỡ máy đó có vấn đề thì các Node sẽ chết hết dẫn đến mất dữ liệu
Các Node bên trong Cluster sẽ cùng chia sẻ dữ liệu và khối lượng công việc. Nếu chúng ta chỉ start một instance của Elasticsearch thì Cluster sẽ có cấu trúc như bên dưới:

Nguồn: elastic.co
Khi 1 Node được thêm vào hoặc xoá khỏi Cluster thì Cluster tự động tái tổ chức lại để phân phối đồng đều dữ liệu trên các Node có sẵn bên trong nó. Hình dưới biểu diễn sử thay đổi khi chúng ta thêm 1 Node vào Cluster:
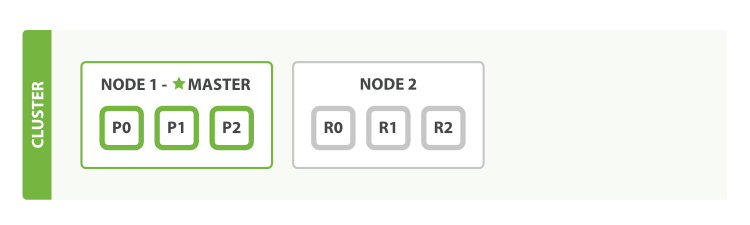
Nguồn: elastic.co
Giải thích:
- P là Primary shards, hình 1 chúng ta có P0, P1, P2 tương ứng 3 Shards lưu trữ dữ liệu.
- R là Replica shards, hình 2 chúng ta có R0, R1, R2 tương ứng 3 Shards dữ liệu copy của P0, P1, P2. Chúng ta sẽ nói rõ hơn ở phần Shards.
Chỉ nói lý thuyết thôi thì hơi chán nên chúng ta sẽ thực hành song song với lý thuyết luôn nhé. Mình sẽ dùng docker để triển khai trước cho trường hợp Single Node:
# Trường hợp single node
services:
es-single-node:
container_name: es-single-node
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
environment:
- xpack.security.enabled=false
- "discovery.type=single-node"
ports:
- 9200:9200
networks:
- es-net
networks:
es-net:
driver: bridge
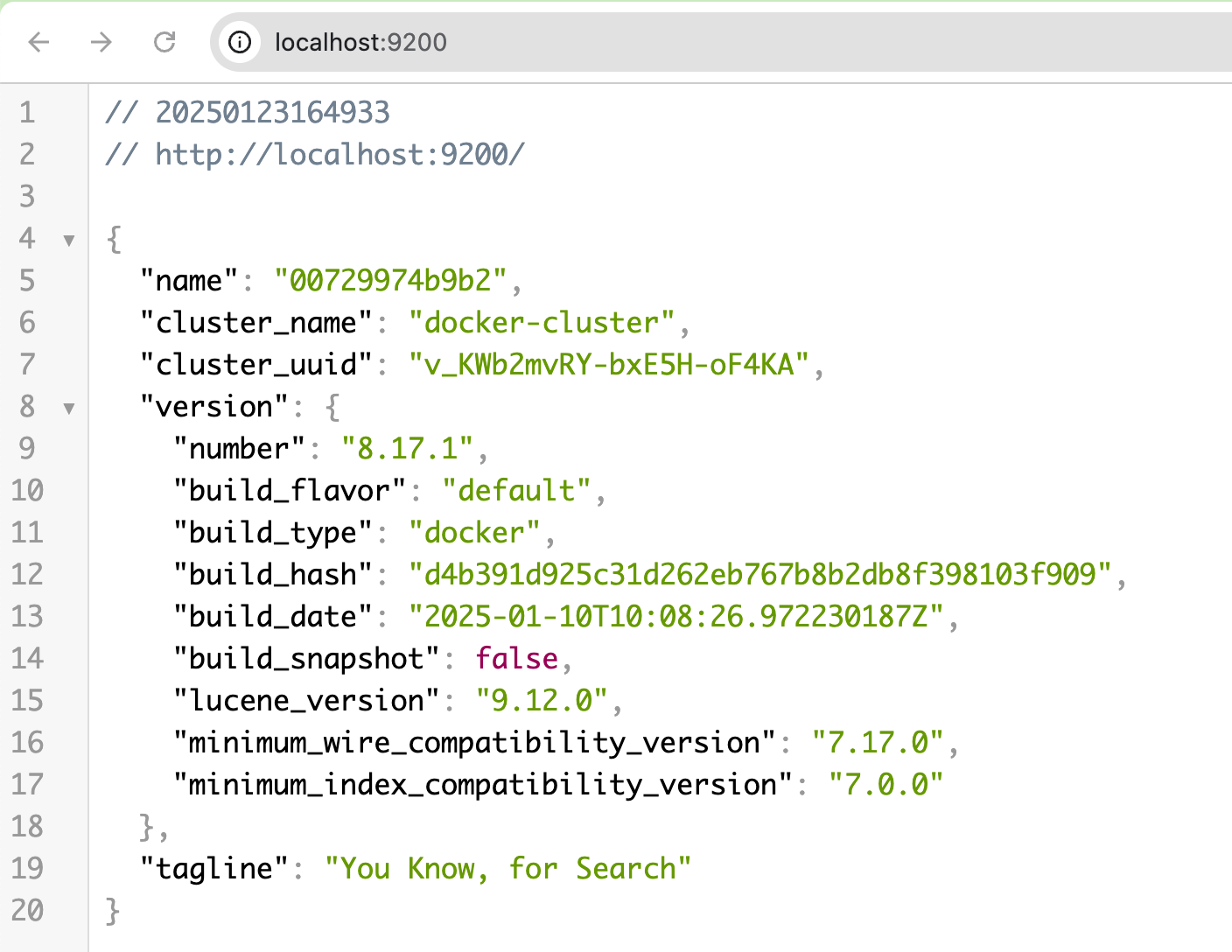
Sau khi run docker compose up -d, truy cập http://localhost:9200 và thấy như hình bên dưới là xong, quá trình setup Single Node chỉ đơn giản như vậy thôi.
Trường hợp cài Multiple Node lát nữa chúng ta sẽ tìm hiểu nhé.
2. Node
Như đã nói ở trên, khi chúng ta start một instance của Elasticsearch nó sẽ tạo ra 1 Node. Khi một Node mới được thêm vào hệ thống, nếu trên cùng một máy/server Node đó sẽ tự join vào Cluster khi chúng ta cấu hình cluster.name giống nhau - đây là khả năng scale dễ dàng 2️⃣ mà ban đầu mình nhắc đến.
Trường hợp khác máy/server thì cần config thêm danh sách unicast mà Node có thể kết nối. Các bạn có thể tham khảo cách làm của bác dinhhoanglong91
Node có tổng cộng 7 loại bên dưới, nhưng trong phạm vi bài viết này chúng ta chỉ nói về 3 loại đầu tiên:
| Loại Node 💠 | Vai trò chính 🫡 | Thường dùng cho ✅️ | Viết tắt |
|---|---|---|---|
| Master | Quản lý trạng thái cluster, phân bổ shard, và metadata của index. | Quản lý cluster | m |
| Data | Lưu trữ dữ liệu, thực hiện indexing, phân tích và tìm kiếm. | Xử lý dữ liệu và truy vấn. | d |
| Coordinating | Phân phối yêu cầu từ client đến các Node thích hợp và tổng hợp kết quả tìm kiếm. | Xử lý để tổng hợp kết quả truy vấn hoặc đóng vai trò như một bộ cân bằng tải. | c |
| Ingest | Tiền xử lý (preprocessor) tài liệu trước khi index. | Biến đổi và làm giàu dữ liệu (ví dụ: phân tích log, làm dữ liệu địa lý). | i |
| Remote-Eligible | Hỗ trợ giao tiếp giữa các cluster cho việc tìm kiếm và sao chép dữ liệu. | Tìm kiếm và sao chép dữ liệu giữa nhiều cluster. | r |
| Machine Learning | Chạy các công việc machine learning như phát hiện bất thường và dự đoán. | Phân tích nâng cao và phát hiện mẫu dữ liệu. | l |
| Transform | Xử lý biến đổi dữ liệu và các phép tổng hợp (ví dụ: chuyển đổi dữ liệu, tạo rollup). | Tạo các chỉ mục tổng hợp và các bảng nhìn tổng quan phân tích. | t |
Mỗi Node đều độc lập với nhau và đều có thể handle:
- HTTP: tất cả các Node đều có thể nhận REST request từ client. Khi nhận request từ client, Node đó trở thành Coordinate Node.
- Transport layer: các giao tiếp giữa các Node với nhau. Do đó mỗi Node trong Elasticsearch đều biết về tất cả các Node còn lại nên có thể dễ dàng forward client request đến các Node thích hợp. Giao tiếp này dễ thấy nhất khi Coordinate Node điều phối yêu cầu tới các Node khác để nhận về kết quả.
Với kiến trúc Single Node ở trên thì Node đó có thể là bất cứ loại nào và thường không được khuyến khích dùng cho môi trường Production. Chúng ta sẽ dựng luôn kiến trúc Multiple Node trên cùng 1 máy và cho chạy ở port 9200 (nhớ tắt Single Node vừa chạy khi nảy nhé) để kiểm chứng các nội dung trên. File này mình lấy trực tiếp từ trang của Elasticsearch, mọi người có thể tải về ở link này
services:
setup:
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- certs:/usr/share/elasticsearch/config/certs
user: "0"
command: >
bash -c '
if [ x${ELASTIC_PASSWORD} == x ]; then
echo "Set the ELASTIC_PASSWORD environment variable in the .env file";
exit 1;
elif [ x${KIBANA_PASSWORD} == x ]; then
echo "Set the KIBANA_PASSWORD environment variable in the .env file";
exit 1;
fi;
if [ ! -f config/certs/ca.zip ]; then
echo "Creating CA";
bin/elasticsearch-certutil ca --silent --pem -out config/certs/ca.zip;
unzip config/certs/ca.zip -d config/certs;
fi;
if [ ! -f config/certs/certs.zip ]; then
echo "Creating certs";
echo -ne \
"instances:\n"\
" - name: es01\n"\
" dns:\n"\
" - es01\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
" - name: es02\n"\
" dns:\n"\
" - es02\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
" - name: es03\n"\
" dns:\n"\
" - es03\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
> config/certs/instances.yml;
bin/elasticsearch-certutil cert --silent --pem -out config/certs/certs.zip --in config/certs/instances.yml --ca-cert config/certs/ca/ca.crt --ca-key config/certs/ca/ca.key;
unzip config/certs/certs.zip -d config/certs;
fi;
echo "Setting file permissions"
chown -R root:root config/certs;
find . -type d -exec chmod 750 \{\} \;;
find . -type f -exec chmod 640 \{\} \;;
echo "Waiting for Elasticsearch availability";
until curl -s --cacert config/certs/ca/ca.crt https://es01:9200 | grep -q "missing authentication credentials"; do sleep 30; done;
echo "Setting kibana_system password";
until curl -s -X POST --cacert config/certs/ca/ca.crt -u "elastic:${ELASTIC_PASSWORD}" -H "Content-Type: application/json" https://es01:9200/_security/user/kibana_system/_password -d "{\"password\":\"${KIBANA_PASSWORD}\"}" | grep -q "^{}"; do sleep 10; done;
echo "All done!";
'
healthcheck:
test: [ "CMD-SHELL", "[ -f config/certs/es01/es01.crt ]" ]
interval: 1s
timeout: 5s
retries: 120
es01:
depends_on:
setup:
condition: service_healthy
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- certs:/usr/share/elasticsearch/config/certs
- esdata01:/usr/share/elasticsearch/data
# - ./logs:- /whatever/host/path/you/like:/usr/share/elasticsearch/logs
ports:
- ${ES_PORT}:9200
environment:
- node.name=es01
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es02,es03
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es01/es01.key
- xpack.security.http.ssl.certificate=certs/es01/es01.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es01/es01.key
- xpack.security.transport.ssl.certificate=certs/es01/es01.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
- xpack.ml.use_auto_machine_memory_percent=true
mem_limit: ${MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test: [ "CMD-SHELL", "curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'" ]
interval: 10s
timeout: 10s
retries: 120
es02:
depends_on:
- es01
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- certs:/usr/share/elasticsearch/config/certs
- esdata02:/usr/share/elasticsearch/data
environment:
- node.name=es02
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es01,es03
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es02/es02.key
- xpack.security.http.ssl.certificate=certs/es02/es02.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es02/es02.key
- xpack.security.transport.ssl.certificate=certs/es02/es02.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
- xpack.ml.use_auto_machine_memory_percent=true
mem_limit: ${MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test: [ "CMD-SHELL", "curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'" ]
interval: 10s
timeout: 10s
retries: 120
es03:
depends_on:
- es02
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- certs:/usr/share/elasticsearch/config/certs
- esdata03:/usr/share/elasticsearch/data
environment:
- node.name=es03
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es01,es02
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es03/es03.key
- xpack.security.http.ssl.certificate=certs/es03/es03.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es03/es03.key
- xpack.security.transport.ssl.certificate=certs/es03/es03.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
- xpack.ml.use_auto_machine_memory_percent=true
mem_limit: ${MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test: [ "CMD-SHELL", "curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'" ]
interval: 10s
timeout: 10s
retries: 120
kibana:
depends_on:
es01:
condition: service_healthy
es02:
condition: service_healthy
es03:
condition: service_healthy
image: docker.elastic.co/kibana/kibana:${STACK_VERSION}
volumes:
- certs:/usr/share/kibana/config/certs
- kibanadata:/usr/share/kibana/data
ports:
- ${KIBANA_PORT}:5601
environment:
- SERVERNAME=kibana
- ELASTICSEARCH_HOSTS=https://es01:9200
- ELASTICSEARCH_USERNAME=kibana_system
- ELASTICSEARCH_PASSWORD=${KIBANA_PASSWORD}
- ELASTICSEARCH_SSL_CERTIFICATEAUTHORITIES=config/certs/ca/ca.crt
mem_limit: ${MEM_LIMIT}
healthcheck:
test: [ "CMD-SHELL", "curl -s -I http://localhost:5601 | grep -q 'HTTP/1.1 302 Found'" ]
interval: 10s
timeout: 10s
retries: 120
volumes:
certs:
driver: local
esdata01:
driver: local
esdata02:
driver: local
esdata03:
driver: local
kibanadata:
driver: local
Chúng ta cập nhật lại 1 số thông tin trong file .env. Elasticsearch version 8.17.1 là phiên bản stable tại thời điểm hiện tại của bài viết.
# Password for the 'elastic' user (at least 6 characters)
ELASTIC_PASSWORD=boilerplate-nestjs
# Password for the 'kibana_system' user (at least 6 characters)
KIBANA_PASSWORD=boilerplate-nestjs
# Version of Elastic products
STACK_VERSION=8.17.1
# Set the cluster name
CLUSTER_NAME=docker-multi-node-cluster
# Set to 'basic' or 'trial' to automatically start the 30-day trial
LICENSE=basic
# Port to expose Elasticsearch HTTP API to the host
ES_PORT=127.0.0.1:9200
# Increase or decrease based on the available host memory (in bytes)
MEM_LIMIT=2147483648
Lưu ý ở trên file docker-compose.yml mình có bổ sung thêm service Kibana dashboard để lát chúng ta thao tác trực tiếp trên Dev Tool cho dễ.
Kibana còn nhiều công dụng khác, chúng ta sẽ tìm hiểu ở bài viết về ELK stack, các bạn nhớ đón xem nhé.
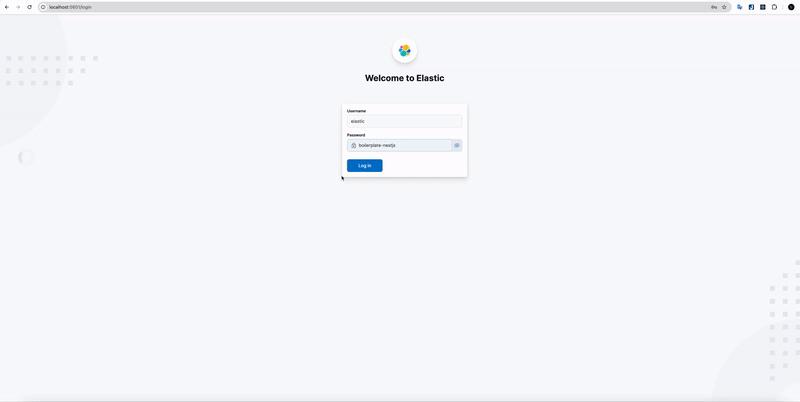
Sau khi docker compose up -d, sẽ mất khoảng 3-5 phút để hệ thống setup Cluster và các Node bên trong. Khi xong thì truy cập trực tiếp vào Kibana với port 5601 http://localhost:5601 để đăng nhập. Thông tin username là elastic còn password là giá trị chúng ta set ở KIBANA_PASSWORD=boilerplate-nestjs trong file .env.
Sau khi login mình sẽ truy cập vào Dev Tool như gif bên dưới, chạy lệnh GET _cluster/health để kiểm tra tình trạng Cluster. "status": green và "number_of_nodes": 3 biểu thị cho chúng ta thấy đang khởi chạy thành công 1 Cluster với 3 Node.
Bạn nào gặp các lỗi sau thì có thể tham khảo cách fix của mình nhé:
- Exit code 78: chạy lệnh sau
sudo sysctl -w vm.max_map_count=262144- Exit code 137: nâng
MEM_LIMITtrong file .env, ban đầu để mặc định nên sẽ dễ gặp lỗi này, các bạn nâng lênMEM_LIMIT=2147483648nếu bị nhé
2.1 Master Node 🧑⚖️
Như đã đề cập ở trên mỗi Cluster sẽ có một Node được chọn làm Master Node, chịu trách nhiệm thêm/xoá Node vào Cluster cũng như tạo/xoá Index. Để kiểm tra Node nào đang là master chúng ta có thể xem bằng lệnh GET _cat/nodes?v. Thử chạy lệnh đó trên Dev Tool Kibana xem sao nhé:
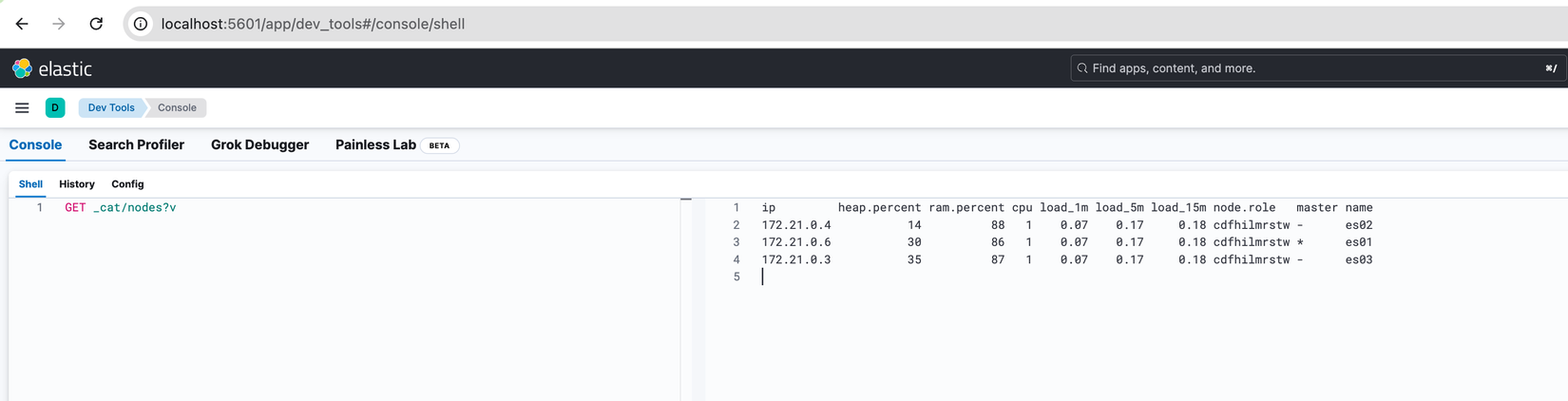
Có thể thấy service es01 đang là Node chịu trách nhiệm làm Master Node. Các bạn nhìn thêm vào cột node.role sẽ thấy các giá trị cdfhilmrstw, đây là viết tắt bao gồm tất cả các role do ban đầu chúng ta không chỉ định role cho chúng.
⚠️ Đối với các hệ thống có lượng traffic lớn, khi dùng ở môi trường Production chúng ta nên chỉ định riêng 1 Node làm Master để nó không phải tham gia vào quá trình đọc/ghi dữ liệu (loại bỏ role "d": Data Node) vì có thể gây giảm hiệu năng.
2.2 Coordinate Node 👮
Mặc định nếu chúng ta không config trước thì bất cứ Node nào khi nhận được request thì ngay lập tức trở thành Coordinate Node, chịu trách nhiệm phân bổ yêu cầu đến các Node cụ thể. Lát nữa khi tìm hiểu xong khái niệm về Shard chúng ta sẽ nói rõ hơn về loại Node này.
Ở trên chúng ta dùng Kibana và có khai báo
ELASTICSEARCH_HOSTS=https://es01:9200nên request sẽ trực tiếp gọi đến Node es01 và có thể coi nó luôn là Coordinate Node trong trường hợp này.
3. Index
Index tương tự như Database ở RDBMS, nếu Database có Table/Schema để lưu trữ dữ liệu thì Index có các Shard. Index đơn giản là một Logical Namespace trỏ tới một hoặc nhiều Physical Shards (nghe hàn lâm quá 😅). Giải thích đơn giản hơn thì ở RDBMS chúng ta gọi trực tiếp đến Table nhưng ở Elasticsearch thì chúng ta lại không gọi trực tiếp đến Shard mà sẽ thông qua Index.
Chúng ta thử tạo 1 Index để kiểm chúng luôn nhé, qua Kibana và dùng lệnh PUT /demo-index
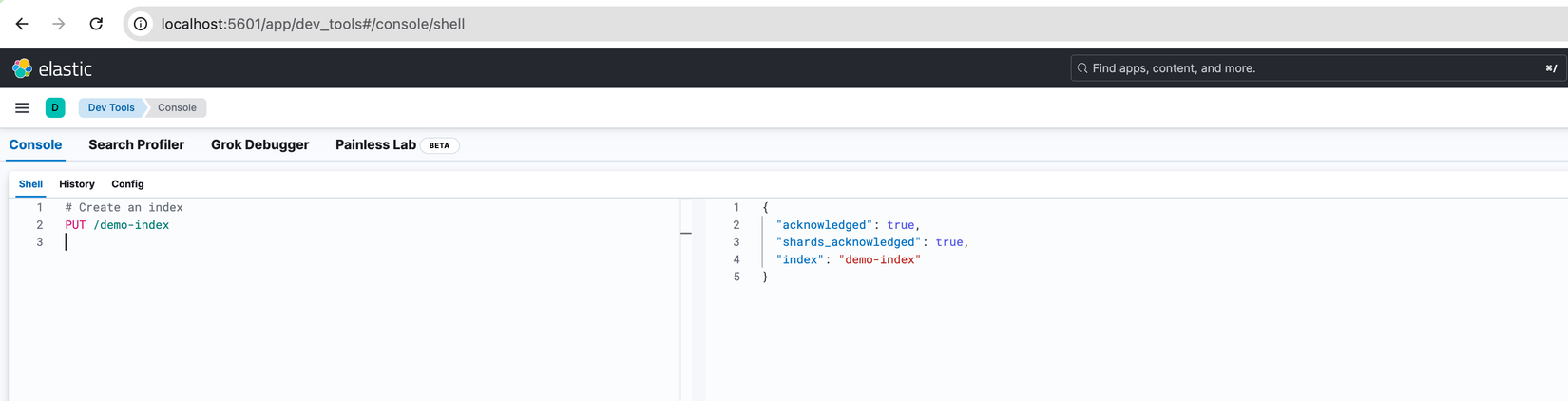
Sau đó kiểm tra với lệnh GET /_cat/shards/demo-index?v, nhìn vào kết quả chúng ta thấy được có 1 Primary Shard được tạo ra ở Node es01 và 1 Replica Shard ở Node es02.
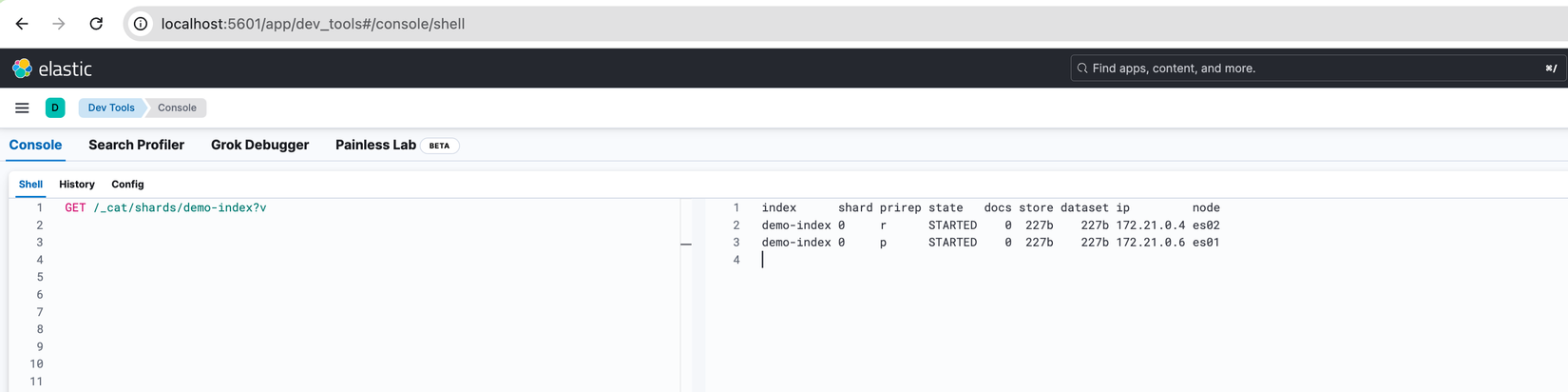
Ở thời điểm version 8.17.1 khi chúng ta tạo Index nếu không chỉ định số lượng thì Elasticsearch mặc định sẽ dùng giá trị là 1 cho Primary Shard và Replica Shard (từ version 7.0.0 trở về trước thì mặc định là 5 Primary Shard). Chúng ta hoàn toàn có thể control số lượng bằng cách bổ sung các params lúc tạo Index, do chưa tìm hiểu về Shard nên tạm thời chúng ta xoá Index vừa tạo với lệnh DELETE /demo-index để đến phần kế tiếp tạo lại và nói sâu hơn nhé.
Đến đây mặc dù đã đạt được mục tiêu High Availability 🟢 nhưng lại không mang lại không tận dụng được khả năng tăng tốc độ đọc dữ liệu khi có nhiều Node của Cluster 🔴. Hiện tại thì mọi data đều chỉ lưu vào 1 Shards ở es01 và replicate sang es02.
4. Shards
"Mỗi node sẽ gồm nhiều shard là các đối tượng của Lucene. Shard hoạt động ở mức thấp nhất, đóng vai trò lưu trữ dữ liệu. Chúng ta gần như không bao giờ làm việc trực tiếp với shard, Elasticsearch quản lý toàn bộ giao tiếp với shard, tự động thay đổi khi cần thiết." - dinhhoanglong91
Khi Cluster của chúng ta mở rộng hoặc thu hẹp (tăng/giảm số lượng các Node), Elasticsearch sẽ tự động migrate các Shard giữa các Nodes để Cluster giữ được trạng thái cân bằng.
Ví dụ minh hoạ: chúng ta có 3 Node, và tạo 1 Index với cấu hình 3 Primary Shard và mỗi Primary Shard có 2 Replica thì Elasticsearch sẽ chia mỗi Node chứa 3 Shard bao gồm 1 Primary và 2 Replica. Khi chúng ta tiến hành xoá 1 Node, Elasticsearch sẽ tự động điều chỉnh lại để đảm bảo tính toàn vẹn dữ liệu trong trường hợp 1 trong 2 Node còn lại bị lỗi.
Chúng ta cùng thao thác thử xem sao nhé, đầu tiên là tạo Index:
PUT /demo-index
{
"settings": {
"number_of_shards": 3, // Index này có 3 Primary Shard
"number_of_replicas": 2 // Mỗi Primary Shard có 2 Replica Shard
}
}
Tiến hành kiểm tra lại kết quả sau khi tạo:
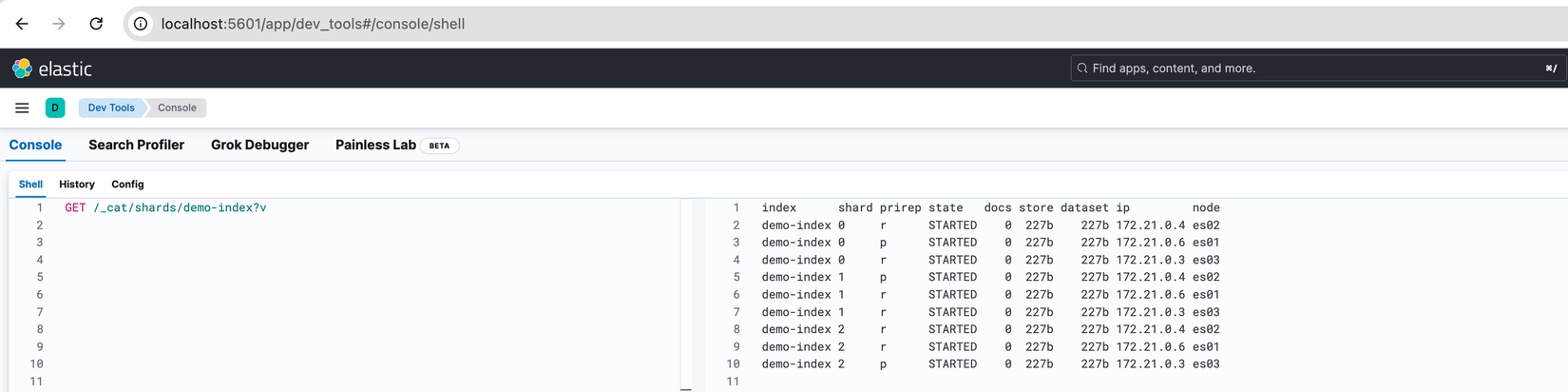
Có thể thấy được 3 Primary Shard đã được tạo ra và được phân bố đồng đều ở cả 3 Node. Bên cạnh đó tương ứng với mỗi Primary sẽ có 2 Replica Shard và chúng cũng được trải đều trên các Node.
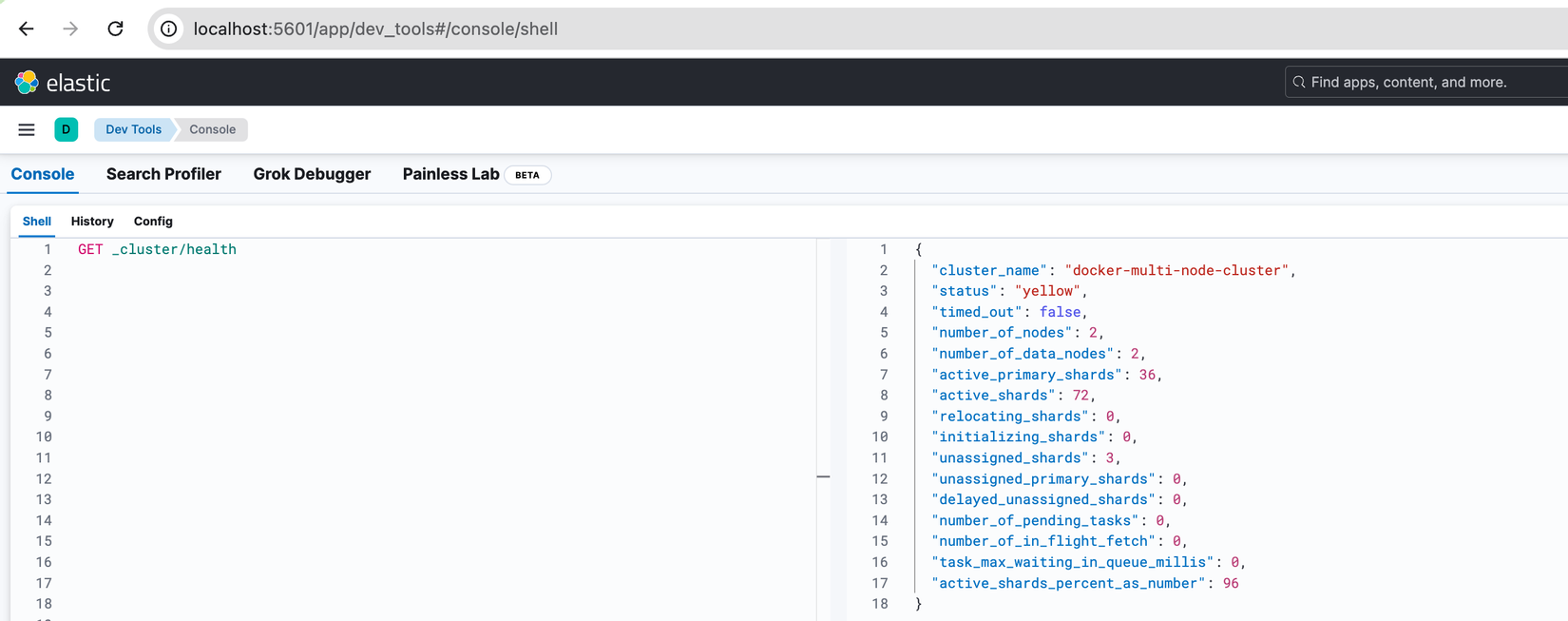
Chúng ta thử tắt Node es02 xem sao nhé, "number_of_nodes": 2 biểu thị chỉ còn 2 Node trong Cluster. Bên cạnh đó "status": "yello" cũng là vấn đề chúng ta cần lưu tâm, nó biểu thị dữ liệu có khả năng bị mất nếu các Node còn lại hiện tại xảy ra vấn đề.
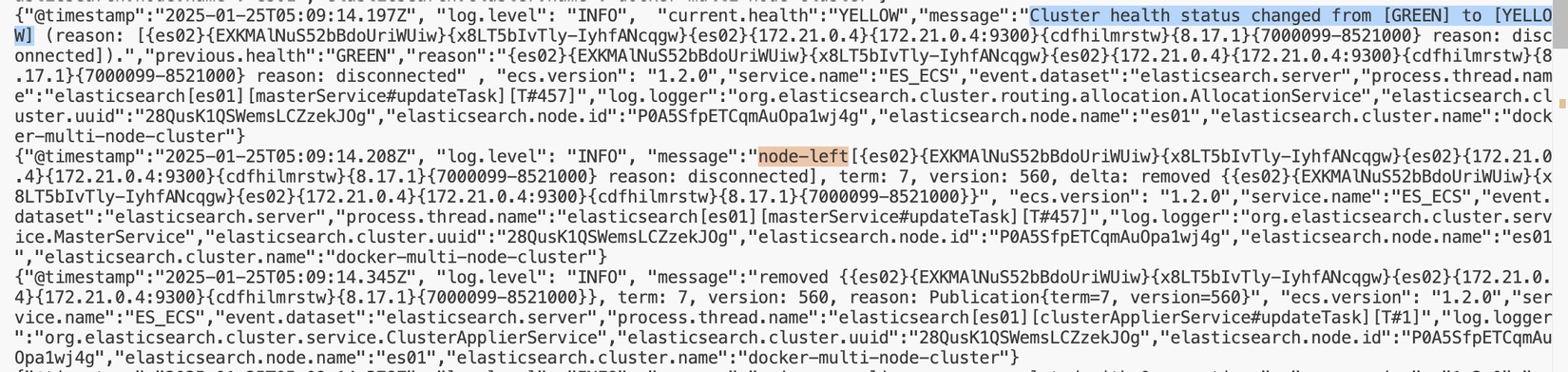
Khi nhìn vào logs của Master Node es01 các bạn sẽ thấy 1 thông báo status của Cluster thay đổi và 1 thông báo có node-left (2 chỗ mình highlight)
Ngoài ra khi kéo xuống 1 tí sẽ thấy thêm thông báo tiến hành phân bổ lại Shard sau 59.7 giây:

💡 Lý do không phân bổ lại ngay lập tức mà phải delay 1 thời gian để tránh trường hợp Node bị rớt mạng, bởi vì khối lượng công việc cho quá trình phân bổ lại Shard sẽ tỉ lệ thuận với lượng dữ liệu. Do đó nếu chỉ vì 1 Node rớt mạng khoảng 10 - 15 giây mà phải phân bổ lại Shard thì rất lãng phí tài nguyên 🤕.
Sau khi chờ thời gian trên trôi qua chúng ta vào xem lại thì thấy Primary Shard ở Node es02 đã được phân bố sang es01, các Replica Shard cũng phân bố lại để đảm bảo dữ liệu và hệ thống hoạt động ổn định, nếu không đủ vị trí thì các Replica Shard sẽ ở trạng thái UNASSIGNED.
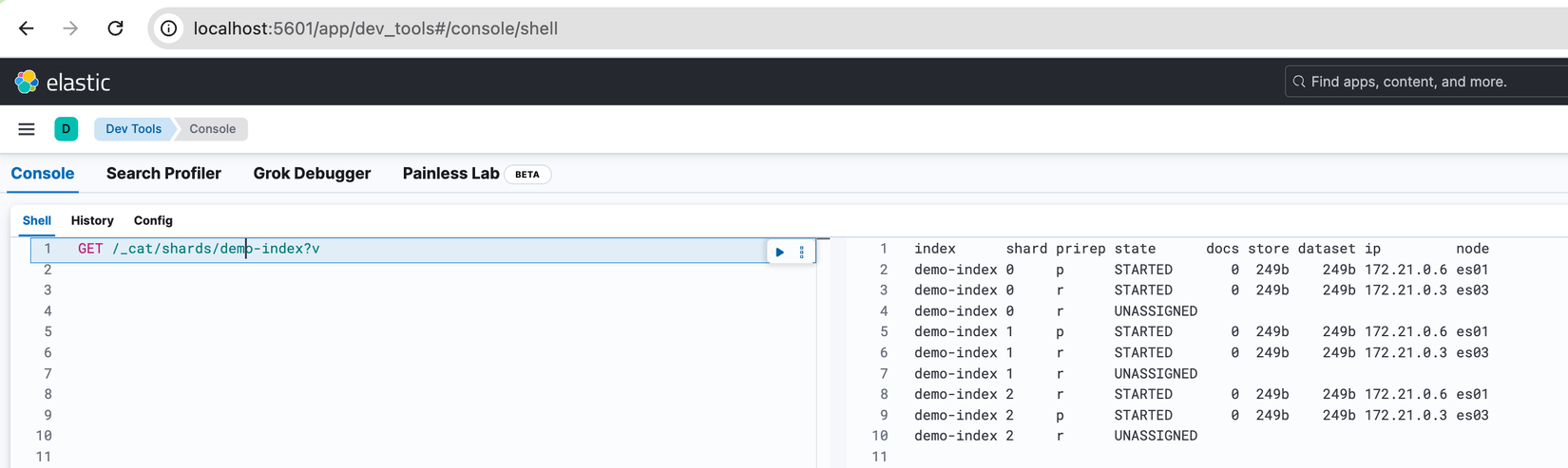
❓️Các bạn có thắc mắc tại sao 3 Replica Shard kia ở trạng thái UNASSIGNED không ⁉️ Câu trả lời là Elasticsearch không cho phép Primary Shard và Replica Shard cùng nằm trên 1 Node 💡.
❓️❓️Có thể các bạn sẽ nghĩ giống mình là tại sao lại không được, "trong trường hợp tôi đồng ý với rủi ro khi thiết lập cùng Node có thể gây mất dữ liệu nhưng đổi lại tôi muốn tận dụng khả năng tăng throughput của Replica Shard thì sao 😐️".
=> Câu trả lời theo mình tìm hiểu thì Elasticsearch có thể xử lý concurrent nên các query có thể được xử lý đồng thời bởi chính Primary Shard dựa vào multiple cores, do đó việc đặt Replica Shard chung với Primary Shard không mang lại ý nghĩa gì ngoài việc tiêu tốn thêm tài nguyên 😂.
Start lại Node es02 xem thử xem sao nhé mọi người 😁:

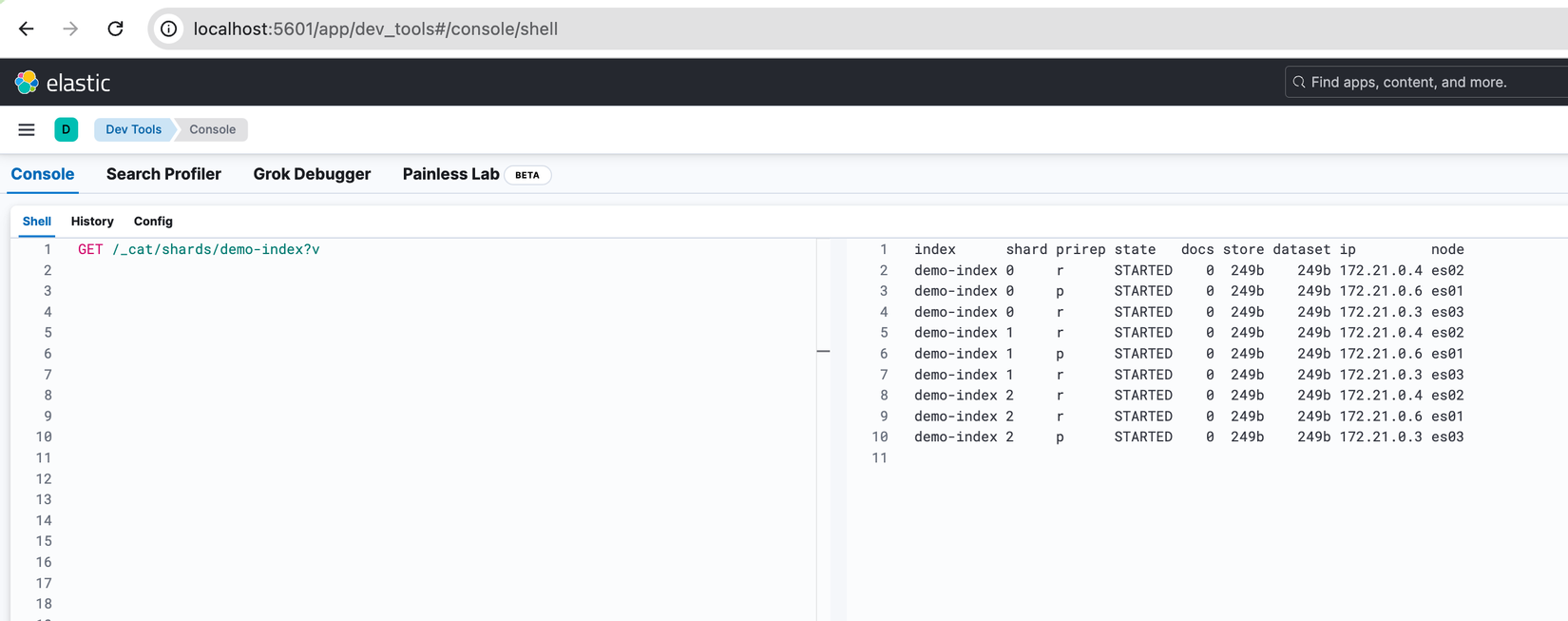
Sau khi khởi động lại xong thì ở Master Node sẽ có log node-join, khác với khi Node mất kết nối, khi có Node join vào thì ngay lập tức được phân bổ lại các Shard, có thể thấy được khả năng High Availability của Elasticsearch rất mạnh mẽ 🦾.
Khi data được index thì sẽ luôn đi vào Primary shard, sau đó được copy song song vào các Replica Shard liên kết với nó.
4.1 Primary Shard 👤
Ở trên chúng ta đã biết document được lưu vào Primary Shard, nhưng trong môi trường phân tán có rất nhiều Shard, vậy làm sao để biết được document sẽ được lưu vào shard nào 😲❓️
Câu trả lời tương tự như sharding ở các database chúng ta cũng sẽ có công thức, Elasticsearch khi routing document tới các shards sử dụng công thức sau:
shard = hash(routing) % number_of_primary_shards
Giải thích:
routingcó thể là một string bất kỳ, mặc định Elasticsearch sẽ dùng_idcủa documentnumber_of_primary_shardslà số lượng Primary Shard, có phạm vi từ 0 đến số lượng shards - 1.
Do áp dụng công thức trên nên khi đọc tài liệu của Elasticsearch chúng ta mới thấy có quy tắc là:
⚠️ Chỉ có thể khởi tạo số lượng Primary shard một lần duy nhất trong lúc tạo Index. ⚠️
Vì nếu số lượng Primary Shard thay đổi thì các routing value chúng ta dùng để đẩy document vào các Primary Shard trước đó không còn đúng nữa, dẫn đến các document đó sẽ không thể tìm thấy chính xác được.
Dành cho trường hợp các bạn có suy nghĩ là nếu set cứng như vậy sẽ khó để scale lên thì Elasticsearch bảo rằng chúng ta đừng lo lắng, họ có nhiều cách để scale lên ở link này: Designing for Scale.
Cách đơn giản nhất là tạo Index mới với số lượng Primary Shard mong muốn, sau đó chuyển document từ Index cũ sang bằng API
_reindex. Có một cách khác là dùng Split hoặc Shrink API để điều chỉnh số lượng Shard, nhưng bản chất cũng là reindex, chẳng qua Elasticsearch sẽ xử lý giùm chúng ta thôi.
4.2 Replica Shard 👥
Chúng ta đều biết data được lưu trữ toàn bộ trên các Primary Shard, điều này sẽ dẫn đến một vấn đề là khi Node chứa Shard đó bị lỗi thì có thể gây ra tình trạng mất dữ liệu.
Replica Shard ra đời để giải quyết vấn đề trên, nó là bản sao dữ liệu của Primary Shard , Elasticsearch sẽ lưu trữ chúng ở các Node khác so với Primary Shard. Do đó khi Primary Shard có vấn đề thì ngay lập tức các Replica Shard sẽ chọn ra một ứng cử viên mới thay thế cho Primary shards vừa bị lỗi (quá trình này diễn ra trong thời gian rất ngắn) nhằm đảm bảo dữ liệu luôn được bảo toàn.
Ngoài ra Replica Shard cũng có một công dụng tuyệt vời khác là giúp tăng thoughput bằng việc xử lý các Read Request như đã nói ở trên. Việc này tương tự như hệ thống Replica ở các công nghệ khác.
Ở các phần trên chúng ta đã tìm hiểu sơ qua về một số khái niệm trong kiến trúc của Elasticsearch. Phần tiếp theo chúng ta sẽ cùng bàn về cách Elasticsearch lưu và query data, từ đó có được cái nhìn rõ ràng nhất về cách nó hoạt động để chúng ta có thể tận dụng được tối đa sức mạnh của nó.
How it works? 🤔
1. Tìm hiểu cách Elasticsearch lưu data
Chúng ta sẽ bắt đầu phần này bằng câu hỏi: "Những hoạt động gì sẽ xảy ra khi Elasticsearch index document❓️"
Ở bài viết trước về Text Index trong MongoDB chúng ta đã biết về một số khái niệm như: Without Diacritics, Process Filter Words, Steamming, Casing. Đó là các giai đoạn tiền xử lý (preprocess), ở Elasticsearch cũng tương tự và được gọi là Analysis, dùng để xử lý document thành các token trước khi lưu vào Inverted Index.
Inverted Index là kết quả của bảng Index như hình bên dưới mà ở bài viết trước mà chúng ta đã tìm hiểu:
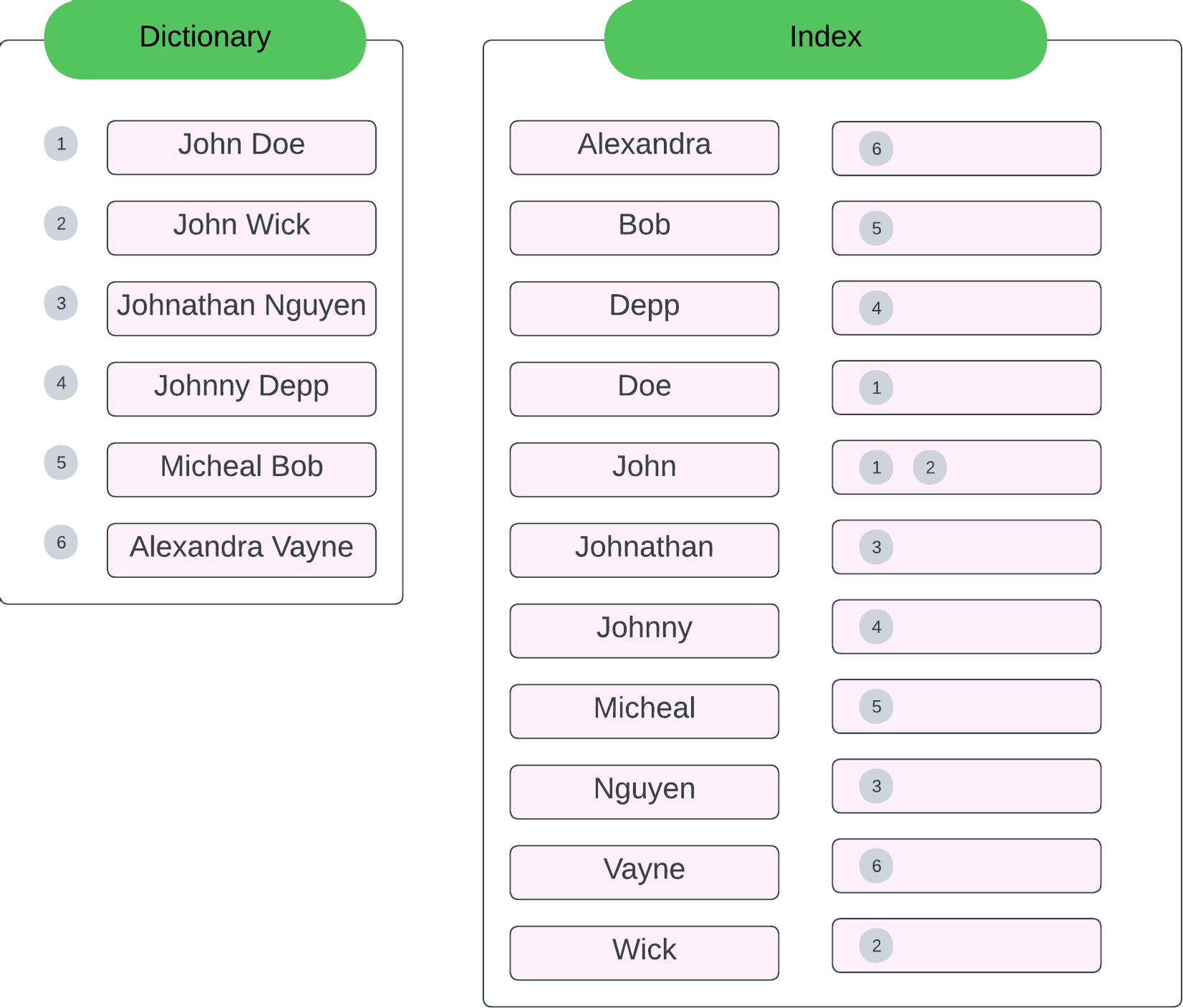
Elasticsearch khi tiến hành xử lý document (gọi là Analyze sẽ chia làm 3 giai đoạn, mỗi giai đoạn đều sẽ nhận vào input và cho ra output:
- Character filter
- Tokenizer
- Token Filter
Chúng ta sẽ tìm hiểu chi tiết hơn bằng việc đi vào từng giai đoạn để tìm hiểu về khái niệm và kết hợp với ví dụ tích hợp Analyzer API step by step nhé.
1.1 Character Filter
Character Filter sẽ thêm, xoá hoặc chỉnh sửa các ký tự. Ví dụ loại bỏ tag HTML, chuyển các ký tự từ Hindu-Arabic (٠١٢٣٤٥٦٧٨٩) sang Arabic-Latin (0123456789).
Giả sử chúng ta có câu: "<strong>I am a developer in developer in 2025! ٣٤٥٦٧</strong> và sẽ thử với html_strip
POST _analyze
{
"char_filter": ["html_strip"],
"text": "<strong>I am a developer in developer in 2025! ٣٤٥٦٧</strong>"
}
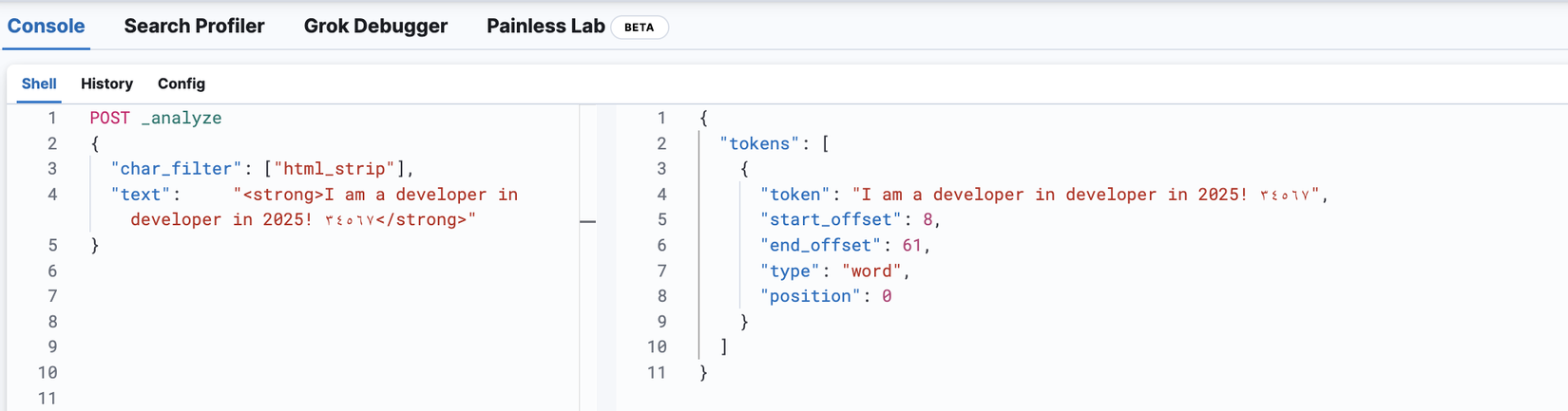
Từ kết quả thấy được rằng các ký tự HTML đã bị xoá đi, tuy nhiên các ký tự Hindu-Arabic thì vẫn còn tồn đọng. Giờ chúng ta sẽ tiếp tục áp dụng thêm filter mapping
POST _analyze
{
"char_filter": ["html_strip", {
"type": "mapping",
"mappings": [
"٣ => 3",
"٤ => 4",
"٥ => 5",
"٦ => 6"
]
}],
"text": "<strong>I am a developer in developer in 2025! ٣٤٥٦٧</strong>"
}
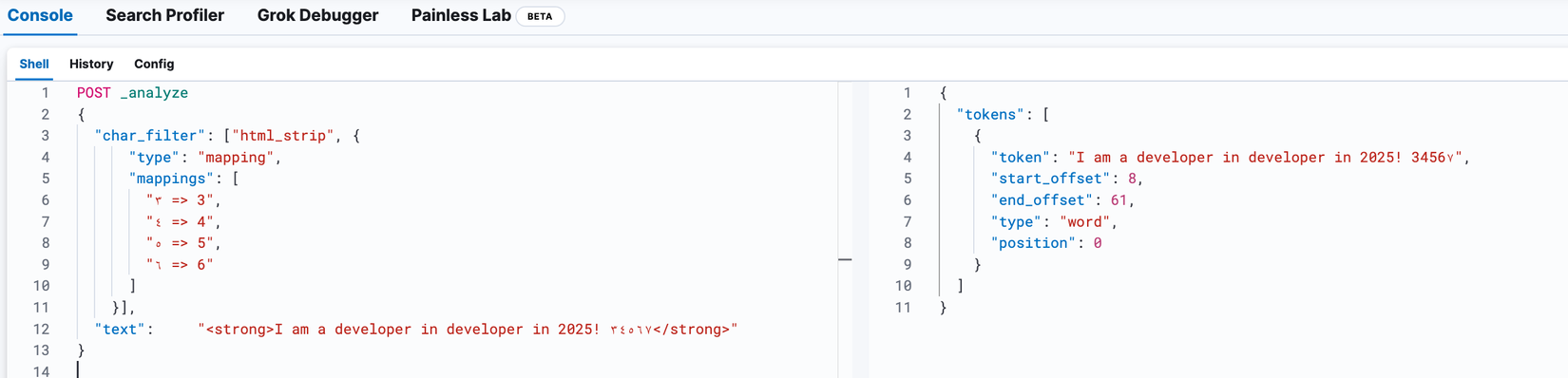
Ở trên mình cố tình bỏ mapping cho ký tự ٧ nên các bạn thấy ở kết quả vẫn còn xuất hiện ký tự này. Với ví dụ trên chúng ta thấy được Elasticsearch đã xử lý giảm bớt được độ phức tạp của document và cũng giúp chúng ta có thể kiểm soát được các ký tự nếu muốn ✅️. Output từ giai đoạn này sẽ được chuyển đến làm Input cho bước Tokenizer tiếp theo.
1.2 Tokenizer
Tokenizer mặc định sẽ nhận vào 1 chuỗi ký tự và cắt chúng thành các token khi gặp ký tự khoảng cách (whitespace). Ví dụ "I am a developer in developer in 2025!" sẽ được chuyển thành [I, am, a, developer, in, 2025]. Cùng mình thử xem sao nhé:
POST _analyze
{
"tokenizer": "standard",
"text": "I am a developer in developer in 2025!"
}
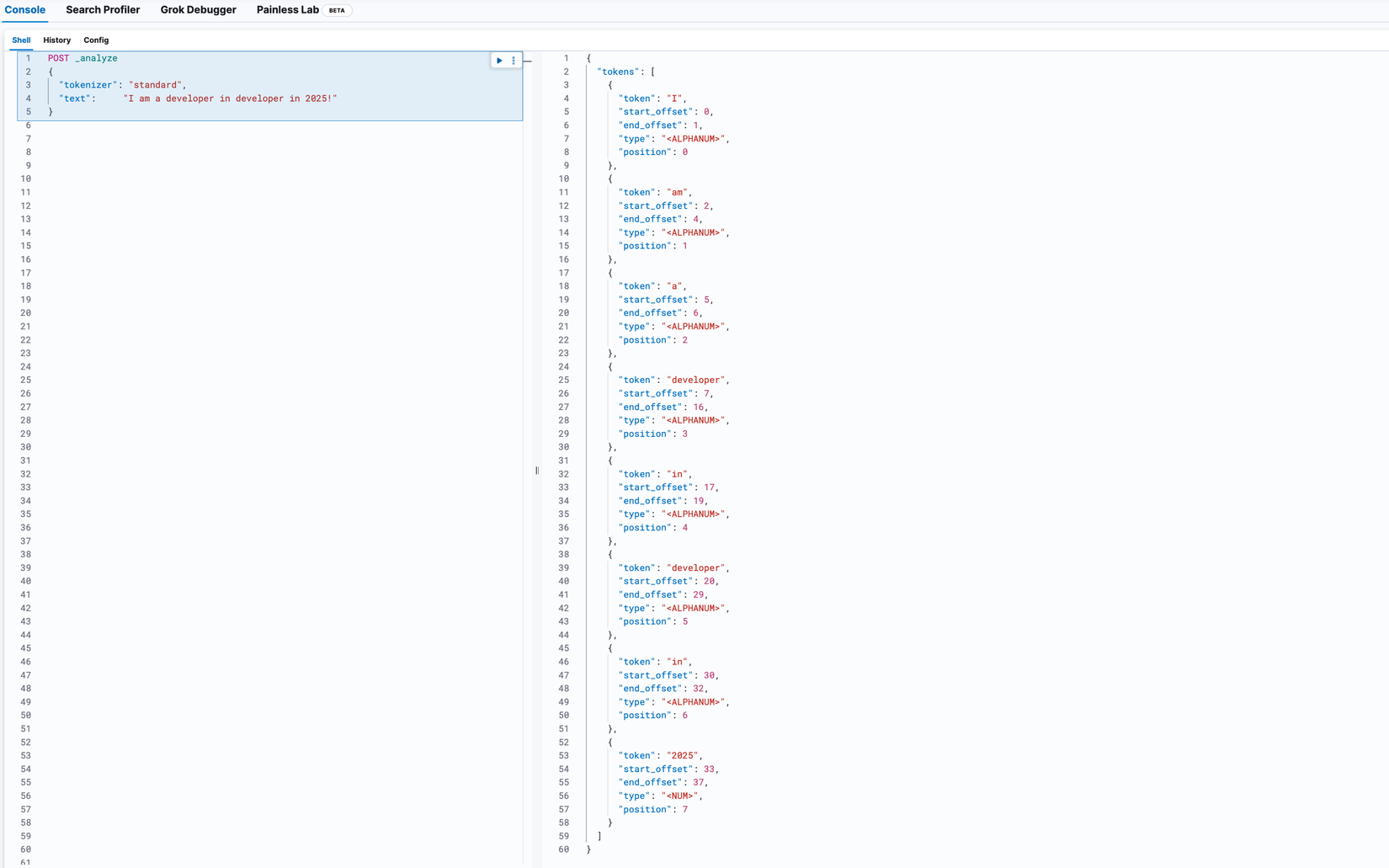
Trên hình ngoại trừ chia ra thành các token, Tokenizer lưu thêm các field khác như type, position, start_offset, end_offset nhằm mục đích:
- Ghi nhớ vị trí của từng token trong chuỗi để phục vụ cho trường hợp query phrase và word proximity. Ví dụ Elasticsearch sẽ lưu term của chúng ta kèm position như sau:
| Token | Position |
|---|---|
| I | 1 |
| am | 2 |
| a | 3 |
| blogger | 4 |
| in | 5 |
| 2025 | 6 |
- Ghi nhớ ký tự đầu tiên và cuối cùng của từ gốc mà term hiện diện, dùng cho trường hợp highlighting search snippets.
| Token | Start Offset | End Offset |
|---|---|---|
| I | 0 | 1 |
| am | 2 | 4 |
| a | 5 | 6 |
| blogger | 7 | 14 |
| in | 15 | 17 |
| 2025 | 18 | 22 |
Ví dụ chúng ta tìm từ "developer" thì kết quả trả về như sau:
"I am a <em>developer</em> in 2025!"
# Thêm(index) document vào demo-index
POST /demo-index/_doc
{
"content": "I am a developer in developer in 2025!"
}
# Highlight search
GET /demo-index/_search
{
"query": {
"match": {
"content": "developer"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
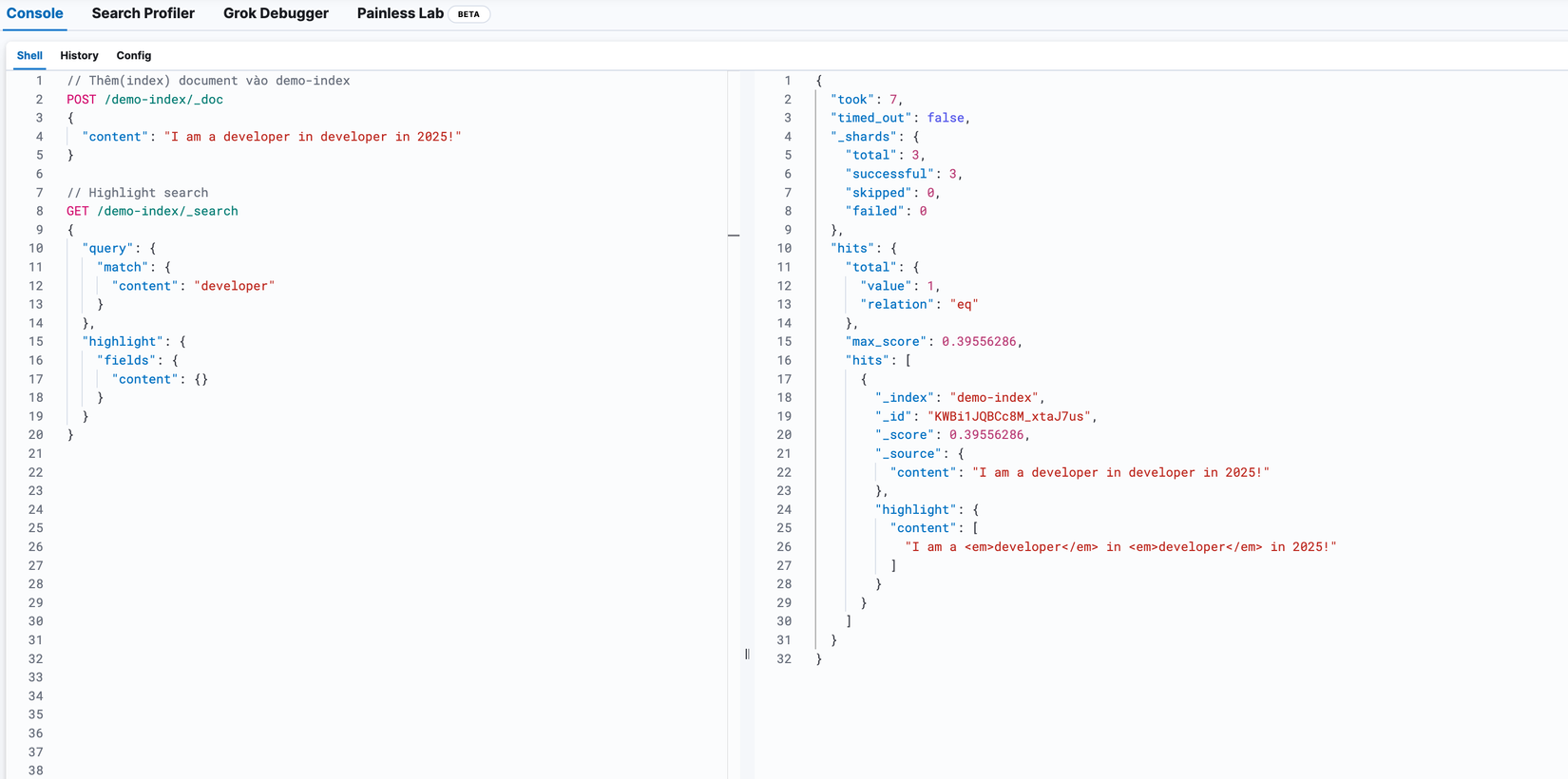
Các bạn thấy ở phần hits > highlight > content thì từ khoá tìm kiếm developer của chúng ta được highlight lên với tag <em>
- Lưu trữ token type như
<ALPHANUM>, <HANGUL>, <NUM>, <EMOJI>,..., chỉ dùng đến với các trường hợp chúng ta muốn tìm kiếm theo 1 type nào đó, khi đó Elasticsearch sẽ ignore các type còn lại.
| Token | Token Type |
|---|---|
| I | ALPHANUM |
| am | ALPHANUM |
| a | ALPHANUM |
| developer | ALPHANUM |
| in | ALPHANUM |
| 2025 | NUM |
Document sau khi được Tokenizer cắt ra thành các term sẽ được chuyển tiếp đến bước cuối cùng là Token Filter bên dưới.
1.3 Token filter
Token filter tương tự như Process Filter Words, nó sẽ nhận kết quả từ Tokenizer và thực hiện các filter:
- Chỉnh sửa chuyển về ký tự viết thường:
lowercase - Loại bỏ các stopwords (như
a, an, the, is, at, which,...trong ngôn ngữ "en"):stop - Chuyển các từ về nguyên mẫu:
stemmer - Thêm vào các token (ví dụ từ đồng nghĩa) tuỳ theo cách chúng ta chọn custom analyzer:
synonym - ... và nhiều filter khác nữa
Quay lại với ví dụ của chúng ta "I am a developer in developer in 2025!" sau khi Tokenizer thì đến Token Filter trải qua một số filter sẽ còn như sau: [I, am, develop, 2025]
POST _analyze
{
"tokenizer": "standard", # Cần thêm bước này để Elasticsearch chuyển document thành Term
"filter": ["lowercase", "stop", "stemmer"],
"text": "I am a developer in 2025!"
}
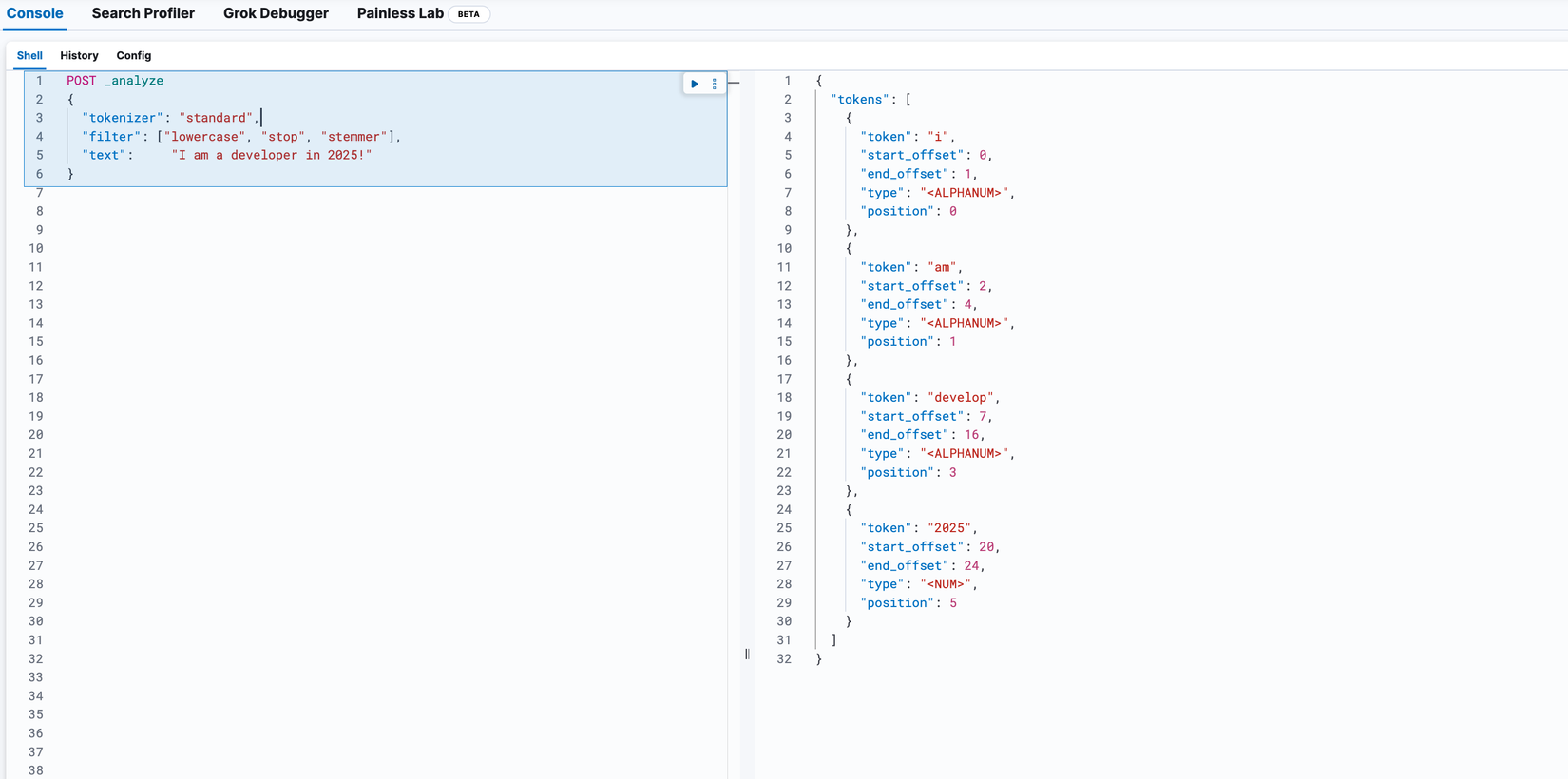
Trong trường hợp các bạn muốn xem chi tiết hơn có thể thêm field explan: true vào như bên dưới, khi đó chúng ta sẽ thấy khi trải qua từng filter thì các term sẽ được xử lý như thế nào:
POST _analyze
{
"tokenizer": "standard",
"explain": true, # <=== Thêm vào đây
"filter": ["lowercase", "stop", "stemmer"],
"text": "I am a developer in 2025!"
}
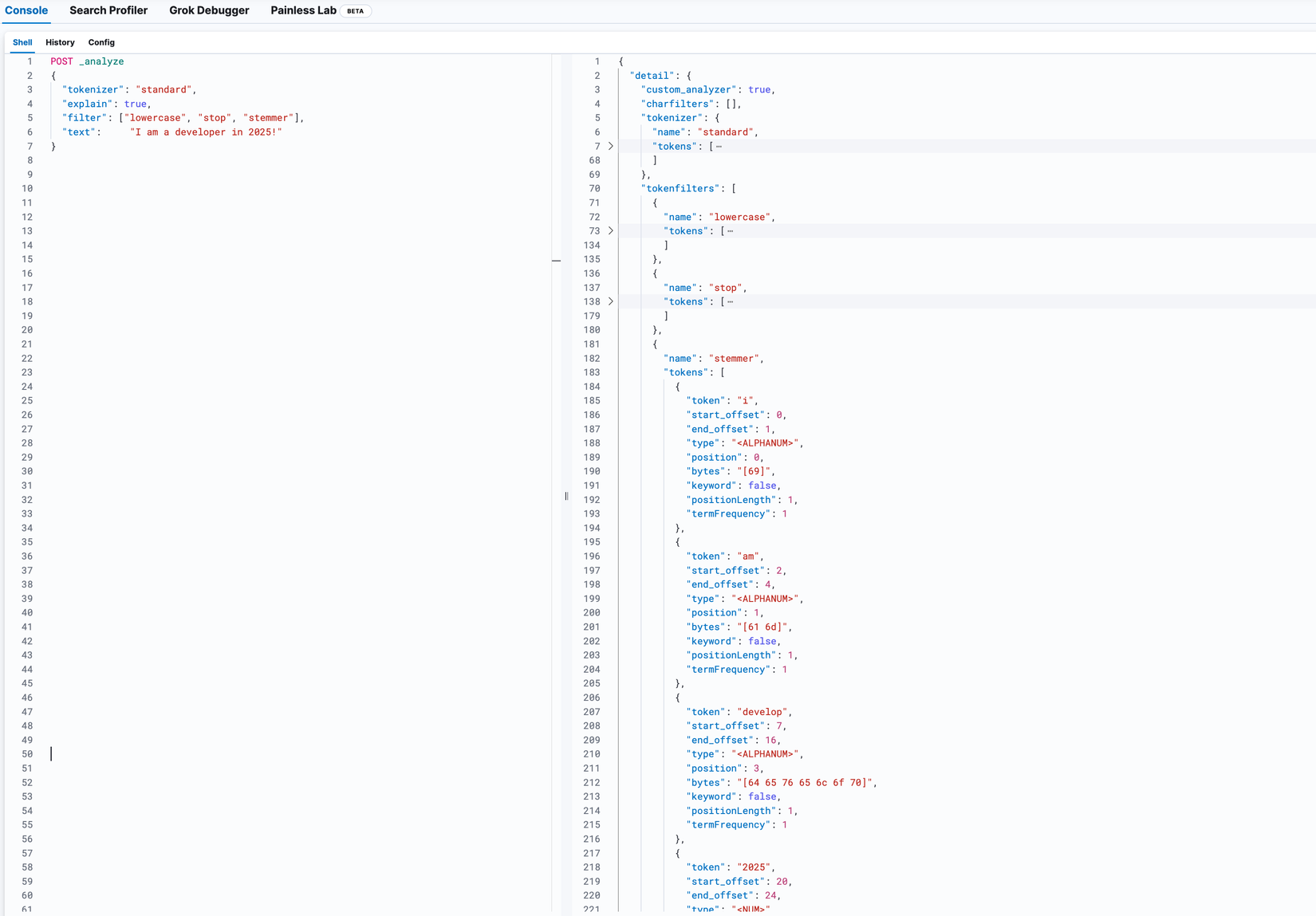
Sau khi trải qua giai đoạn Analyzer, kết quả cuối cùng sẽ được lưu trữ vào Inverted Index.
💡Object có bao nhiêu field sẽ có tương ứng bấy nhiêu Inverted Index.
Tổng kết lại nếu chúng ta có 2 document và dùng Analyzer như ví dụ ở trên thì sẽ thu được Inverted Index như bảng phía dưới:
{
"name": "John Doe",
"description": "<i>I am a developer in 2025!</i>"
}
{
"name": "John Smith",
"description": "<strong>I am the main actor of the program </strong>"
}
- Field
name
| Terms | Documents |
|---|---|
| doe | document-1 |
| john | document-1, document-2 |
| smith | document-2 |
- Field
description
| Terms | Documents |
|---|---|
| 2025 | document-1 |
| actor | document-2 |
| am | document-1, document-2 |
| develop | document-1 |
| i | document-1, document-2 |
| main | document-2 |
| program | document-2 |
Vậy là chúng ta đã tìm hiểu xong cách mà Elasticsearch index document, phần tiếp theo chúng ta sẽ cùng xem cách Elasticsearch query data diễn ra trong hệ thống Cluster như thế nào.
2 Tìm hiểu cách Elasticsearch search dữ liệu giữa các Node
Để thực hiện việc tìm kiếm Elasticsearch chia quá trình đó ra làm 2 giai đoạn gọi là query và fetch:
queryphrase 🔎: quá trình tìm kiếm document ở các Shardfetchphrase ⏬️: quá trình tổng hợp kết quả từ các Shard
2.1 Query phrase
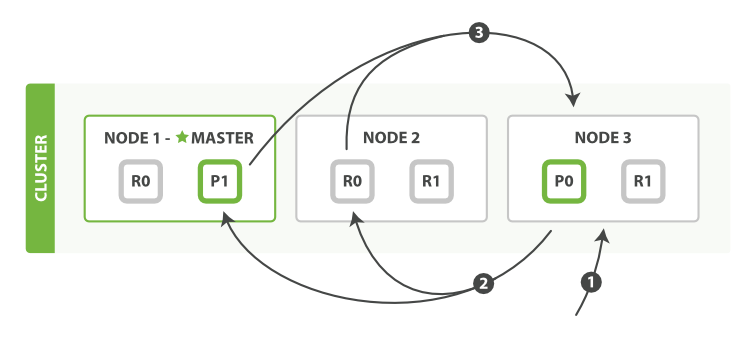
Nguồn: elastic.co
Khi request đến một Node bất kỳ, Node đó trở thành Coordinating Node (trên hình là Node 3). Khi đó, nó chịu trách nhiệm broadcast query đến các Shard có liên quan và thu thập kết quả từ các Shard đó và trả về cho client.
Khi query đến Shard, nó sẽ tạo ra 1 queue để chứa kết quả gọi là Priority queue, việc tìm kiếm sẽ được thực hiện local và đẩy kết quả vào Priority queue.
Priority queue là một danh sách đơn giản chứa các document tìm kiếm được, kích thước của nó phụ thuộc vào các tham số pagination
from+size.
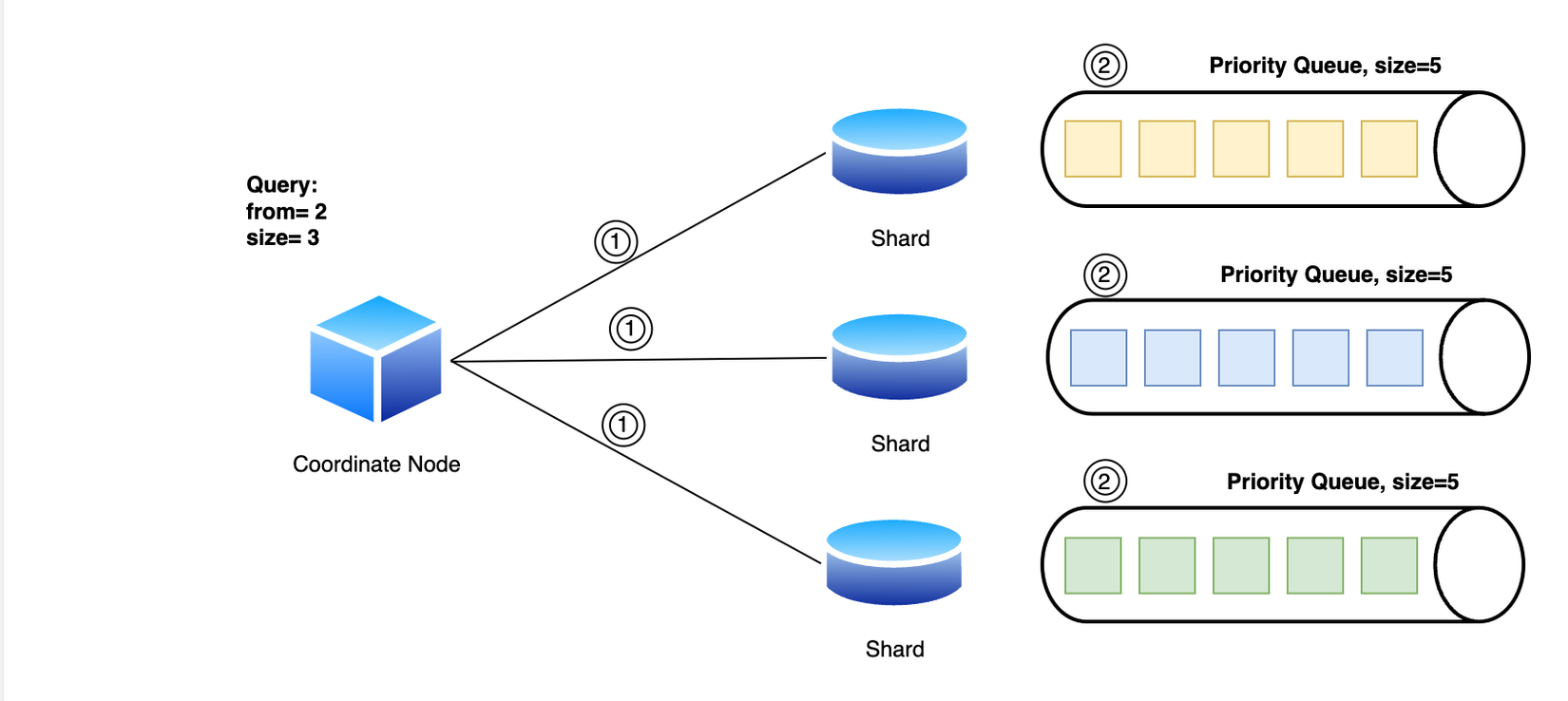
Sau khi hoàn thành nó sẽ trả về kết quả cho Coordinating node nhưng sẽ chỉ bao gồm id và các field cần thiết cho quá trình sorting như _score.
Coordinating node nhận kết quả từ các Shard và tổng hợp vào Priority queue của riêng nó và kết lúc query phrase.
2.2 Fetch phrase
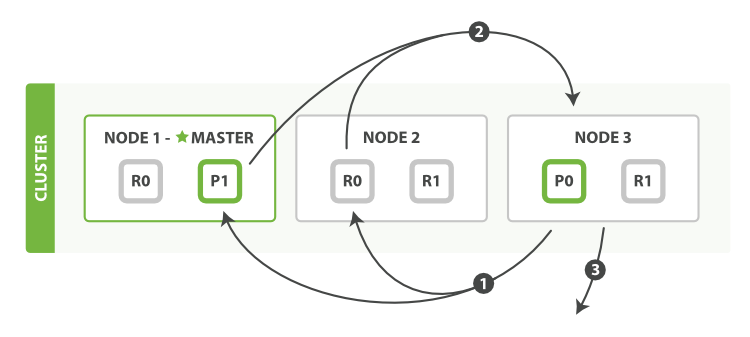
Nguồn: elastic.co
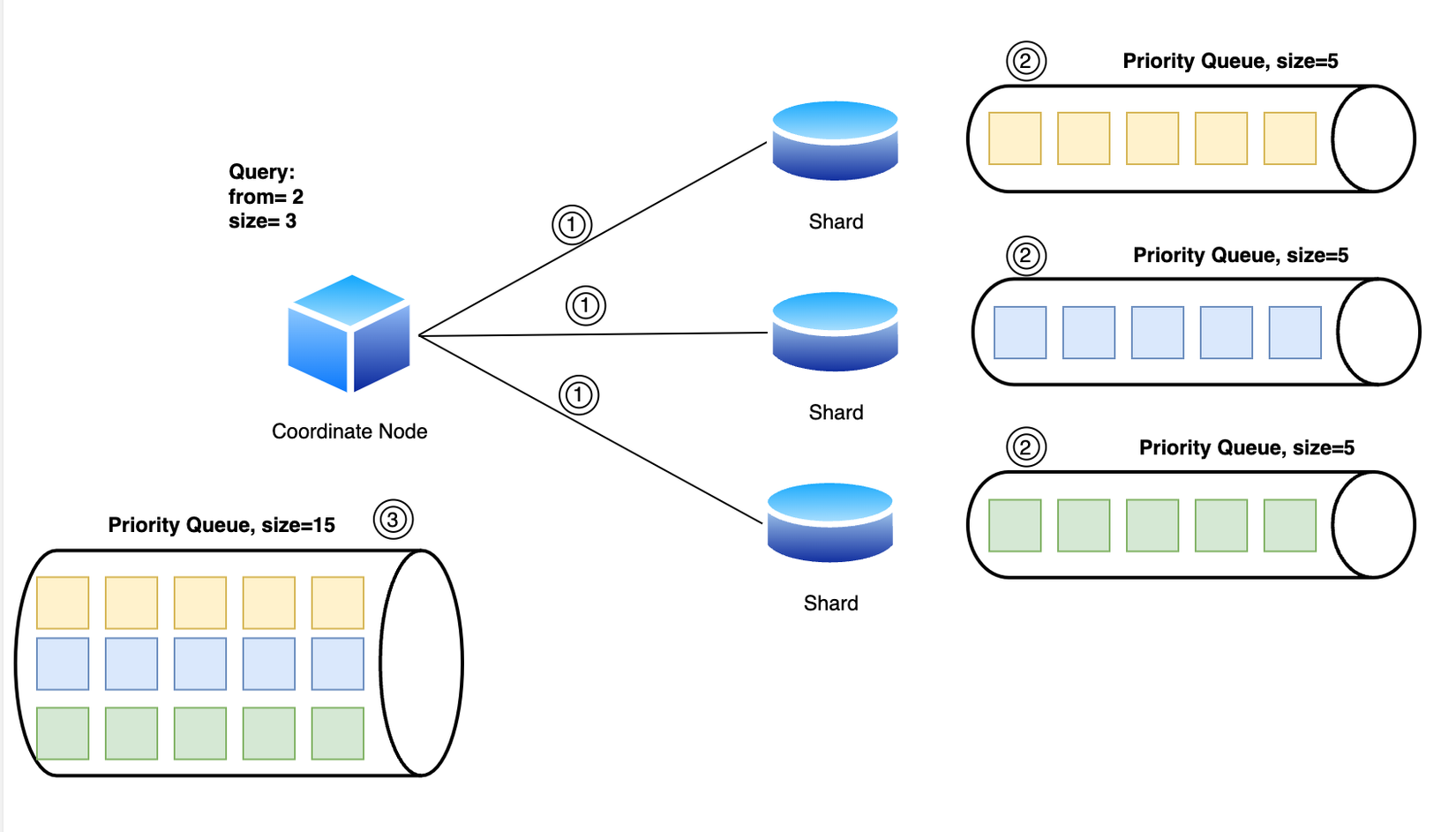
Ở phrase này Coordinating node tiếp tục nhiệm vụ của nó, xử lý kết quả từ các Shard gửi đến. Việc xử lý chỉ đơn giản loại bỏ các kết quả nằm ngoại phạm vi pagination dựa vào field _score.
Ví dụ chúng ta có pagination như sau: { "from": 2, "size": 3 }. Giả sử mỗi số được ghi trên ô là _score thì Coordinating node sẽ loại bỏ 2 kết quả đầu và chọn ra 3 kết quả tiếp theo có score cao hơn số còn lại.
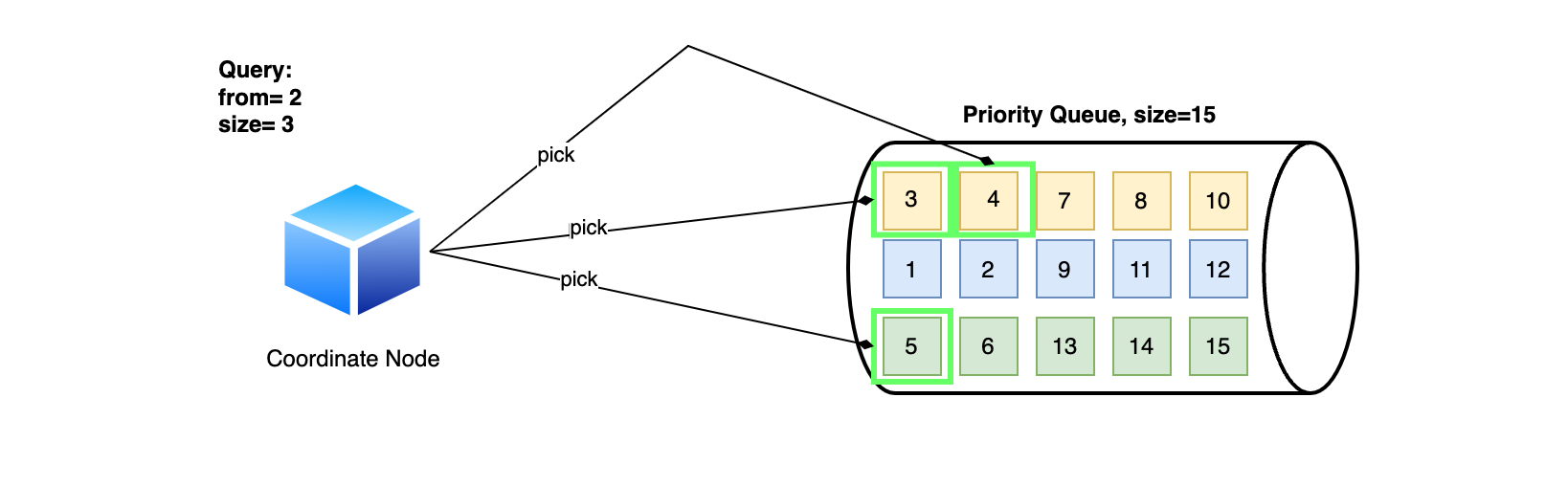
Tuy nhiên chúng ta cần lưu ý 3 kết quả này chỉ bao gồm id và các field dùng để search, không thể trả về cho client được. Coordinating node sẽ phải thực hiện thêm 1 bước nữa là dùng các id này gọi đến các Shard trước đó để lấy về data đầy đủ.
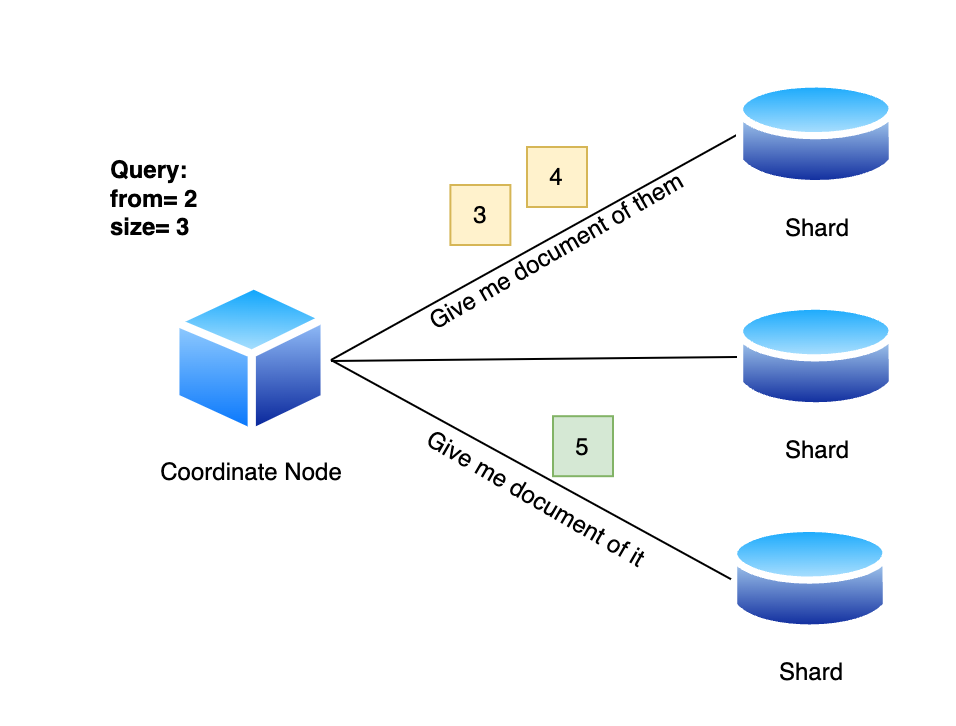
Có thể các bạn sẽ thấy quá trình này có vẻ dư thừa, tại sao các Shard không trả về đầy đủ data sau khi tìm kiếm để Coordinating node đỡ phải gọi thêm một lần. Tuy nhiên thứ chúng ta cần cân nhắc ở đây là chi phí khi trả về toàn bộ dữ liệu của kết quả chứ không phải là số lần gọi lấy kết quả. Ví dụ mỗi document là 10Kb, và chúng ta dùng pagination là
{ "from": 3, "size": 10 }và chúng ta có 3 Shard:
- Trường hợp trả về 1 lần thì mỗi shards trường hợp có đủ dữ liệu sẽ trả về 100 result * 10Kb = 1000Kb, vị chi sẽ tiêu tốn khoảng 4000Kb.
- Trường hợp chỉ trả về
idvà_scoregiả sử khoảng 0.2Kb cho mỗi document thì mỗi shards sẽ tốn 100 * 0.2Kb = 20Kb cho lần gọi đầu tiên, 4 Shard là 80Kb. Lần gọi thứ 2 chúng ta lấy ra 10 kết quả dựa theoidtừ các Shard sẽ tiêu tốn 10 * 10 = 100Kb. Tổng cộng 2 lần gọi tiêu tốn 80 + 100 = 180Kb.Có thể thấy kết quả chênh lệch giữa 2 trường hợp là khá nhiều, và khi pagination càng cao thì sự chênh lệch càng lớn.
Kết luận 📝
Vậy là chúng ta đã đi qua hết các phần từ kiến trúc, chức năng của từng thành phần trong Cluster đến quá trình Elasticsearch index document với Analyzer và lưu vào Inverted Index. Chúng ta cũng biết được để việc search được tối ưu Elasticsearch đã trải qua những Phrase nào. Vẫn còn nhiều những khái niệm như Precision, Recall,... mà chúng ta chưa tìm hiểu qua, nhưng hiện tại bài viết đã quá dài nên hẹn mọi người ở bài viết tiếp theo 😉. Bài viết tiếp theo chúng ta cũng sẽ thực hành nhiều hơn và áp dụng vào source code NestJS về Flash Card project mà trước giờ chúng ta làm để hình dung trong thực tế Elasticsearch sẽ hoạt động như thế nào nhé🤩.
Cảm ơn mọi người đã giành thời gian đọc bài viết, chúc mọi người năm mới vui vẻ và gặt hái được nhiều thành công 😊🎉.
Tài liệu tham khảo 🔍
- Andersen, B. (2018) Understanding analysis in Elasticsearch (analyzers), Coding Explained. Available at: https://codingexplained.com/coding/elasticsearch/understanding-analysis-in-elasticsearch-analyzers (Accessed: 05 February 2025).
- Character filters reference (no date) Elastic. Available at: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html (Accessed: 05 February 2025).
- Tokenizer reference (no date) Elastic. Available at: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html (Accessed: 05 February 2025).
- tripy_ran (2015) Inverted index per field, Discuss the Elastic Stack. Available at: https://discuss.elastic.co/t/inverted-index-per-field/31468 (Accessed: 05 February 2025).
- Mohan, A. (2018) What happens when a document is indexed in Elasticsearch?, Medium. Available at: https://medium.com/elasticsearch/what-happens-when-a-document-is-indexed-in-elasticsearch-16b7ae3415bc (Accessed: 05 February 2025).
- Nathani, R. (2016) Anatomy of an elasticsearch cluster: Part III, Medium. Available at: https://blog.insightdatascience.com/anatomy-of-an-elasticsearch-cluster-part-iii-8bb6ac84488d (Accessed: 05 February 2025).
- dinhhoanglong91 (2025) Elasticsearch: Distributed search, Viblo. Available at: https://viblo.asia/p/elasticsearch-distributed-search-ZnbRlr6lG2Xo#_shard-4 (Accessed: 05 February 2025).
Change log 📓
- February 06, 2025: Init document.
All rights reserved
