Tìm hiểu Dataset cho bài toán xây dựng hệ thống MRC (Machine Reading Comprehension)
Xin chào mọi người, trong bài viết này chúng ta sẽ cùng nhau tìm hiểu bài toán xây dựng hệ thống MRC (Machine Reading Comprehension) với mục tiêu là nâng cao khả năng tự động hiểu và xử lý thông tin từ các văn bản, giống với khả năng đọc hiểu của con người.
MRC là gì?
Với sự phát triển nhanh chóng của lĩnh vực Xử lý Ngôn ngữ Tự nhiên (NLP) đã dẫn đến bước tiến đáng kể của các hệ thống Machine Reading Comprehension (MRC), một lĩnh vực nghiên cứu nhằm nâng cao khả năng tự động hiểu và xử lý thông tin từ các văn bản giống với khả năng đọc hiểu của con người. MRC đặt mục tiêu là phân tích và hiểu sâu về nội dung của các tài liệu, từ đó trả lời các câu hỏi phức tạp dựa trên kiến thức đã được học.
Việc áp dụng hệ thống MRC đã mở ra một loạt các tiềm năng đối với nhiều lĩnh vực ứng dụng khác nhau, từ tìm kiếm thông tin trên Internet đến hỗ trợ quyết định trong y tế và tài chính, cũng như trong giáo dục và các lĩnh vực khác. Những tiến bộ trong nghiên cứu về MRC không chỉ đánh dấu bước tiến mới trong việc tự động hóa quá trình đọc và hiểu văn bản, mà còn mở ra cơ hội cho việc tạo ra các ứng dụng thông minh, có khả năng thích ứng và tương tác với con người một cách tự nhiên. Các hệ thống MRC không chỉ giúp tiết kiệm thời gian mà còn tăng hiệu quả, đặc biệt đối với các câu hỏi factoid. Những câu hỏi này yêu cầu thông tin cụ thể và chính xác về một sự kiện, một chủ đề, hoặc một người nào đó, và thường yêu cầu câu trả lời dựa trên các sự kiện, con số, ngày tháng, hoặc tên riêng.
Các ứng dụng sử dụng hệ thống MRC
- Hệ thống hỏi đáp: MRC đóng vai trò then chốt trong các hệ thống hỏi đáp, giúp xác định câu trả lời chính xác cho các câu hỏi phức tạp từ một tập văn bản lớn. Ví dụ, hệ thống có thể được sử dụng để trả lời các câu hỏi về lịch sử, khoa học, hoặc các sự kiện thời sự.
- Tóm tắt văn bản: MRC có thể được sử dụng để tóm tắt tự động các văn bản dài, giúp người dùng nhanh chóng nắm bắt nội dung chính mà không cần đọc toàn bộ văn bản.
- Trích xuất thông tin: MRC có thể được sử dụng để trích xuất các thông tin cụ thể từ văn bản, chẳng hạn như tên người, địa điểm, số liệu, v.v. Ứng dụng này hữu ích trong nhiều lĩnh vực như khai thác dữ liệu, báo chí, và nghiên cứu khoa học.
- Chatbots: MRC có thể được sử dụng để tạo ra chatbots thông minh hơn, có thể hiểu và phản hồi các câu hỏi phức tạp của người dùng một cách tự nhiên và chính xác.
- ....
MRC Corpus là gì?
Corpus đề cập đến tài liệu được dùng làm dữ liệu huấn luyện cho các mô hình ngôn ngữ lớn trong MRC (Machine Reading Comprehension). Nó bao gồm một loạt các câu hỏi và câu trả lời cùng với ngữ cảnh, bao gồm văn bản, báo cáo, truyện, cuộc hội thoại, v.v.
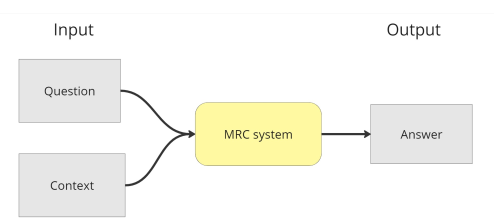
Mục đích của việc xây dựng corpus là cung cấp dữ liệu cho các mô hình ngôn ngữ, giúp chúng có khả năng hiểu ngôn ngữ tự nhiên. Điều này bao gồm việc suy diễn để trả lời các câu hỏi từ văn bản cung cấp và phân biệt giữa các câu hỏi có thể trả lời được và không thể trả lời.
Dựa vào của câu hỏi, dữ liệu được chia ra thành ba loại dựa trên định dạng của câu trả lời, bao gồm các dataset với câu trả lời trích xuất từ văn bản (extractive answers), câu trả lời mô tả (descriptive answers), và câu trả lời multiple-choice (multiple-choice answers).
Dữ liệu với câu trả lời trích xuất từ văn bản
Để đánh giá khả năng đọc hiểu của một hệ thống MRC, các tập dữ liệu sử dụng câu trả lời trích xuất từ văn bản, xuất phát từ các câu hỏi dạng Cloze. Các tập dữ liệu này cung cấp cho hệ thống một lượng lớn tài liệu hoặc đoạn văn, sau đó đặt ra các câu hỏi với các câu trả lời là đoạn văn tương ứng trong các đoạn văn đó. Một hệ thống MRC tốt sẽ chọn ra một đoạn văn đúng từ ngữ cảnh đã cho. Các bài kiểm tra hiểu biết như vậy hữu ích vì chúng có thể đánh giá một cách khách quan và có thể đo lường một loạt các khả năng quan trọng, từ hiểu cơ bản đến suy luận phức tạp.
Cả từ người làm công việc theo yêu cầu hoặc được tạo ra tự động từ các nguồn tài liệu khác nhau, các tập dữ liệu này đều sử dụng một phần văn bản trong tài liệu làm câu trả lời cho câu hỏi đề xuất. Dưới đây là một số ví dụ về các tập dữ liệu này:
- SQuAD (Stanford Question Answering Dataset) là một tập dữ liệu được sử dụng rộng rãi để đánh giá khả năng đọc hiểu của các hệ thống trí tuệ nhân tạo. Tập dữ liệu này bao gồm các cặp câu hỏi và câu trả lời được tạo bởi cộng đồng người dùng, với các đoạn văn được lấy từ các bài viết trên Wikipedia để tạo ra ngữ cảnh cho câu hỏi và câu trả lời. SQuAD có hai phiên bản: SQuAD1.0 và SQuAD2.0, với SQuAD2.0 bổ sung một trường dữ liệu mới để phân biệt câu hỏi có thể trả lời và không thể trả lời dựa trên ngữ cảnh được cung cấp.
- CNN/Daily Mail là một bước tiến quan trọng trong lĩnh vực đọc hiểu máy tính, được công bố bởi Google DeepMind và Đại học Oxford vào năm 2015. Tập dữ liệu này được tổng hợp từ 93.000 bài báo của CNN và 220.000 bài báo từ Daily Mail, tạo ra một nguồn tài nguyên phong phú và đa dạng. Đặc biệt, phiên bản ẩn danh của tập dữ liệu này được tạo ra để tập trung vào khả năng đọc hiểu của các mô hình máy tính mà không bị ảnh hưởng bởi các yếu tố bên ngoài như ngữ cảnh hoặc kiến thức trước đó về các thực thể cụ thể.
- CBT (Children's Book Test) được tạo ra dưới dự án bAbI của Facebook AI Research, sử dụng các câu chuyện từ sách thiếu nhi để đánh giá khả năng hiểu và suy luận của hệ thống AI. Tập dữ liệu này cung cấp các câu hỏi và câu trả lời dựa trên các chuỗi sự kiện trong các câu chuyện, với mục tiêu là thúc đẩy nghiên cứu trong lĩnh vực đọc hiểu máy.
- NewsQA được phát triển bởi Microsoft vào năm 2016, là tập dữ liệu được tạo ra để thử nghiệm và đánh giá khả năng hiểu và suy luận của các mô hình MRC. Tập dữ liệu này đặt ra một loạt các thách thức mới, đòi hỏi khả năng suy luận và tổng hợp thông tin từ nhiều nguồn khác nhau.
- TriviaQA là một tập dữ liệu phức tạp với hơn 650.000 cặp câu hỏi-câu trả lời-tài liệu chứng minh, được lấy từ 14 trang web trivia và quiz-league khác nhau. Các câu hỏi đơn giản hoặc không rõ ràng đã được loại bỏ, và các tài liệu chứng minh được tạo từ kết quả tìm kiếm trên web và các bài viết Wikipedia tương ứng với các thực thể được đề cập trong các câu hỏi.
- WIKIHOP là một tập dữ liệu phát hành vào năm 2018, với mục tiêu chính là đánh giá khả năng hiểu tài liệu của các hệ thống máy tính. Sự khác biệt chính so với các tập dữ liệu QA trước đó là thông tin cần thiết để trả lời câu hỏi được phân tán trong nhiều câu hoặc nhiều đoạn văn khác nhau, thách thức các mô hình MRC phải tổng hợp bằng chứng từ nhiều tài liệu khác nhau để trả lời câu hỏi. Điều này thúc đẩy sự phát triển của lĩnh vực này bằng cách tạo ra một thách thức mới cho các mô hình MRC.
Dữ liệu với câu trả lời mô tả
Dữ liệu với câu trả lời mô tả mang lại một phương tiện để đối diện với các câu hỏi trong bối cảnh thực tế. Nổi bật với 2 tập dữ liệu là MS MARCO và NarrativeQA
-
MS MARCO (MicroSoft MAchine Reading Comprehension) là một tập dữ liệu câu hỏi và trả lời được phát hành bởi Microsoft vào năm 2016 (phiên bản 1) và 2018 (phiên bản 2). Dữ liệu này được thu thập từ công cụ tìm kiếm Bing và trợ lý ảo Cortana, với mỗi câu hỏi được đáp ứng bằng cách hoàn thành một câu hoàn chỉnh được cung cấp từ kết quả tìm kiếm trên Bing. Tổng cộng, bộ dữ liệu này bao gồm 1.010.916 câu hỏi được lấy mẫu từ các truy vấn tìm kiếm trên Bing, trong đó có 182.669 câu hỏi có câu trả lời được cung cấp bởi người tạo ra.
-
NarrativeQA, được công bố bởi DeepMind và Đại học Oxford vào năm 2017, là một bộ dữ liệu tập trung vào các câu chuyện tự sự. Dữ liệu này được tạo ra bằng cách sử dụng công việc của nhóm crowdworkers, họ tạo ra các cặp câu hỏi và câu trả lời cho mỗi câu chuyện. Bộ dữ liệu bao gồm khoảng 45.000 cặp câu hỏi và câu trả lời, phân chia trên 1.567 câu chuyện, bao gồm cả sách và kịch bản phim. Mục tiêu của NarrativeQA là cung cấp một tài nguyên phong phú và đa dạng cho việc nghiên cứu trong lĩnh vực đọc hiểu máy, đặc biệt là trong lĩnh vực của các câu chuyện và văn bản tự sự.
Dữ liệu với câu trả lời multiple-choice
Tập dữ liệu kiểu câu trả lời multiple choice là một loại tập dữ liệu QA (Question Answering) trong đó mỗi câu hỏi đi kèm với một danh sách các lựa chọn trả lời, và hệ thống máy tính phải chọn một trong số các lựa chọn đó làm câu trả lời đúng.
-
MCTest là một tập dữ liệu QA được tập trung vào thể loại phim viễn tưởng. Dữ liệu này bao gồm 500 câu chuyện và 2000 câu hỏi, được thu thập thông qua việc thuê 500.000 công nhân thông qua Amazon Mechanical Turk. Công nhân được yêu cầu viết câu chuyện ngắn dành cho trẻ em và tạo bốn câu hỏi đọc hiểu liên quan đến câu chuyện của họ, mỗi câu hỏi đi kèm với bốn câu trả lời trắc nghiệm. Để đảm bảo tính phức tạp của nhiệm vụ, các công nhân được yêu cầu thiết kế câu hỏi sao cho ít nhất hai trong số bốn câu hỏi cần nhiều câu trong câu chuyện để trả lời.
-
RACE (Large-scale ReAding Comprehension Dataset from Examinations) là một tập dữ liệu đọc hiểu quy mô lớn với hơn 28.000 đoạn văn và gần 100.000 câu hỏi, được thu thập từ các kỳ thi tiếng Anh ở Trung Quốc. Bộ dữ liệu được chia thành hai phần: RACE-M cho học sinh trung học cơ sở và RACE-H cho học sinh trung học phổ thông. Các câu hỏi trong RACE được thiết kế để đánh giá khả năng hiểu và suy luận logic trong bối cảnh của các đoạn văn dài.
-
CLOTH (CLOze test by TeacHers) bao gồm gần 100.000 câu hỏi Cloze từ các bài kiểm tra tiếng Anh trung cấp và trung học phổ thông. Dữ liệu được làm sạch để loại bỏ các câu hỏi không nhất quán và các đoạn văn trùng lặp, đồng thời trích xuất câu trả lời từ hình ảnh sử dụng OCR.
-
MCScript (Machine Comprehension Using Script Knowledge) tập trung vào việc giải quyết các câu hỏi đòi hỏi suy luận dựa trên kiến thức thông thường, với 2.1K đoạn văn và 14K câu hỏi. Các câu trả lời đúng có thể không xuất hiện trực tiếp trong văn bản, đòi hỏi người đọc phải suy luận và hiểu biết sâu sắc về ngữ cảnh.
-
ARC (AI2 Reasoning Challenge) bao gồm các câu hỏi trắc nghiệm từ các bài kiểm tra chuẩn hóa, được chia thành hai phần: Easy Set và Challenge Set. Các câu trả lời đúng thường không được trực tiếp trích xuất từ các đoạn văn bản.
-
CoQA (Conversational Question Answering) bao gồm 126K câu hỏi từ 8K cuộc trò chuyện trong 7 lĩnh vực khác nhau, với mỗi cuộc trò chuyện được thực hiện bởi hai người chú thích đóng vai trò người hỏi và người trả lời.
Reference
Machine Reading Comprehension: a Literature Review: https://arxiv.org/abs/1907.01686
All rights reserved
