Tìm Hiểu LSTM: Bí Quyết Giữ Thông Tin Lâu Dài Hiệu Quả 🧠🔗
Trong bài trước Recurrent Neural Networks (RNNs), Clearly Explained!!!, chúng ta đã khám phá RNN mạng nơ-ron truy hồi xử lý dữ liệu chuỗi. Tuy nhiên, RNN gặp phải vấn đề "vanishing/exploding gradient" khiến chúng khó ghi nhớ thông tin dài hạn. Hôm nay, hãy gặp LSTM, "phiên bản nâng cấp" của RNN được trang bị bộ nhớ dài hạn thông minh nhờ cơ chế cổng (gating mechanism). Bài viết này sẽ giải thích kiến trúc, cách hoạt động, và tại sao LSTM vượt trội hơn RNN. Bài tiếp theo, chúng ta sẽ "mổ xẻ" chi tiết toán học và cơ chế giữ thông tin đặc biệt của LSTM! 🔍
LSTM là gì? 🤔
Long Short-Term Memory (LSTM) là một dạng đặc biệt của Recurrent Neural Network (RNN), được trang bị các cơ chế cổng (gating mechanisms):
- Cell state (bộ nhớ dài hạn): Như một "băng chuyền" chuyên chở thông tin xuyên suốt chuỗi thời gian.
- 3 cổng điều khiển: Quên (Forget Gate), Đầu vào (Input Gate), Đầu ra (Output Gate).
Cell state là trái tim của LSTM nơi lưu trữ thông tin "cần nhớ" qua hàng trăm bước thời gian!
Kiến trúc LSTM: 3 Cổng "Ma Thuật" 🧙♂️
-
Forget Gate
Forget Gate ( ): Quyết định phần nào của cell state cũ () cần bị loại bỏ, phần nào sẽ được giữ lại.
Hàm sigmoid cho đầu ra giá trị từ : “giữ nguyên”, “xóa hoàn toàn”.
-
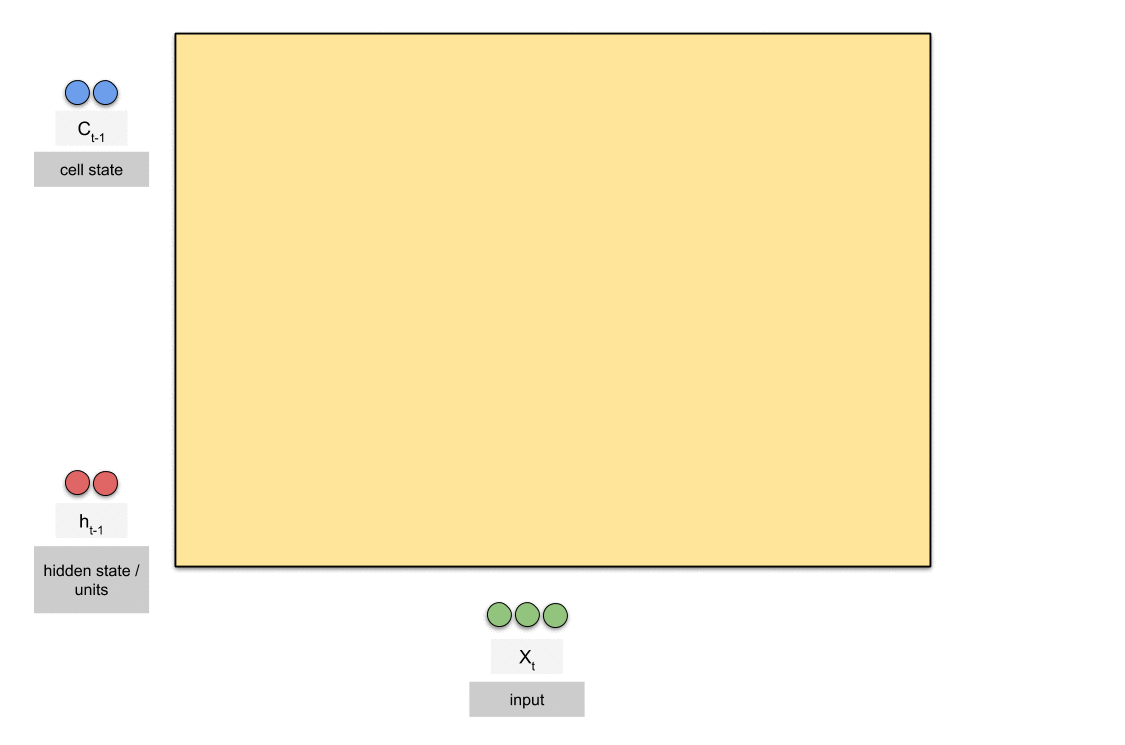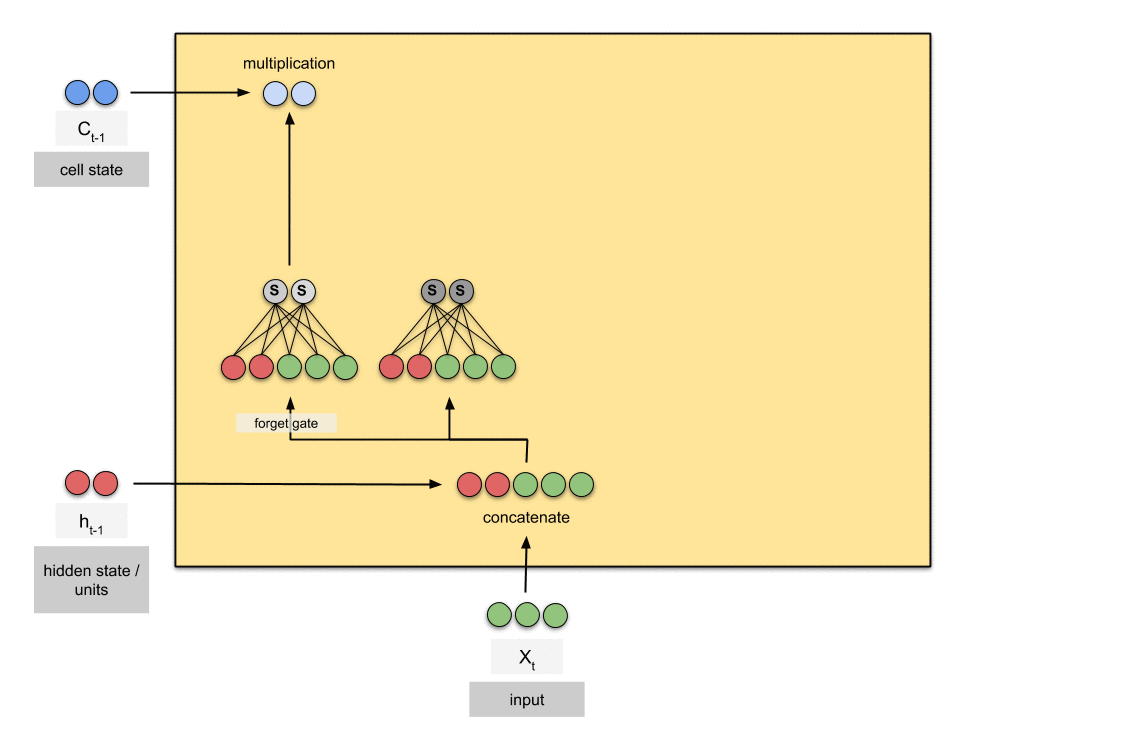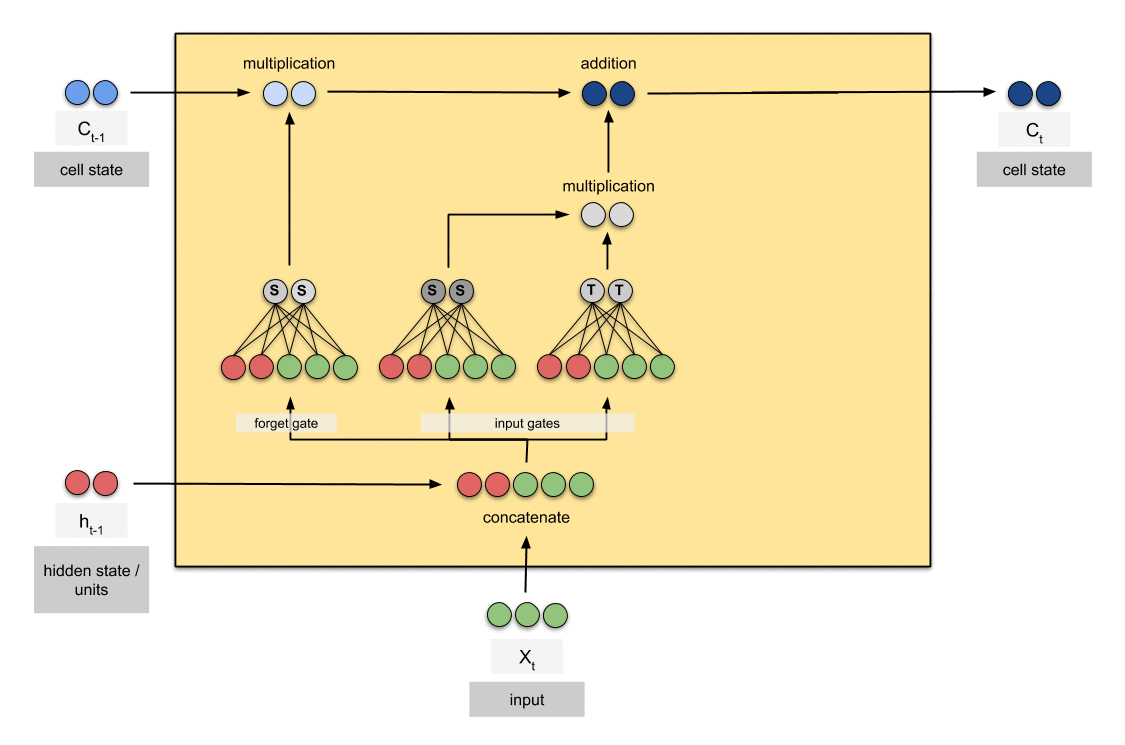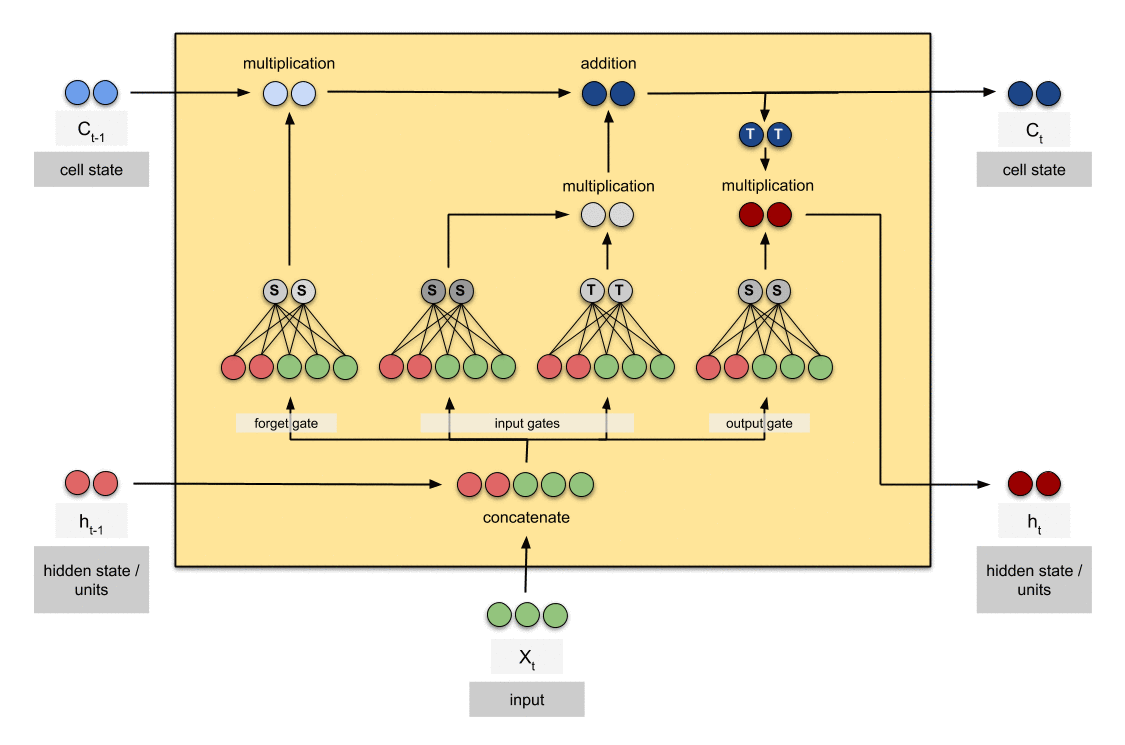
Input Gate & Candidate Cell State
Input Gate ( ): Lọc thông tin mới từ đầu vào () để lưu trữ vào cell state.
Candidate Cell State (): Tạo ra giá trị đề xuất cập nhật cho cell state, được “nén” trong khoảng bởi hàm tanh.
-
Cell State Mới
Phần “giữ lại” thông tin cũ theo tỷ lệ do forget gate quyết định.
Phần bổ sung thông tin mới, đảm bảo rằng chỉ dữ liệu có giá trị được lưu giữ.
-
Output Gate & Hidden State
Output Gate (): Quyết định phần nào của cell state sẽ được “trích xuất” ra làm hidden state.
Hidden State (): Kết quả cuối cùng được đưa đi làm đầu ra cho bước thời gian hiện tại, sau khi cell state được “đi qua” hàm tanh.
Tại Sao LSTM Hiệu Quả Hơn RNN? 🏆
| Yếu Tố | RNN | LSTM |
|---|---|---|
| Bộ nhớ | Chỉ hidden state (h_t) | Cell state (C_t) + hidden state (h_t) |
| Cập nhật thông tin | Ghi đè lên h_t mỗi bước | Điều chỉnh có chọn lọc qua cổng |
| Gradient | Dễ biến mất (vanishing gradient) | Được bảo toàn qua cell state |
LSTM giữ gradient ổn định hơn nhờ phép cộng trong cell state:
Phép cộng giúp gradient "chảy" qua cell state mà không bị suy giảm theo hàm phức tạp!
🎯 Kết Luận
Qua bài viết này, bạn đã có cái nhìn tổng quan về LSTM kiến trúc tiên tiến giúp xử lý các phụ thuộc dài hạn trong dữ liệu. So với RNN thông thường, LSTM cho phép lưu giữ thông tin quan trọng nhờ vào cell state và cơ chế cổng linh hoạt.
👉 Hãy chờ đón bài viết tiếp theo “Deep Dive – Phân Tích Chi Tiết LSTM: Giữ Thông Tin Lâu Dài, So Sánh với RNN và Công Thức Toán Học 🔍”! Trong bài sau, chúng ta sẽ đi sâu phân tích:
- Cách LSTM giữ thông tin lâu dài một cách hiệu quả: Phân tích chi tiết vai trò của từng cổng.
- So sánh RNN và LSTM: Tại sao LSTM vượt trội hơn trong việc lưu trữ thông tin dài hạn.
- Break down công thức toán học: Giải mã từng bước các công thức toán học của LSTM.
Cảm ơn bạn đã đồng hành cùng mình, hẹn gặp lại trong bài viết tiếp theo! 🚀
All rights reserved
