Tìm Hiểu Về Elasticsearch: Công Cụ Tìm Kiếm Hiệu Quả Cho Lập Trình Viên
Tìm Hiểu Về Elasticsearch: Công Cụ Tìm Kiếm Hiệu Quả Cho Lập Trình Viên
Khái Niệm Cơ Bản
Elasticsearch là một công cụ tìm kiếm (search engine) mạnh mẽ được xây dựng dựa trên nền tảng Apache Lucene. Nó cung cấp một hệ thống tìm kiếm phân tán, hỗ trợ phân tích dữ liệu thông qua giao diện HTTP, giúp các lập trình viên dễ dàng tích hợp và triển khai trong nhiều ứng dụng khác nhau.
Cơ Chế Hoạt Động Của Elasticsearch
Cấu Trúc Dữ Liệu
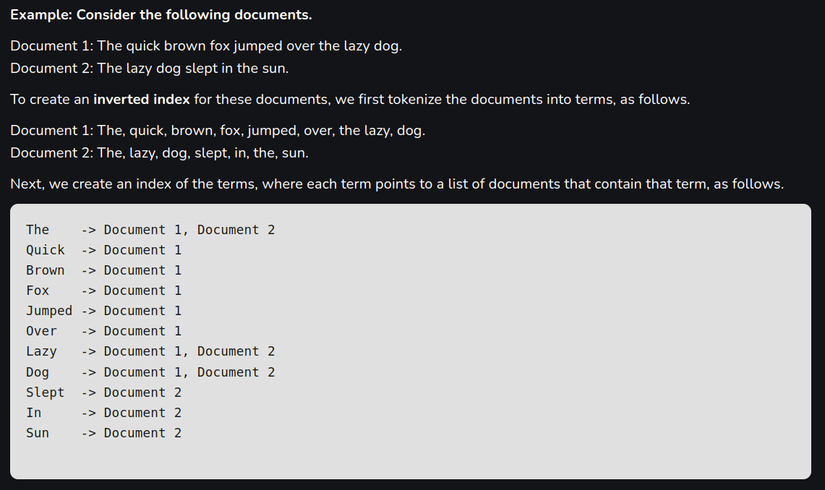
Elasticsearch sử dụng cơ chế đánh chỉ mục (indexing) gọi là inverted index – một khái niệm cốt lõi giúp tối ưu hóa hiệu suất tìm kiếm.
- Inverted index là cách tổ chức dữ liệu bằng cách đảo ngược từ nội dung sang danh sách các chỉ mục tương ứng. Cụ thể, mỗi từ (token) trong văn bản sẽ được ánh xạ đến các vị trí hoặc câu chứa từ đó thông qua một cấu trúc dữ liệu như hashmap.
- Ví dụ: Với câu "The quick brown fox jumped over the lazy dog", inverted index sẽ chia nhỏ câu thành từng từ riêng lẻ (tokenize) như "the", "quick", "brown",… Sau đó, mỗi từ được lưu kèm thông tin về vị trí xuất hiện của nó. Khi người dùng nhập từ khóa như "brown fox", hệ thống sẽ nhanh chóng tìm ra câu gốc dựa trên hashmap này.
- Ưu điểm: Cơ chế này giúp tăng tốc độ tìm kiếm toàn văn (full-text search), đồng thời cho phép tìm kiếm chính xác ngay cả khi người dùng chỉ nhập một chuỗi từ không liên tục, ví dụ "The brown fox" vẫn trả về kết quả phù hợp.
Cấu Trúc Kỹ Thuật
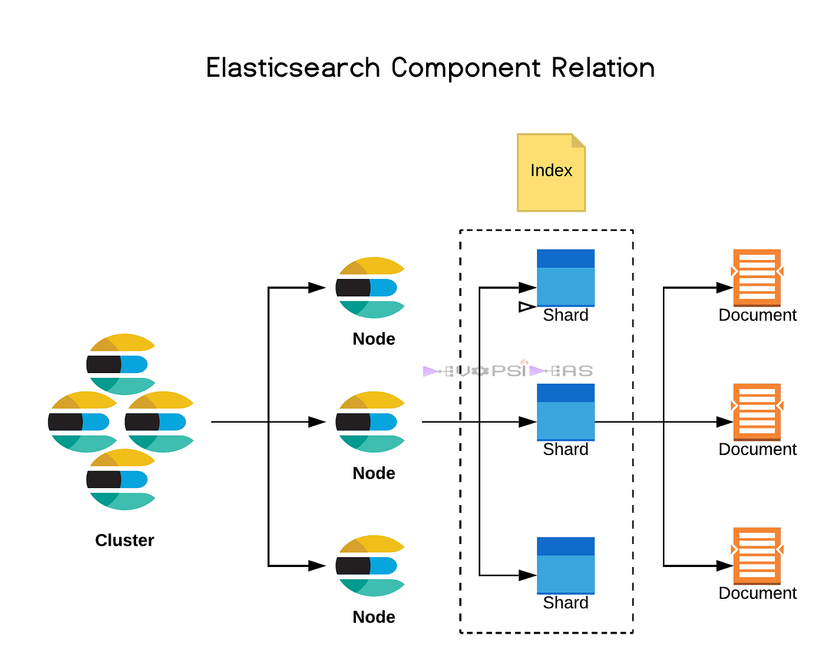
Hệ thống Elasticsearch được tổ chức theo mô hình phân tán với các thành phần chính:
- Cluster: Một hệ thống elasticsearch sẽ bao gồm các cụm. Một cụm bao gồm nhiều Node.
- Node: Mỗi Node là một phiên bản (instance) của Elasticsearch, đảm nhiệm các chức năng như đánh chỉ mục (indexing) và tìm kiếm (searching). Các Node giao tiếp với nhau để chia sẻ dữ liệu, phối hợp hoạt động và đảm bảo khả năng chịu lỗi cao (high availability).
- Có các loại Node chính: Master-eligible Nodes (quản lý cụm), Data Nodes (lưu trữ dữ liệu), và Coordinating Nodes (điều phối truy vấn).
- Cách lưu trữ dữ liệu:
- Document: Đơn vị cơ bản nhất, lưu dưới dạng đối tượng JSON chứa dữ liệu và siêu dữ liệu (metadata). Elasticsearch sẽ đánh index cho các field của Document từ đó dễ dàng tìm kiếm các document đó.
- Index: Tập hợp các Document có cấu trúc chung, tương tự như một database trong SQL. Mỗi Document trong Index được gắn với một giá trị
_idduy nhất. - Shards: Một Index được chia thành nhiều phần nhỏ gọi là Shard, mỗi Shard chứa một tập hợp Document. Shards có thể được lưu trên các Node khác nhau, giúp mở rộng hệ thống dễ dàng và tăng khả năng chịu lỗi.
- Replicas: Bản sao của Shards, đảm bảo dự phòng và nâng cao hiệu suất truy vấn.
Các Câu Lệnh Truy Vấn Thường Dùng
Tạo Index
Để khởi tạo một Index mới, bạn có thể sử dụng phương thức PUT hoặc POST:
POST: Tự động sinh ID cho Document mới.PUT: Chỉ định ID cụ thể cho Document.
// Tạo Index đơn giản
PUT /players
// Tạo Index và thêm dữ liệu
POST /players/_doc
{
"name": "John Stephenson",
"birthday": "1992-06-01",
"point": 470
}
Xóa Index
DELETE /players
Định Nghĩa Mapping
Mapping là cách định nghĩa cấu trúc lưu trữ dữ liệu, bao gồm các trường (field) và kiểu dữ liệu tương ứng, tương tự như schema trong cơ sở dữ liệu quan hệ.
- Dynamic Mapping: Khi thêm dữ liệu vào Index, Elasticsearch tự động tạo Mapping dựa trên kiểu dữ liệu được truyền vào.
- Tùy chỉnh Mapping: Bạn cũng có thể định nghĩa Mapping thủ công như sau:
PUT /players/_mapping
{
"properties": {
"name": {
"type": "text",
"analyzer": "standard",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"birthday": {
"type": "date",
"format": "yyyy-MM-dd"
},
"point": {
"type": "float"
}
}
}
Kiểm tra Mapping:
GET /players/_mapping
Tìm Kiếm
Elasticsearch hỗ trợ nhiều kiểu truy vấn linh hoạt:
- OR Query (Tìm kiếm với ít nhất một từ khớp):
POST /players/_search
{
"query": {
"match": {
"phrase": "juve help strike"
}
}
}
- AND Query (Yêu cầu tất cả từ khóa phải khớp):
POST /players/_search
{
"query": {
"match": {
"phrase": {
"query": "juve help strike",
"operator": "and"
}
}
}
}
- Tìm kiếm với số từ tối thiểu khớp:
POST /players/_search
{
"query": {
"match": {
"phrase": {
"query": "juve help strike",
"minimum_should_match": 2,
"max_expansions": 2
}
}
}
}
- Tìm kiếm trên nhiều trường:
POST /players/_search
{
"query": {
"multi_match": {
"query": "juve help strike",
"fields": ["name", "phrase"]
}
}
}
- Tìm kiếm theo cụm từ chính xác:
POST /players/_search
{
"query": {
"match_phrase": {
"phrase": "juve help strike"
}
}
}
Một Số Lưu Ý Khi Sử Dụng Elasticsearch
- Hạn chế trả về tất cả kết quả: Elasticsearch được thiết kế để trả về các kết quả hàng đầu (top results) thay vì toàn bộ Document khớp với truy vấn. Việc trả về tất cả có thể làm giảm hiệu suất.
- Kiểm soát kích thước Document: Mặc định, giới hạn
http.max_content_lengthlà 100MB. Dữ liệu vượt quá giới hạn này sẽ bị từ chối. Tuy có thể tăng lên tối đa 2GB, việc lưu trữ quá nhiều dữ liệu trong một Document không được khuyến khích vì ảnh hưởng đến hiệu suất hệ thống.
Kết Luận
Elasticsearch là một công cụ tìm kiếm mạnh mẽ và linh hoạt, phù hợp cho các ứng dụng yêu cầu truy vấn nhanh chóng và phân tích dữ liệu phức tạp. Hiểu rõ cách hoạt động và tối ưu hóa cấu hình của nó sẽ giúp bạn tận dụng tối đa tiềm năng trong các dự án phần mềm. Hãy bắt đầu thử nghiệm với các ví dụ trên để làm quen với công cụ này nhé!
Tài liệu tham khảo
All rights reserved
