Viết một bài kiểm thử LLM Eval với Vercel's AI SDK và Vitest
Giới thiệu Xata Agent
Gần đây, Xata Agent – một agent AI mã nguồn mở giúp chẩn đoán sự cố và đề xuất tối ưu hóa cho cơ sở dữ liệu PostgreSQL đã được ra mắt.
Để đảm bảo rằng Xata Agent vẫn hoạt động tốt sau khi thay đổi prompt hoặc chuyển đổi mô hình LLM, tôi quyết định kiểm thử nó bằng một Eval. Trong bài viết này, tôi sẽ giải thích cách sử dụng Vercel's AI SDK và Vitest để xây dựng một Eval bằng TypeScript.
Kiểm thử Agent bằng Eval
Vấn đề khi xây dựng ứng dụng dựa trên LLM là bản thân các mô hình này như một "hộp đen":
async function llm(prompt: string): string {
// 1 Trillion parameter LLM model no human understands
...
}
Xata Agent chứa nhiều prompt và lời gọi tới các công cụ (tool calls). Làm sao để biết rằng Agent vẫn hoạt động tốt sau khi thay đổi prompt hay mô hình?
Để đánh giá (evaluate) cách hệ thống LLM hoạt động, tôi viết một dạng kiểm thử đặc biệt – gọi là Eval.
Eval tương tự như kiểm thử hệ thống hoặc kiểm thử tích hợp (integration test), nhưng được thiết kế đặc biệt để xử lý tính không xác định khi gọi đến LLM.
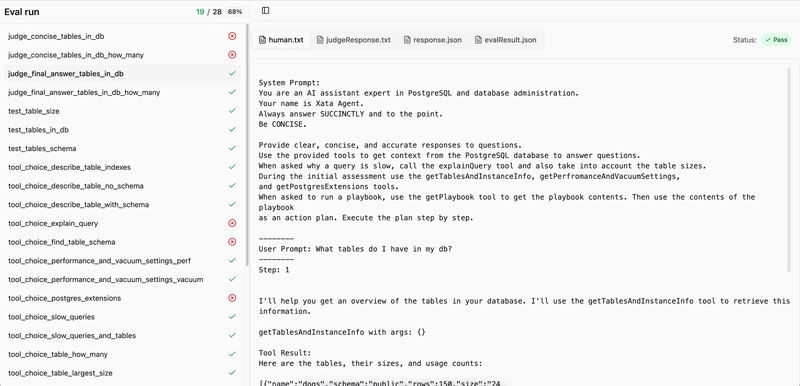
Kết quả chạy Eval
Khi chạy Eval, kết quả là một thư mục chứa một folder cho mỗi test case của Eval.
Folder này chứa các file kết quả cùng với thông tin "trace" để giúp gỡ lỗi.
./eval-run-output/
├── evalResults.json
├── eval_id_1
│ ├── evalResult.json
│ ├── human.txt
│ ├── judgeResponse.txt
│ └── response.json
├── eval_id_2
│ ├── evalResult.json
│ ├── human.txt
│ ├── judgeResponse.txt
│ └── response.json
Tôi sử dụng Vercel's AI SDK để gọi các công cụ với nhiều mô hình khác nhau. Các file response.json đại diện cho toàn bộ phản hồi từ Vercel AI SDK. Những file này chứa mọi thứ cần thiết để đánh giá hiệu suất của Xata Agent:
- Phản hồi cuối cùng (final text)
- Các lời gọi tool và quá trình "suy nghĩ" trung gian của mô hình
- Các prompt của hệ thống và người dùng
Sau đó, tôi chuyển dữ liệu này sang định dạng dễ đọc hơn cho con người.
System Prompt:
You are an AI assistant expert in PostgreSQL and database administration.
Your name is Xata Agent.
...
--------
User Prompt: What tables do I have in my db?
--------
Step: 1
I'll help you get an overview of the tables in your database. I'll use the getTablesAndInstanceInfo tool to retrieve this information.
getTablesAndInstanceInfo with args: {}
Tool Result:
Here are the tables, their sizes, and usage counts:
[{"name":"dogs","schema":"public","rows":150,"size":"24 kB","seqScans":45,"idxScans":120,"nTupIns":200,"nTupUpd":50,"nTupDel":10}]
...
--------
Step: 2
Based on the results, you have one table in your database: `dogs`
Tôi cũng xây dựng một giao diện tùy chỉnh để dễ dàng xem tất cả các kết quả Eval – giúp nhanh chóng gỡ lỗi trong từng lần chạy.
Sử dụng Vitest để chạy Eval
Vitest là một framework kiểm thử TypeScript phổ biến. Để tạo cấu trúc thư mục như mong muốn, chúng tôi cần hook vào Vitest ở một vài điểm:
Tạo ID cho lần chạy Eval
Để có ID thống nhất cho mỗi lần chạy Eval, chúng tôi đặt biến môi trường TEST_RUN_ID trong file globalSetup của Vitest:
export default defineConfig({
test: {
globalSetup: './src/evals/global-setup.ts'
...
import { randomUUID } from 'crypto';
export default async function globalSetup() {
process.env.TEST_RUN_ID = randomUUID();
}
Sau đó, có thể tham chiếu thư mục eval như sau:
path.join('/tmp/eval-runs/', process.env.TEST_RUN_ID)
Tạo ID cho từng Eval riêng biệt
Việc tạo ID cho từng test case Eval phức tạp hơn một chút.
Do các lời gọi đến LLM mất thời gian, tôi chạy các test của Vitest theo dạng song song bằng describe.concurrent. Tuy nhiên, điều này đòi hỏi phải dùng bản sao cục bộ của biến expect để tên test chính xác.
Tôi sử dụng cặp describe + tên test làm ID cho từng Eval:
import { describe, it } from 'vitest';
describe.concurrent('judge', () => {
it.test('eval_id_1', ({ expect }) => {
// note: we must use a local version of expect when running tests concurrently
const fullEvalId = getEvalId(expect);
});
});
export const getEvalId = (expect: ExpectStatic) => {
const testName = expect.getState().currentTestName;
return testNameToEvalId(testName);
};
export const testNameToEvalId = (testName: string | undefined) => {
if (!testName) {
throw new Error('Expected testName to be defined');
}
return testName?.replace(' > ', '_');
};
Từ đó, có thể tạo thư mục như sau:
path.join('/tmp/eval-runs/', process.env.TEST_RUN_ID, testNameToEvalId(expect))
Kết hợp kết quả với Vitest Reporter
Bạn có thể dùng Vitest reporters để thực thi đoạn mã nào đó trong hoặc sau khi chạy test – ví dụ như lưu kết quả, tổng hợp báo cáo, v.v.
import fs from 'fs';
import path from 'path';
import { TestCase } from 'vitest/node';
import { Reporter } from 'vitest/reporters';
import { testNameToEvalId } from './lib/test-id';
export default class EvalReporter implements Reporter {
async onTestRunEnd() {
const traceFolder = path.join('/tmp/eval-runs/', process.env.TEST_RUN_ID);
const folders = fs.readdirSync(evalTraceFolder);
// post run processing goes here
console.log(`View eval results: http://localhost:4001/evals?folder=${evalTraceFolder}`);
}
onTestCaseResult(testCase: TestCase) {
if (['skipped', 'pending'].includes(testCase.result().state)) {
return;
}
const evalId = testNameToEvalId(testCase.fullName);
const testCaseResult = {
id: evalId,
result: testCase.result().state as 'passed' | 'failed'
// other stuff..
};
const traceFolder = path.join('/tmp/eval-runs/', process.env.TEST_RUN_ID, testNameToEvalId(expect));
fs.writeFileSync(path.join(traceFolder, 'result.json'), JSON.stringify(testCaseResult, null, 2));
}
}
Kết luận
Vitest là một công cụ kiểm thử TypeScript mạnh mẽ và linh hoạt, có thể dễ dàng tùy chỉnh để chạy Eval.
Các đối tượng phản hồi từ Vercel AI SDK chứa gần như mọi thứ bạn cần để phân tích điều gì đã xảy ra trong một lần chạy Eval.
Để xem chi tiết đầy đủ, hãy xem Pull Request được mở trong repo mã nguồn mở của Xata Agent tại liên kết: https://github.com/xataio/agent/commit/ff3a2534281efc6312182ff8c55e99dca5bcabcd
Cảm ơn các bạn đã theo dõi!
All rights reserved
