Word Embedding & Word2Vec: Giải Mã Ma Thuật Giúp Máy Tính Hiểu Ngôn Ngữ! ✨
Bạn đã bao giờ tự hỏi làm thế nào Google Dịch có thể dịch thuật mượt mà, trợ lý ảo hiểu được yêu cầu của bạn, hay Netflix đề xuất bộ phim đúng ý bạn dựa trên mô tả? Bí mật đằng sau phần lớn những "phép màu" này nằm ở một kỹ thuật nền tảng trong Xử lý Ngôn ngữ Tự nhiên (NLP): Word Embedding.
1. Giai Điệu Mở Đầu: Khi Từ Ngữ Không Chỉ Là Ký Tự 🎶
Hãy tưởng tượng bạn đang nghe bài hát "Imagine" của John Lennon. Giai điệu và ca từ của nó không chỉ là những nốt nhạc và con chữ rời rạc, mà chúng gợi lên những hình ảnh, cảm xúc và ý niệm sâu sắc về hòa bình, về một thế giới tốt đẹp hơn. Ngôn ngữ con người cũng vậy, mỗi từ không chỉ đứng một mình mà còn mang trong mình sắc thái, ý nghĩa và mối liên hệ mật thiết với những từ khác.
Nhưng đối với máy tính, ban đầu, văn bản chỉ là một chuỗi các ký tự vô hồn. "Vua", "Nữ hoàng", "Hoàng tử", "Công chúa" chỉ là những dãy bytes khác nhau. Máy tính không hề "biết" rằng "Vua" và "Nữ hoàng" có liên quan đến hoàng gia, hay "Vua" có quan hệ với "Đàn ông" tương tự như "Nữ hoàng" với "Phụ nữ".
Đây chính là lúc Word Embedding bước vào sân khấu. Nó là một kỹ thuật biến đổi các từ ngữ thành các vector số (danh sách các con số) trong một không gian đa chiều. Điều kỳ diệu là, trong không gian vector này, các từ có ý nghĩa tương tự hoặc ngữ cảnh sử dụng giống nhau sẽ được đặt gần nhau.
Hãy coi Word Embedding như việc tạo ra một "bản đồ ý nghĩa" cho từ ngữ, nơi vị trí của mỗi từ phản ánh mối quan hệ ngữ nghĩa và ngữ pháp của nó với các từ khác.
2. Xây Dựng Mạng Nơ-ron "Dạy" Máy Tính Hiểu Từ 🧠
Làm thế nào chúng ta tạo ra những vector "thông minh" này? Một cách phổ biến là sử dụng Mạng Nơ-ron Nhân tạo (Neural Network). Ý tưởng cốt lõi rất trực quan:
"Một từ được định nghĩa bởi những từ xung quanh nó." (You shall know a word by the company it keeps - J.R. Firth)
Chúng ta sẽ huấn luyện một mạng nơ-ron thực hiện một nhiệm vụ dự đoán đơn giản liên quan đến ngữ cảnh của từ:
- Dữ liệu đầu vào: Rất nhiều văn bản (sách, báo, trang web...).
- Nhiệm vụ: Ví dụ, đưa cho mạng nơ-ron một từ (từ mục tiêu) và yêu cầu nó dự đoán các từ xuất hiện gần đó (từ ngữ cảnh), hoặc ngược lại, đưa các từ ngữ cảnh và yêu cầu dự đoán từ mục tiêu.
- Kiến trúc mạng (đơn giản hóa):
- Lớp Input: Biểu diễn từ mục tiêu (thường là dạng one-hot encoding ban đầu - một vector dài toàn số 0, chỉ có số 1 ở vị trí tương ứng với từ đó).
- Lớp Ẩn (Embedding Layer): Đây là trái tim của quá trình. Lớp này có số nơ-ron ít hơn nhiều so với kích thước từ điển. Trọng số kết nối giữa lớp Input và lớp Ẩn chính là thứ chúng ta muốn học - đó chính là các vector nhúng (word embeddings)! Kích thước của lớp ẩn này (ví dụ: 50, 100, 300 chiều) chính là số chiều của vector nhúng.
- Lớp Output: Dự đoán các từ ngữ cảnh (sử dụng hàm Softmax để ra xác suất cho mỗi từ trong từ điển).
- Huấn luyện: Mạng nơ-ron sẽ điều chỉnh các trọng số (bao gồm cả các vector nhúng ở lớp ẩn) thông qua quá trình lan truyền ngược (backpropagation) để tối thiểu hóa lỗi dự đoán (ví dụ: làm cho xác suất dự đoán đúng từ ngữ cảnh càng cao càng tốt).
Điều kỳ diệu: Sau khi huấn luyện xong, chúng ta không thực sự quan tâm đến khả năng dự đoán của mạng nơ-ron nữa. Thứ quý giá nhất mà chúng ta thu được chính là ma trận trọng số của lớp ẩn – đó là tập hợp các vector nhúng từ cho toàn bộ từ điển! Các vector này đã "học" được các mối quan hệ ngữ nghĩa từ dữ liệu văn bản khổng lồ.
3. Trực Quan Hóa & Kiểm Chứng: "Nhìn" Vào Không Gian Ý Nghĩa 🗺️
Các vector nhúng thường có hàng trăm chiều, làm sao chúng ta "thấy" được chúng? Chúng ta có thể sử dụng các kỹ thuật giảm chiều dữ liệu như t-SNE hoặc PCA để chiếu các vector này xuống không gian 2D hoặc 3D và vẽ chúng ra.
Khi đó, bạn sẽ thấy những điều thú vị:
- Các từ đồng nghĩa hoặc có liên quan (ví dụ: "chó", "mèo", "ngựa") sẽ tụ lại thành cụm.
- Các quốc gia ("Việt Nam", "Nhật Bản", "Pháp") sẽ gần nhau, các thành phố ("Hà Nội", "Tokyo", "Paris") cũng vậy và có thể thấy mối quan hệ song song giữa quốc gia và thủ đô của nó.
Một cách kiểm chứng kinh điển khác là thực hiện các phép toán trên vector:
vector('Vua') - vector('Đàn ông') + vector('Phụ nữ') ≈ vector('Nữ hoàng')
Hoặc:
vector('Hà Nội') - vector('Việt Nam') + vector('Nhật Bản') ≈ vector('Tokyo')
Những kết quả này cho thấy các vector nhúng không chỉ nhóm các từ tương tự lại mà còn nắm bắt được các mối quan hệ ngữ nghĩa và tương tự phức tạp hơn. Chúng ta cũng có thể dễ dàng tìm các từ gần nghĩa nhất với một từ cho trước bằng cách tính toán độ tương đồng cosine giữa các vector.
4. Tóm Tắt Ý Chính (Trước Khi Đến Với Word2Vec) 📝
- Vấn đề: Máy tính cần biểu diễn số học cho từ ngữ để xử lý.
- Giải pháp: Word Embedding (Nhúng Từ) - biểu diễn mỗi từ bằng một vector dày đặc (dense vector) các con số.
- Cách tạo ra: Huấn luyện mạng nơ-ron thực hiện nhiệm vụ dự đoán từ trong ngữ cảnh. Vector nhúng chính là trọng số được học của lớp ẩn.
- Kết quả: Các vector nhúng nắm bắt được mối quan hệ ngữ nghĩa và ngữ pháp giữa các từ. Các từ tương tự có vector gần nhau trong không gian.
- Kiểm chứng: Trực quan hóa (t-SNE, PCA) và thực hiện phép toán tương tự trên vector.
Giờ thì bạn đã hiểu ý tưởng cốt lõi của Word Embedding rồi đấy! Tiếp theo, chúng ta sẽ tìm hiểu về Word2Vec, một trong những bộ công cụ/thuật toán cụ thể và cực kỳ phổ biến để tạo ra các word embedding chất lượng cao một cách hiệu quả.
5. Word2Vec: Ngôi Sao Sáng Của Làng Word Embedding ⭐
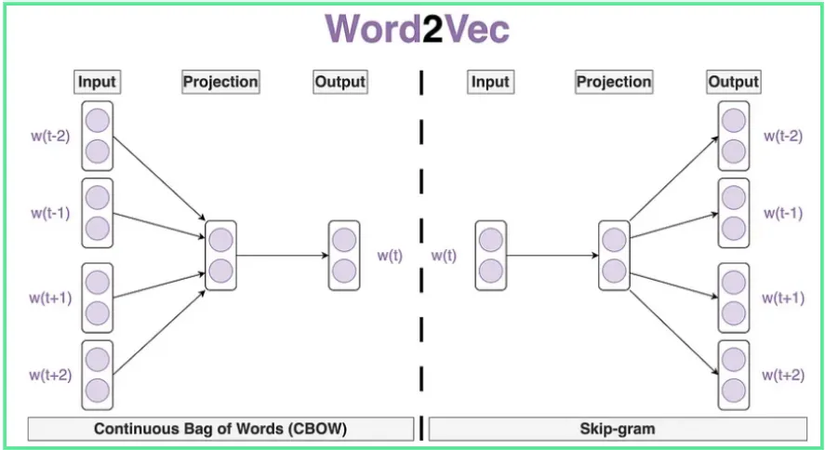
Word2Vec không phải là một kiến trúc đơn lẻ mà là một bộ công cụ được phát triển bởi các nhà nghiên cứu tại Google (Tomas Mikolov và cộng sự) vào năm 2013. Nó cung cấp hai kiến trúc chính để học word embedding hiệu quả:
-
CBOW (Continuous Bag-of-Words):
- Ý tưởng: Dự đoán từ mục tiêu (target word) dựa vào các từ ngữ cảnh xung quanh nó (context words).
- Cách hoạt động (đơn giản): Lấy vector nhúng của các từ ngữ cảnh, kết hợp chúng lại (thường là lấy trung bình hoặc tổng) và dùng vector kết hợp này để dự đoán ra từ mục tiêu ở giữa.
- Đặc điểm: Hoạt động tốt và nhanh hơn với các tập dữ liệu lớn, hiệu quả hơn cho các từ xuất hiện thường xuyên.
-
Skip-gram:
- Ý tưởng: Ngược lại với CBOW, Skip-gram sử dụng từ mục tiêu để dự đoán các từ ngữ cảnh xung quanh.
- Cách hoạt động (đơn giản): Lấy vector nhúng của từ mục tiêu và dùng nó để cố gắng dự đoán từng từ trong cửa sổ ngữ cảnh của nó.
- Đặc điểm: Hoạt động tốt hơn với các tập dữ liệu nhỏ, và đặc biệt hiệu quả trong việc học biểu diễn tốt cho các từ hiếm gặp.
Cả CBOW và Skip-gram đều dựa trên ý tưởng học embedding thông qua nhiệm vụ dự đoán ngữ cảnh, nhưng cách tiếp cận hơi khác nhau. Skip-gram thường được ưa chuộng hơn vì chất lượng embedding tốt hơn cho nhiều tác vụ, mặc dù có thể chậm hơn CBOW một chút.
6. Tăng Tốc Huấn Luyện: Negative Sampling - Bí Quyết Hiệu Quả 🚀
Một thách thức lớn khi huấn luyện các mô hình như trên là lớp Output. Nếu từ điển của bạn có hàng chục ngàn, thậm chí hàng triệu từ, việc tính toán hàm Softmax trên toàn bộ từ điển ở mỗi bước huấn luyện là cực kỳ tốn kém!
Đây là lúc Negative Sampling (Lấy Mẫu Âm) xuất hiện như một vị cứu tinh. Thay vì cập nhật trọng số cho tất cả các từ ở lớp Output, Negative Sampling đơn giản hóa bài toán:
- Lấy một cặp (từ mục tiêu, từ ngữ cảnh thực tế): Đây là một mẫu "dương" (positive sample). Chúng ta muốn mô hình dự đoán đây là một cặp hợp lệ (ví dụ: đầu ra là 1).
- Lấy một vài từ ngẫu nhiên từ từ điển: Chọn K từ không phải là từ ngữ cảnh thực tế của từ mục tiêu. Ghép chúng với từ mục tiêu để tạo thành các mẫu "âm" (negative samples). Chúng ta muốn mô hình dự đoán đây là các cặp không hợp lệ (ví dụ: đầu ra là 0).
- Huấn luyện: Mô hình chỉ cần học cách phân biệt giữa cặp (từ mục tiêu, từ ngữ cảnh thực tế) và các cặp (từ mục tiêu, từ ngữ cảnh ngẫu nhiên/sai). Nhiệm vụ trở thành một loạt các bài toán phân loại nhị phân độc lập, dễ dàng và nhanh hơn rất nhiều so với việc tính Softmax trên toàn bộ từ điển.
Số lượng mẫu âm (K) thường nhỏ (ví dụ: 5-20), giúp giảm đáng kể khối lượng tính toán mà vẫn giữ được chất lượng embedding tốt. Negative Sampling là một trong những yếu tố then chốt giúp Word2Vec trở nên thực tế và hiệu quả trên các tập dữ liệu khổng lồ.!
Lời Kết
Word Embedding và Word2Vec đã tạo ra một cuộc cách mạng trong lĩnh vực Xử lý Ngôn ngữ Tự nhiên. Chúng cung cấp một cách hiệu quả để biểu diễn ý nghĩa của từ ngữ dưới dạng số học, mở đường cho hàng loạt ứng dụng AI tiên tiến mà chúng ta thấy ngày nay. Từ việc hiểu các mối quan hệ tinh tế giữa các từ đến việc xây dựng các hệ thống phức tạp như máy dịch hay chatbot, word embedding đóng vai trò là viên gạch nền tảng không thể thiếu.
Hy vọng bài viết này đã giúp bạn "giải mã" được phần nào ma thuật đằng sau Word Embedding và Word2Vec một cách rõ ràng và dễ hiểu. Đây mới chỉ là bước khởi đầu trong hành trình khám phá thế giới NLP đầy thú vị. Hãy tiếp tục tìm tòi, thử nghiệm và đừng ngần ngại đặt câu hỏi nhé!
All rights reserved
